在pandas中有两类非常重要的数据结构,即序列Series和数据框DataFrame。Series类似于numpy中的一维数组,除了通吃一维数组可用的函数或方法,而且其可通过索引标签的方式获取数据,还具有索引的自动对齐功能;DataFrame类似于numpy中的二维数组,同样可以通用numpy数组的函数和方法.
0.安装方法:
windows:pip install pandas
Mac:pip3 install pandas
1.导入Pandas模块
import pandas as pd
2.Pandas的基础类型1——Series
2.1 创建一个Series类型的数据
Series()里直接填一个由数字组成的列表
import pandas as pd
data = pd.Series([1,2,3,4])
print(data)
0 1
1 2
2 3
3 4
索引 数据
2.2获取值和索引
print(data.values) #获取Series数据的值
print(data.index) #获取Series数据的索引
[1 2 3 4]
RangeIndex(start=0, stop=4, step=1)
2.3创建特殊的索引值
data = pd.Series([1,2,3,4],index = ['a',"b","c","d"])
print(data)
a 1
b 2
c 3
d 4
索引 数据
特别的,若要修改索引值,可以:
data = pd.Series([1,2,3,4],index = ['a',"b","c","d"])
data.index = ["A",'B','C',"D"]
print(data)
A 1
B 2
C 3
D 4
索引 数据
2.4获取Series数据的长度
print(len(data))
4
2.5获取数组中某个数据
单个:
print(data["A"])
1
多个:
方法一:列表法(用于间断的取)
print(data[["A",'B']])
A 1
B 2
方法二:切片法(用于连续的取)
print(data[0:2])
在这里插入代码片
A 1
B 2
2.6计算重复元素出现的次数
data = pd.Series([1,2,3,1,2,2,3,3,3,1])
print(data.value_counts())
3 4
2 3
1 3
数字 次数
2.7判断某个索引值是否存在
data = pd.Series([1,2,3,4],index=["a","b","c","d"])
print("a" in data)
True
返回结果说明a在索引值里面
2.8从字典创建一个Series类型的数据
我们可以发现,字典结构与本结构很相似,key value对应索引 数据
我们可以利用下面的方式建立series
dict_data ={
"pengpeng":100,
"liaoming":90,
"mingming":80
}
data = pd.Series(dict_data)
print(data)
pengpeng 100
liaoming 90
mingming 80
key value
索引 数据
2.9检测哪些数据缺失
print(data.isnull()) #检查数据空
print(data.notnull()) #检查数据非空
pengpeng False
liaoming False
mingming False
dtype: bool
pengpeng True
liaoming True
mingming True
dtype: bool
2.10数组运算
print(data*2)
pengpeng 200
liaoming 180
mingming 160
2.11设定Series对象的name和索引名称
data.name = " name"
data.index.name = "source"
print(data)
source
pengpeng 100
liaoming 90
mingming 80
Name: name, dtype: int64
3.Pandas的基础类型2——DataFrame
3.1创建一个DataFrame类型的数据
dict_data = {
"name":["xiaoming","ningning","huahua"],
"score":[98,97,99],
"gender":["f","m","f"]
}
data = pd.DataFrame(dict_data)
print(data)
dict_data = {
"name":["xiaoming","ningning","huahua"],
"score":[98,97,99],
"gender":["f","m","f"]
}
data = pd.DataFrame(dict_data)
print(data)
3.2修改优化方法
指定DataFrame数据的列顺序:
data = pd.DataFrame(dict_data,columns=["gender","name","score"])
print(data)
gender name score
0 f xiaoming 98
1 m ningning 97
2 f huahua 99
获取DataFrame数据的列名称:
Index(['gender', 'name', 'score'], dtype='object')
指定DataFrame数据的索引值
data = pd.DataFrame(dict_data,columns=["gender","name","score"],index=["a","b","c"])
print(data)
gender name score
