一、概念辨析
线性表的插入删除需要移动大量的元素,因此引入链表(本文讨论单链表)的概念,链表元素之间通过“链”来链接,因此插入和删除时不需要大量的移动元素,而只需要改变“链”的关系即可。
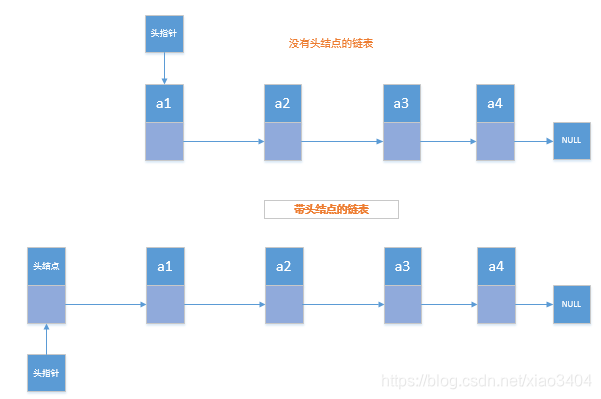
头指针:通常使用“头指针”来标识一个链表,如单链表L,头指针为NULL的时表示一个空链表。链表非空时,头指针指向的是第一个结点的存储位置。
头结点:在单链表的第一个结点之前附加一个结点,称为头结点。头结点的Data域可以不设任何信息,也可以记录表长等相关信息。若链表是带有头结点的,则头指针指向头结点的存储位置。
[注意]无论是否有头结点,头指针始终指向链表的第一个结点。如果有头结点,头指针就指向头结点。
二、引入头结点的优势
优势1:第1个位置的插入、删除更加方便,带来操作上的统一
例如:head为头指针,x待插入(后插方式)的新结点,p为指向任意结点的指针。
对于带头结点的插入到第一个位置的代码:
//p = head;
x->next = head->next;
head->next = x;
插入其他结点
x->next = p->next;
p->next = x;
若令p=head,则带有头结点的链表,可以实现代码复用,减少分支。
对于不带头结点的插入到第一个位置的代码:
x->next = head->next;
head = x;//这里有差异
插入其他结点
x->next = p->next;
p->next = x;
因此,不带头结点的链表,插入第一个结点时,需要特殊处理,删除操作类似。
优势2:统一空表和非空表的处理
若使用头结点,无论表是否为空,头指针都指向头结点,也就是*LNode类型,对于空表和非空表的操作是一致的。
若不使用头结点,当表非空时,头指针指向第1个结点的地址,即*LNode类型,但是对于空表,头指针指向的是NULL,此时空表和非空表的操作是不一致的。
所以单链表一般为带头结点的单链表。
————————————————
版权声明:本文为CSDN博主「CodeForCoffee」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_24118527/article/details/81317410
