软件设计师 程序语言基础知识
习题集中在20—22题,48—50题
1.源程序:输入给编译器的其实就是字符串
VAR X,Y,Z:real; //声明语句
X:=Y+Z60; //可执行语句
2.词法分析:预处理:删除无用的空白字符、回车符及其他非实质性字符和注释
功能:从前到后逐个字符扫面源程序,根据语言的词法规则(即描述的基本字符构成符号/单词的书写规则)识别出一个个符号/单词。
VAR id1,id2,id3:real;
id1:=id2+id360;
3.语法分析:根据语言的语法规则(由单词/符号构成语法成分的规则),将单词/符号序 列分解成各类语法成分,如表达式、语句、函数和程序等。语法树、中序遍历。
4.语义分析:语法正确的程序并不能保证语义一定正确!功能:检查源程序是否包含语义错误,并收集类型信息供后面的代码生成阶段使用。
5.中间代码生成:功能:依据语言的语义规则,生成与具体的机器无关的中间代码。常用形式有后缀式、三元式、四元式和树等。

中间代码形式有:
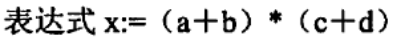
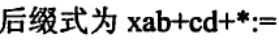
先写所有操作数,写完再向里填操作符


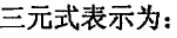



6.代码优化:功能:依据程序的等价变换规则,对中间代码从时间和空间化上进行优。

7.目标代码生成:功能:把中间代码变换成特定机器上的绝对指令代码、可重定位的指令代码或汇编指令代码。

8.目标代码
其中中间代码生成和代码优化可以省略
9.符号表管理:作用:记录源程序中各个符号的必要信息,如标识符及其属性,以辅助语义的正确性检查和代码生成。
10.出错处理:作用:发现源程序中的各种错误并进行相应的提示
源程序的错误类型:
语法错误:语言结构上的使用错误,编译时可发现。如:单词拼写错(1/i、0/o、;/;等)、标点符号错、表达式中缺少操作数、括号不匹配等。
静态语义错误:编译时就可以确定的语义错误。包括:标识符未声明、重复声明、条件表达式不是布尔类型、运算符的分量类型不相容、switch语句的分支常量表达式重复、枚举类型的元素重复、结构类型的域名重复等。
float x,y; int z; z = x+y;
动态语义错误:程序运行时才确定的语义错误。
除零溢出错误:
x/(y-i); //当y = i时
数组下标越界:
int a[5]; a[5] =0;
无效指针:
int* p; p =NULL; *p = 3;
编译原理:
文法和语言的形式描述:
语法规则:语法结构组成的规则
语义规则:语法结构含义及使用的规则


连接:中间的点可省略
闭包:0个以上的字符连接构成的所有字符串的全体
方幂:把这个字符串自身连接n次
正则闭包:去掉闭包中的空字,正则闭包里面,字符串的长度至少为1


{a,b}+={a,b,aa,ab,bb,ba,aaa,……}
{a,b}*={,a,b,aa,ab,bb,ba,aaa,……}
文法和语言的形式描述:


G=({S, B}, {a, b, c}, {SaBSc | abc, BaaB, Bbbb}, S)
VN:非终结符:语法单位,相当于变量,除终结符外的都是非终结符,大写
VT:终结符:不单独出现在左边的,小写
P:产生式:加工流程
S:程序:最大的变量
第一个产生式左边的是开始符号
文法分类:

S–>aBSc | abc, Ba–>aB, Bb–>bb
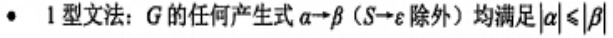
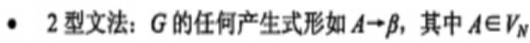
T–>XaaY X–>YY | b Y–>XbX | a
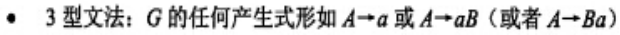
S–>aA A–>bB B–>cS | c 右线性
T–>Ac A–>Bb B–>Sa | a 左线性
0型(短语文法):左部至少有一个符号,右部可以为0个字符
1型(上下文有关文法):左边长度不能大于右边,除了开始符号
2型(上下文无关文法):左边只有一个非终结符,右边任意
3型正规/则文法(右线性,左线性):用来描述词法规则