a f xiaoming 98
b m ningning 97
c f huahua 99
3.3获取DataFrame数据中的某一列数据
获取DataFrame数据中的某一列数据
print(data["name"]) #获取DataFrame数据中的某一列数据
print(data.name)
a xiaoming
b ningning
c huahua
Name: name, dtype: object
获取DataFrame数据中的某一行数据
print(data.iloc[0]) #根据行编号
print(data.loc["a"]) #根据行索引
特别的:
data1 = data["score"]
data1[0] = 40
print(data)
注意!切片得到的数据对应的还是原始数据 任何修改都会反映到原始数据上
gender name score
a f xiaoming 40
b m ningning 97
c f huahua 99
若想要不影响原来数据,用data['score'].copy()
3.4修改DataFrame数据中的某一列数据
data["score"] = 30 #修改全部为一个数字
print(data)
data["score"] = range(60,63) #range
print(data)
score = pd.Series([100,90,80],index=["c","b","a"])
#传入Series类型修改DataFrame数据中的某一列数据
data["score"] = score
print(data)
gender name score
a f xiaoming 40
b m ningning 97
c f huahua 99
gender name score
a f xiaoming 30
b m ningning 30
c f huahua 30
gender name score
a f xiaoming 60
b m ningning 61
c f huahua 62
gender name score
a f xiaoming 80
b m ningning 90
c f huahua 100
3.5删除DataFrame数据中的某一列数据
del data["score"]
print(data)
gender name
a f xiaoming
b m ningning
c f huahua
3.6根据新的索引重新排列数据
data = data.reindex(["c","b","a"])
print(data)
gender name
c f huahua
b m ningning
a f xiaoming
3.7缺失数据处理
将缺失位置填0:
data = data.reindex(["c","b","a",'d'],fill_value=0)
print(data)
gender name
c f huahua
b m ningning
a f xiaoming
d 0 0
将缺失位置通过插值法计算并补上内容
data = data.reindex(["c","b","a",'d'],method="ffill") #从前面数据计算插值
print(data)
data = data.reindex(["c","b","a",'d'],method="bfill") #从后面数据计算插值
print(data)
丢弃数据:
print(data.dropna()) #扔掉包含缺失的数据(NaN)的行
print(data.dropna(how="all")) #扔掉全部都是缺失的数据(NaN)的行
填充数据:
print(data.fillna(0)) #填充所有缺失数据为一个值
print(data.fillna({"gender":"m","name":"liuliu",'score':99})) #按列填充缺失数据为不同值
gender name score
c f huahua 100.0
b m ningning 90.0
a f xiaoming 80.0
d 0 0 0.0
gender name score
c f huahua 100.0
b m ningning 90.0
a f xiaoming 80.0
d m liuliu 99.0
3.8删除某一行数据**
data = data.drop("d")
print(data)
gender name score
c f huahua 100.0
b m ningning 90.0
a f xiaoming 80.0
3.9筛选数据
判断筛选:
print(data["score"]>=90)
print(data[data["score"]>=90]) #筛选数据
c True
b True
a False
Name: score, dtype: bool
gender name score
c f huahua 100.0
b m ningning 90.0
从列表筛选:
slist = [90,100] #列表筛选数据
print(data[data["score"].isin(slist)])
gender name score
c f huahua 100.0
b m ningning 90.0
3.10利用groupby对数据进行分组运算
data = pd.DataFrame({ #groupby
"tag_id":["a","a","c","b","b","c"],
"count":[10,12,20,30,10,50]
})
data1 = data.groupby("tag_id")
print(data1.sum())
tag_id
a 22
b 40
