概念
进程
进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。在早期面向进程设计的计算机结构中,进程是程序的基本执行实体;在当代面向线程设计的计算机结构中,进程是线程的容器。程序是指令、数据及其组织形式的描述,进程是程序的实体。
简单的说就是某一个运行的程序。
线程
线程(thread)是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。
换句话说就是,线程执行某个任务,n多个线程被放在一个叫做进程的容器中。
并行
使用多个cpu或者多个设备同时执行某个逻辑,真正意义上的同时。
并发
通过cpu的调度算法,在用户体验层面认为是同时的,但是在cpu层面上则并不是同时在处理某一个逻辑。
线程安全
如果一段代码在并发的情况下,在经过多线程处理之后,不会影响最后的结果,则可以认为该代码是线程安全的,反之则是线程不安全的。
同步
通过人为的调度或者控制,保证某共享的资源在多线程访问时是线程安全的。
线程的状态
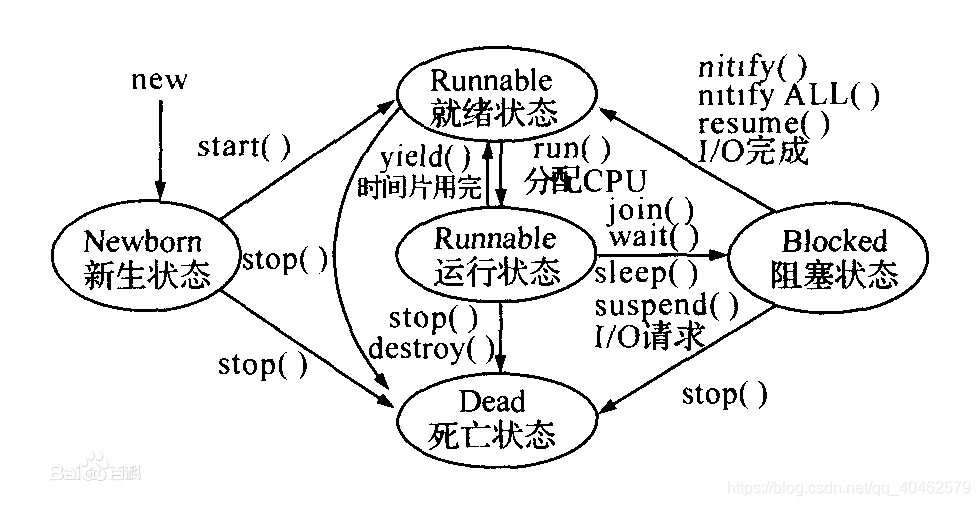
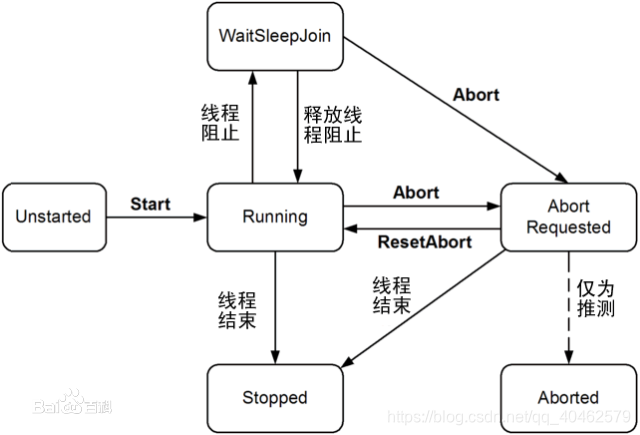
Blocked状态
对Running状态的线程加同步锁(Synchronized)使其进入(lock blocked pool ),同步锁被释放进入可运行状态(Runnable)。
Waiting状态
线程可以主动调用object.wait或者sleep,或者join进入。
线程状态源码
线程的状态全部来自于Threa.state的枚举类:
public enum State {
/**
* Thread state for a thread which has not yet started.
*/
NEW,
/**
* Thread state for a runnable thread. A thread in the runnable
* state is executing in the Java virtual machine but it may
* be waiting for other resources from the operating system
* such as processor.
*/
RUNNABLE,
/**
* Thread state for a thread blocked waiting for a monitor lock.
