什么是进程
计算机程序不过是磁盘中可执行的二进制(或其他类型)的数据,它们只有在被读取到内存中,被操作系统调用的时候才开始它们的生命周期。进程是程序的一次执行,每个进程都有自己的地址空间、内存、数据栈以及其他记录运行轨迹的辅助数据。操作系统管理在其上面运行的所有进程,并为这些进程公平的分配空间。
什么是线程
线程(有时被称为轻量级进程)跟进程有些相似,不同的是,所有的线程都运行在同一个进程中,共享相同的运行环境。我们可以想象成在主进程或“主线程”中并行运行的“迷你进程”。
新建文件名的时候,不要以threading结尾,因为跟python中的threading模块会命名冲突。
单线程:
#单线程
import time
def music(func,loop):
for i in range(loop):
print("I want listening to %s! %s " %(func,time.ctime()))
time.sleep(2)
def movie(func,loop):
for i in range(loop):
print("I was at the %s! %s " % (func, time.ctime()))
time.sleep(5)
if __name__=='__main__':
music('只对你有感觉',2)
movie('双子杀手',2)
print("all end:%s" % time.ctime())
print("final is in ", end - start)
多线程:
import time
import threading
def music(func,loop):
for i in range(loop):
print("I want listening to %s! %s " %(func,time.ctime()))
time.sleep(2)
def movie(func,loop):
for i in range(loop):
print("I was at the %s! %s " % (func, time.ctime()))
time.sleep(5)
#创建线程数组
threads=[]
#创建线程t1,并添加到线程组
t1 = threading.Thread(target = music,args =("只对你有感觉",2))
threads.append[t1]
#创建线程t2,并添加到线程组
t2 = threading.Thread(target = music,args = ("双子杀手",2))
threads.append[t2]
if __name__=='__main__':
#启动线程
for t in threads:
t.start()
#守护线程
for t in threads:
t.join()
print("all end:%s" % time.ctime())
超级播放器:
from time import sleep,ctime
import threading
def super_player(file_,time):
for i in range(2):
print("Start playing: %s! %s " %(file_,ctime()))
sleep(time)
#播放的文件与播放时长
lists = {"只对你有感觉.mp3":3,"双子杀手.mp4":5,"我和我的祖国.mp3":4}
threads = []
files = range(len(lists))
#创建线程
for file_,time in lists.items():
t=threading.Thread(target = super_player,args =(file_,time))
threads.append(t)
if __name__=='__main__':
#启动线程
for t in files:
threads[t].start()
#守护线程
for t in files:
threads[t].join()
print("all end:%s" % ctime())
创建线程类:
python2写法:
import threading
from time import sleep,ctime
#创建线程类
class MyThread(threading.Thread):
def __init__(self,func,args,name=''):
threading.Thread.__init__(self) #初始化
self.func = func
self.args = args
self.name = name
def run(self):
apply(self.func,self.args) #当函数参数已经存在与一个元祖或者字典中,可以用apply()间接的调用函数
def super_play(file_,time):
for i in range(2):
print("start playing: %s! %s" %(file_,ctime()))
sleep(time)
lists={'只对你有感觉.mp3':3,"阿凡达.mp4":5,"我和我的祖国.mp3":4}
threads=[]
files = range(len(lists))
for file_,time in lists.items():
t = MyThread(super_play,(file_,time),super_play.__name__)
threads.append(t)
if __name__=='__main__':
#启动线程
for i in files:
threads[i].start()
#守护线程
for i in files:
threads[i].join()
print("all end:%s" % ctime())
python3的写法:
import threading
from time import sleep,ctime
#创建线程类
class MyThread(threading.Thread):
def __init__(self,func,args,name=''):
threading.Thread.__init__(self) #初始化
self.func = func
self.args = args
self.name = name
def run(self):
self.func(*self.args) #当函数参数已经存在与一个元祖或者字典中,可以间接的调用函数
def super_play(file_,time):
for i in range(2):
print("start playing: %s! %s" %(file_,ctime()))