c 70
print(data1.mean())
tag_id
a 11
b 20
c 35
3.11.数据排序
按索引名称排列
print(data.sort_index()) #按照索引升序排列
print(data.sort_index(ascending=False)) #按照索引降序排列
gender name score
a f xiaoming 80.0
b m ningning 90.0
c f huahua 100.0
gender name score
c f huahua 100.0
b m ningning 90.0
a f xiaoming 80.0
按某一列的数据进行排序
print(data.sort_values(by="score")) #按列方式正序排序
gender name score
a f xiaoming 80.0
b m ningning 90.0
c f huahua 100.0
3.12数据汇总
print(data.sum())
gender fmf
name huahuaningningxiaoming
score 270
dtype: object
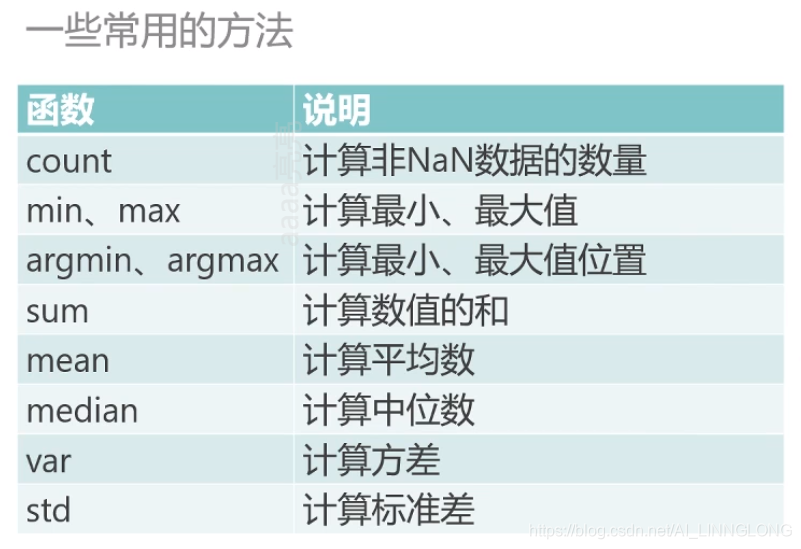
4.pandas层次化索引
data = pd.Series(
np.random.randint(1,6,size=4), #1到6 4个数
index=[
["a","b","c","d"],
[1,2,3,4]
]
)
print(data)
a 1 5
b 2 3
c 3 3
d 4 5
索引 索引 数据
dtype: int32
5.pandas数据合并
连接方式:
data1 = pd.DataFrame({
"key":["a","b","a","c","b","d"],
"data1":[1,2,3,4,5,6]
})
data2 = pd.DataFrame({
"key":["a","b","c"],
"data2":[7,8,9]
})
print(pd.merge(data1,data2)) #不指定连接方式 共有的才输出
print(pd.merge(data1,data2,how="outer")) #有的都输出
print(pd.merge(data1,data2,how="left"))
print(pd.merge(data1,data2,how="right"))
key data1 data2
0 a 1 7
1 a 3 7
2 b 2 8
3 b 5 8
4 c 4 9
key data1 data2
0 a 1 7.0
1 a 3 7.0
2 b 2 8.0
3 b 5 8.0
4 c 4 9.0
5 d 6 NaN
key data1 data2
0 a 1 7.0
1 b 2 8.0
2 a 3 7.0
3 c 4 9.0
4 b 5 8.0
5 d 6 NaN
key data1 data2
0 a 1 7
1 a 3 7
2 b 2 8
3 b 5 8
4 c 4 9
指定连接的列名称
print(pd.merge(data1,data2,on="key"))
key data1 data2
0 a 1 7
1 a 3 7
2 b 2 8
3 b 5 8
4 c 4 9
分别指定连接的列名称
data1 = pd.DataFrame({
"1key":["a","b","a","c","b","d"],
"data1":[1,2,3,4,5,6]
})
data2 = pd.DataFrame({
"2key":["a","b","c"],
"data2":[7,8,9]
})
print(pd.merge(data1,data2,left_on='1key',right_on="2key"))
1key data1 2key data2
0 a 1 a 7
1 a 3 a 7
2 b 2 b 8
3 b 5 b 8
4 c 4 c 9
6.pandas文件存取
6.1读取csv:
data = pd.read_csv('1.csv')
print(data)
data = pd.read_csv('1.csv',header=None) #不要标题行
print(data)
data = pd.read_csv('1.csv',names=["name",'gender','score']) #自定义标题行
print(data)
data = pd.read_csv('1.csv',names=["name",'gender','score'],index_col="name") #指定索引列
print(data)
data = pd.read_csv('1.csv',names=["name",'gender','score'],index_col="name",sep=",") #指定分隔符
print(data)
pandas会自动处理缺失的数据,相当智能。
6.2储存为csv
data.to_csv("1.csv") #储存为csv
6.3读取Excel
安装xlrd模块
Windows:pip install xlrd
Mac:pip3 install xlrd
file = pd.ExcelFile("2.xlsx")
data = file.parse("sheet1")
print(data)
参考链接
https://pandas.pydata.org/pandas-docs/stable/getting_started/basics.html#basics-compare
以上便是
数据分析的第二部分内容
后续将会持续更新excel,ppt,爬虫,人工智能
等相关内容,敬请关注