* A thread in the blocked state is waiting for a monitor lock
* to enter a synchronized block/method or
* reenter a synchronized block/method after calling
* {@link Object#wait() Object.wait}.
*/
BLOCKED,
/**
* Thread state for a waiting thread.
* A thread is in the waiting state due to calling one of the
* following methods:
* <ul>
* <li>{@link Object#wait() Object.wait} with no timeout</li>
* <li>{@link #join() Thread.join} with no timeout</li>
* <li>{@link LockSupport#park() LockSupport.park}</li>
* </ul>
*
* <p>A thread in the waiting state is waiting for another thread to
* perform a particular action.
*
* For example, a thread that has called <tt>Object.wait()</tt>
* on an object is waiting for another thread to call
* <tt>Object.notify()</tt> or <tt>Object.notifyAll()</tt> on
* that object. A thread that has called <tt>Thread.join()</tt>
* is waiting for a specified thread to terminate.
*/
WAITING,
/**
* Thread state for a waiting thread with a specified waiting time.
* A thread is in the timed waiting state due to calling one of
* the following methods with a specified positive waiting time:
* <ul>
* <li>{@link #sleep Thread.sleep}</li>
* <li>{@link Object#wait(long) Object.wait} with timeout</li>
* <li>{@link #join(long) Thread.join} with timeout</li>
* <li>{@link LockSupport#parkNanos LockSupport.parkNanos}</li>
* <li>{@link LockSupport#parkUntil LockSupport.parkUntil}</li>
* </ul>
*/
TIMED_WAITING,
/**
* Thread state for a terminated thread.
* The thread has completed execution.
*/
TERMINATED;
}
线程机制
synchronized, wait, notify 是任何对象都具有的同步工具。
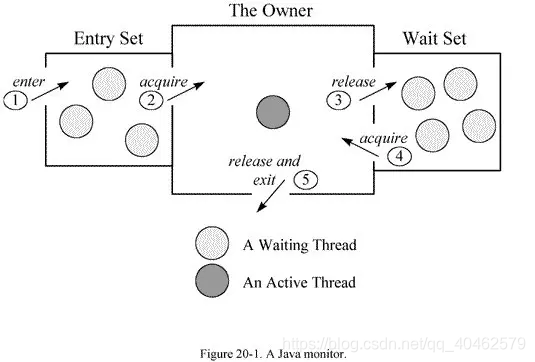
Java中的每个对象都有一个监视器,来监测并发代码的重入。在非多线程编码时该监视器不发挥作用,反之如果在synchronized 范围内,监视器发挥作用。
wait/notify必须存在于synchronized块中。并且,这三个关键字针对的是同一个监视器(某对象的监视器)。这意味着wait之后,其他线程可以进入同步块执行。
当某代码并不持有监视器的使用权时(如图中5的状态,即脱离同步块)去wait或notify,会抛出java.lang.IllegalMonitorStateException。也包括在synchronized块中去调用另一个对象的wait/notify,因为不同对象的监视器不同,同样会抛出此异常。