S–>XaaY X–>YY | b Y–>XbX | a
S–>XaaY–>YYaaY–>aYYaaY–>aaaaY–>aaaaa(最左推导)
S–>XaaY–>Xaaa–>YYaaa–>Yaaaa–>aaaaa(最右推导)
S-±>aaaaa(S可推导出aaaaa)
直接推导:一次只换一个非终结符,若含S,+换* S-*->aaaaa
最左推导、最右推导(规范推导)
直接归约、归约、规范归约(规范推导的逆过程,与最右推导对应)
句型:S–>XaaY–>YYaaY–>aYYaaY–>aaaaY–> 所有字符串都叫句型
句子:aaaaa 只有终结符
语言:从文法出发,能写出所有程序的主体
正规(表达)式:
正规式是由终结符和运算符组成的式子。每个正规式表示一个集合(正规集)。
运算符
| 或
- 闭包(零或多次自重复连接)
· 连接(可省略)
优先级 -
· > |
可用圆括号改变优先级

ab {ab}
a|b {a,b}
a* {空,a,aa,aaa,……}
(a|b)* {空,a,b,aa,bb,ab,ba,aaa,……}
a(a|b)* {aa,ab,aaa,abb,aab,aba,……}
有限自动机:确定的有限自动机DFA、不确定的有限自动机NFA
与图、矩阵等价,几条弧对几个函数
DFA确定的有限自动机:一个状态是不一个符号后,到达的状态是唯一的,输入的不是空字
NFA不确定的有限自动机:同一个符号到的状态不同,输入的可能有空字
算符优先文法是一种自下而上分析文法,其文法的特点是文法的产生式中不含两个相邻的非终结符 。自上而下的分析方法,通常要求文法的产生式不含左递归。,不允许含有S–>S……
二义文法:S–>E+E|E*E|id,因为+,*优先级不确定
先推导出来的后计算
算符优先文法的语法分析通常采用优先矩阵,优先矩阵给出了该文法中各个终结符之间的优先关系:大于、小于、等于、无关系。
画树,先推导出来的优先级低,后计算
A→…ab… 或A→…aBb… ,则a = b 相当于左右括号
A→…aB…且Bb…或BCb…时,则a<b
A→…Bb…且B…a或B…aC时,则a>b
句型(Sd(T)db)的语法树:

短语:从一个非终结符号推导出来的所有叶子,S、(T)、Sd(T) 、b 、Sd(T)db、 S自己
直接短语:从一个非终结符号直接推导出来的所有叶子,就长一次
句柄:最左边的直接短语
素短语:它是短语,至少含一个终结符,且除它自身之外不再含任何更小的素短语 b、(T)
最左素短语:最左边的素短语
NFA→DFA:子集法
-closure(I)空字闭包:I 中的任何状态经过若干条(包括0条) 空字弧所到达的状态的集合。
Ia:I 中的任何状态经过若干条(包括0条) 空字弧和一条 a 弧所到达的状态的集合
|I Ia Ib
{0} {1,2,4} {}
{1,2,4} {5} {2,3,4}
{5} {} {}
{2,3,4} {5} {2,3,4}
{0}–Q0
{1,2,4}–Q1
{5}–Q2
{2,3,4}–Q3
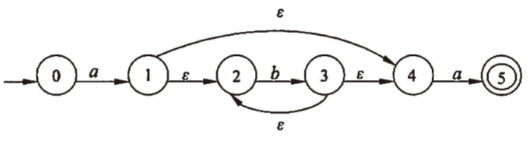
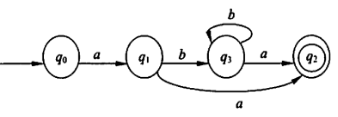
还有,形参实参调用,画图来看