sleep(time)
lists={'只对你有感觉.mp3':3,"阿凡达.mp4":5,"我和我的祖国.mp3":4}
threads=[]
files = range(len(lists))
for file_,time in lists.items():
t = MyThread(super_play,(file_,time),super_play.__name__)
threads.append(t)
if __name__=='__main__':
#启动线程
for i in files:
threads[i].start()
#守护线程
for i in files:
threads[i].join()
print("all end:%s" % ctime())
多进程
multiprocessing模块的使用和多线程threading模块的用法类似。multiprocessing提供了本地和远程的并发性,有效通过全局解释锁(Global Interceptor Lock,GIL)来使
from time import sleep,ctime
import multiprocessing
def super_player(file_,time):
for i in range(2):
print("Start playing: %s! %s " %(file_,ctime()))
sleep(time)
#播放的文件与播放时长
lists = {"只对你有感觉.mp3":3,"双子杀手.mp4":5,"我和我的祖国.mp3":4}
threads = []
files = range(len(lists))
#创建进程
for file_,time in lists.items():
t=multiprocessing.Process(target = super_player,args =(file_,time))
threads.append(t)
if __name__=='__main__':
#启动进程
for t in files:
threads[t].start()
#守护进程
for t in files:
threads[t].join()
print("all end:%s" % ctime())
应用于自动化测试
from threading import Thread
from selenium import webdriver
from time import sleep,ctime
#测试用例
def test_baidu(browser,search):
print("start:%s"%ctime())
print(browser,search)
if browser =='ie':
driver = webdriver.Ie()
elif browser =='chrome':
driver =webdriver.Chrome()
elif browser =='ff':
driver = webdriver.Firefox()
else:
print("browser参数有误,只能为:IE、Firefox、Chrome")
driver.get("https://www.baidu.com")
driver.find_element_by_id("kw").send_keys(search)
driver.find_element_by_id("su").click()
sleep(2)
driver.quit()
if __name__ =="__main__":
#启动参数(指定浏览器与百度搜索内容)
lists = {'chrome':'threading','ie':'webdriver','ff':'python'}
threads = []
files =range(len(lists))
#创建线程
for browser,search in lists.items():
t = Thread(target=test_baidu,args=(browser,search))
threads.append(t)
#启动线程
for t in files:
threads[t].start()
for t in files:
threads[t].join()
print("end:%s"%ctime())
分布式多线程
from threading import Thread
from selenium import webdriver
from time import ctime,sleep
#测试用例
def test_baidu(host,browser):
print("start:%s" %ctime())
print(host,browser)
dc={"browserName":browser}
driver = webdriver.Remote(command_executor=host,desired_capabilities=dc)
driver.get("https://www.baidu.com")
driver.find_element_by_id("kw").send_keys(browser)
driver.find_element_by_id("su").click()
driver.close()
if __name__=="__main__":
#启动参数(指定运行主机与浏览器)
lists = {"http://127.0.0.1:4444/wd/hub":"chrome",
"http://127.0.0.1:5555/wd/hub":"firefox"}
threads=[]
files = range(len(lists))
#创建线程
for host,browser in lists.items():
t = Thread(target=test_baidu,args=(host,browser))
threads.append(t)
# 启动线程
for t in files:
threads[t].start()
for t in files:
threads[t].join()
print("end:%s" % ctime())
运行结果如下:
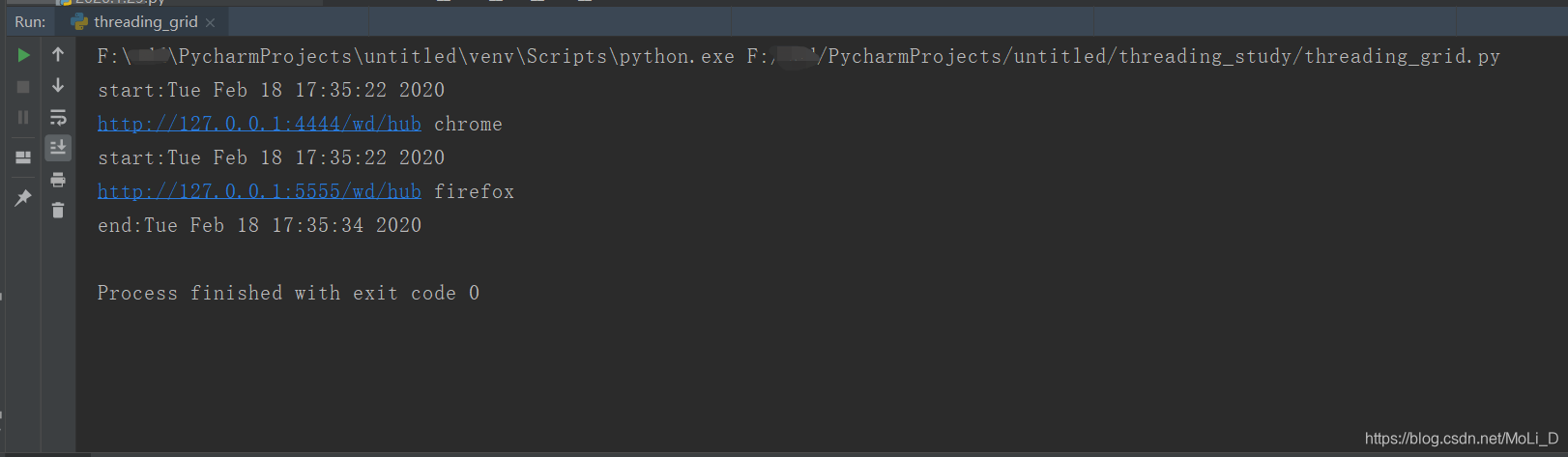
多线程的缺点:
和unittest单元测试框架结合,会有报错,unittest不完全支持多线程的多用例并行,可以用多个虚拟机去做
如果用例过多,用多线程的话,会有问题
java中testNG支持
pytest中对失败的用例可以进行重跑,error一般都是定位错误,fail一般都是与预期结果不相等
能提高自动化测试用例的稳定性,那么就要靠我们自己在设计自动化测试用例的时候,需要前段来配合完成