synchronized关键字
直接使用
代码如下:
/**
* Date:2019/5/9
* Time:11:10
* Author:Zheng Changdao
* Explanation:
* synchronized关键字的直接使用
*/
public class SynchronizedDemo {
Object lock;
public void doSomething(){
synchronized(lock){
//线程互斥的区域
}
}
}
在方法上使用
代码如下:
/**
* Date:2019/5/9
* Time:11:12
* Author:Zheng Changdao
* Explanation:
* synchronized关键字作用于方法
*/
public class SynchronizedDemo2 {
public synchronized void doSometing(){
//线程互斥的方法
}
}
与wait和notify结合
此处以消费者生产者模式为例:
/**
* Date:2019/5/9
* Time:11:14
* Author:Zheng Changdao
* Explanation:
* 以生产者消费者模式来演示synchronized, wait, notify结合使用的场景
*/
public class ProducersAndConsumers {
//当前生产者持有产品
private volatile static int product = 0;
//产品库存最大值
private volatile static int MAX_PRODUCT = 100;
//产品仓库最少产品数
private volatile static int MIN_PRODUCT = 10;
/**
* 生产者生产产品放入仓库
*/
public synchronized void produce(){
if (product > MAX_PRODUCT){//如果当前仓库存不下新的产品了
try {
wait();
} catch (InterruptedException e) {
e.printStackTrace();
System.out.println("仓库已满,等待消费者取走...");
}
}else {//如果当前仓库可以存新的产品则继续生产
product++;
System.out.println("生产者生产了第" + product + "件产品");
notifyAll();
}
}
/**
* 消费者从仓库中取走产品
*/
public synchronized void consume(){
if (product < MIN_PRODUCT){//库存不够,消费者等待生产者生产产品
try {
wait();
} catch (InterruptedException e) {
e.printStackTrace();
System.out.println("产品不足,等待产品...");
}
}else {//库存充足,消费者可以取走产品
product--;
System.out.println("消费者取走了第" + product + "件产品");
notifyAll();
}
}
}
volatile关键字
多线程的内存模型:main memory(主存)、working memory(线程栈),在处理数据时,线程会把值从主存load到本地栈,完成操作后再save回去(volatile关键词的作用:每次针对该变量的操作都激发一次load and save)。
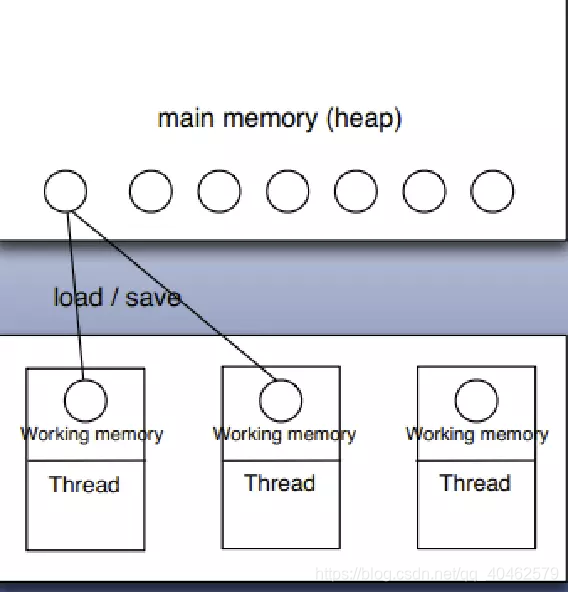
针对多线程使用的变量如果不是volatile或者final修饰的,很有可能产生不可预知的结果(另一个线程修改了这个值,但是之后在某线程看到的是修改之前的值)。其实道理上讲同一实例的同一属性本身只有一个副本。但是多线程是会缓存值的,本质上,volatile就是不去缓存,直接取值。在线程安全的情况下加volatile会牺牲性能。
基本线程类
基本线程类指的是Thread类,Runnable接口,Callable接口 。
Thread类
从以下的JDK源码可以看出,Thread实现了Runnable接口。
public
class Thread implements Runnable{
...
}
创建并启动一个线程:
//新建一个线程
Thread threadOne = new Thread();
//启动线程
threadOne.start();
Thread常用方法
//新建一个线程
Thread threadOne = new Thread();
/**
* Explanation:
* 导致此线程开始执行;
* Java虚拟机调用此线程的run方法。
* 结果是两个线程同时运行:当前线程(从调用返回到start方法)和另一个线程(执行其run方法)。
* 不止一次启动线程是不合法的。
* 特别地,一旦线程完成执行就可能不会重新启动。
* exception:
* IllegalThreadStateException - 如果线程已经启动。
*/
threadOne.start();
/**
* Explanation:
* 对调度程序的一个暗示,
* 即当前线程愿意让出当前使用的处理器给其它线程,
* 但是,具体何时当前的CPU被回收不一定。
*/
Thread.yield();
/**
* Explanation:
* 使当前正在执行的线程以指定的毫秒数暂停(暂时停止执行),
* 具体取决于系统定时器和调度程序的精度和准确性。
* 线程不会丢失任何显示器的所有权。
* param:
* millis - 以毫秒为单位的睡眠时间长度
* nanos - 0-999999额外的纳秒睡眠
* exception:
* IllegalArgumentException - 如果 millis值为负数
* InterruptedException - 如果任何线程中断当前线程。
* 当抛出此异常时,当前线程的中断状态将被清除。
*/
Thread.sleep("xxx","xxx");
/**
* Explanation:
* 等待最多millis毫秒加上这个线程死亡的nanos纳秒。
* 此实现使用this.wait调用的循环,条件为this.isAlive 。
* 当线程终止时,调用this.notifyAll方法。
* 建议应用程序不使用wait , notify ,
* 或notifyAll上Thread实例。
* (等待线程死亡,进入此方法之后,从该方法中跳出的条件是线程死亡
* 如果超时,则会返回跳出join()继续执行之后的代码,因为等待线程是阻塞的)
* param:
* millis - 等待毫秒的时间(0为永远等待)
* nanos - 0-999999等待的额外纳秒
* exception:
* IllegalArgumentException -如果值 millis是否定的,或的值 nanos不在范围 0-999999
* InterruptedException - 如果任何线程已中断当前线程。
* 当抛出此异常时,当前线程的中断状态将被清除。
*/
threadOne.join("xxx","xxx");
/**
* Explanation:
* 导致当前线程等待,直到另一个线程调用此对象的notify()方法或notifyAll()方法,
* 或其他一些线程中断当前线程,或一定量的实时时间。
* 这种方法类似于一个参数的wait方法,但它允许对放弃之前等待通知的时间进行更精细的控制。
* 以纳秒为单位的实时数量由下式给出:
* 1000000*timeout+nanos
* 在所有其他方面,该方法与一个参数的方法wait(long)相同。
* 特别是, wait(0, 0)意味着同样的事情wait(0) 。
* 当前的线程必须拥有该对象的显示器。
* 线程释放此监视器的所有权,并等待直到发生以下两种情况之一:
* 1、另一个线程通知等待该对象的监视器的线程通过调用notify方法或notifyAll方法来唤醒。
* 2、由timeout毫秒加nanos纳秒参数指定的超时时间已过。
* 然后线程等待,直到它可以重新获得监视器的所有权并恢复执行。
* (该过程阻塞)
*/
threadOne.wait("xxx","xxx");
/**
* Explanation:
* 中断这个线程。
* 除非当前线程中断自身,这是始终允许的,
* 所以调用此线程的checkAccess方法,这可能会导致抛出SecurityException 。
* 如果该线程阻塞的调用wait() , wait(long) ,或wait(long, int)的方法Object类,
* 或者在join() , join(long) , join(long, int) , sleep(long) ,或sleep(long, int) ,
* 这个类的方法,那么它的中断状态将被清除,并且将收到一个InterruptedException 。
* 如果该线程在可阻止在I / O操作InterruptibleChannel则信道将被关闭,
* 该线程的中断状态将被设置,并且thread将收到一个ClosedByInterruptException 。
* (仅做中断标记,线程仍会执行,并不是被马上停止或者马上被销毁掉)
*/
threadOne.interrupt();
关于Thread的销毁
没有特殊情况,在线程执行完成Run()之后,就会被JVM回收,也就是被销毁。
关于捕获线程中的异常
首先实现接口,代码如下:
/**
* Date:2019/5/10
* Time:1:01
* Author:Zheng Changdao
* Explanation:
* 实现未捕获异常处理器的接口
*/
public class MyUnchecckedExceptionhandler implements Thread.UncaughtExceptionHandler {
@Override
public void uncaughtException(Thread t, Throwable e) {
//do something when something wrong
System.out.println("线程出错啦!");
}
}
其次,对目标线程设置处理器,代码如下:
Thread threadOne = new Thread();
//通过设置未捕获异常处理器
threadOne.setUncaughtExceptionHandler(new MyUnchecckedExceptionhandler());
threadOne.start();
Runnable接口
Thread类就是Runnable接口的一个实现。
最常用的用法就是重写Run()方法。
Callable接口和Future接口
创建线程的2种方式,一种是直接继承Thread,另外一种就是实现Runnable接口。 这2种方式都有一个缺陷就是:在执行完任务之后无法获取执行结果。
Callable用于产生结果,Future用于获取产生的结果。
分析Runnable的源码:
public abstract void run();
可以看到,Runnable接口中的run()方法是没有返回值的,也就是说在线程执行完任务之后是无法返回结果的。
分析Callable的源码:
V call() throws Exception;
可以看到,Callable接口中的call()方法是有一个泛型的返回值的,也就是说在执行完相应的任务之后可以返回一个运行结果。
以下为一段测试代码:
/**
* Date:2019/5/10
* Time:23:38
* Author:Zheng Changdao
* Explanation:
* Callable接口测试
*/
public class CallableDemo {
public static void main(String[] args) {
//产生结果
Callable<Integer> call = new Callable<Integer>() {
@Override
public Integer call() throws Exception {
System.out.println("线程正在计算...");
Thread.sleep(3000);
return 78;
}
};
//获取结果
FutureTask<Integer> task = new FutureTask<>(call);
Thread thread = new Thread(task);
thread.start();
System.out.println("main线程不参与计算...");
try {
Integer res = task.get();
System.out.println("在call中计算的结果:" + res);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}
FutureTask 类
FutureTask被作为从Callable获取结果的中间媒介。
Future接口
从以下三段源码可以看出,FutureTask的核心还是Future接口:
FutureTask实现了RunnableFuture接口。
public class FutureTask<V> implements RunnableFuture<V>
RunnableFuture接口又实现了Runnable和Future两个接口。
public interface RunnableFuture<V> extends Runnable, Future<V>
而在Future接口中便是最后一层。
public interface Future<V>
Future接口中有以下五个方法:
方法一:取消计算,就算没有计算完毕也可以取消计算过程。
boolean cancel(boolean mayInterruptIfRunning);
方法二:询问当前计算过程是否被取消。
boolean isCancelled();
方法三:判断当前计算过程是否已经被执行完毕。
boolean isDone();
方法四:获取计算结果,如果没有计算完毕也是要等待的。
V get() throws InterruptedException, ExecutionException;
方法五:在指定时间内等待计算结果,如果超时则会抛出TimeoutException。
V get(long timeout, TimeUnit unit)
高级多线程控制类
ThreadLocal类
这个类提供线程局部变量。 这些变量与其正常的对应方式不同,因为访问一个的每个线程(通过其get或set方法)都有自己独立初始化的变量副本。 ThreadLocal实例通常是状态与线程关联的类中的私有静态字段(例如,用户ID或事务ID)。
只要线程存活并且ThreadLocal实例可以访问,每个线程都保存对其线程局部变量副本的隐式引用; 线程消失后,线程本地实例的所有副本都将被垃圾收集(除非存在对这些副本的其他引用)。
ThreadLocal在每个线程中对该变量会创建一个副本,即每个线程内部都会有一个该变量,且在线程内部任何地方都可以使用,线程之间互不影响,这样一来就不存在线程安全问题,也不会严重影响程序执行性能。
简单使用样例:
import java.util.ArrayList;
import java.util.List;
/**
* Date:2019/5/11
* Time:10:21
* Author:Zheng Changdao
* Explanation:
* ThreadLocal类简单使用
*/
public class ThreadLocalDemo {
/**
* 同一个ThreadLocal对象
* 在不同的线程中赋值
* 输出时互不影响
*/
private static ThreadLocal<List<String>> threadLocal = new ThreadLocal<>();
public void setThreadLocal(List<String> value){
threadLocal.set(value);
}
public void getThreadLocal(){
for(String cursor:threadLocal.get()){
System.out.println(Thread.currentThread().getName() + " ### " + cursor);
}
}
public static void main(String[] args) {
final ThreadLocalDemo threadLocalDemo = new ThreadLocalDemo();
//在一号线程副本中加入0-9十个数字,然后输出
new Thread(new Runnable() {
@Override
public void run() {
List<String> strings = new ArrayList<>();
strings.add("0");
strings.add("1");
strings.add("2");
strings.add("3");
strings.add("4");
strings.add("5");
strings.add("6");
strings.add("7");
strings.add("8");
strings.add("9");
threadLocalDemo.setThreadLocal(strings);
threadLocalDemo.getThreadLocal();
}
},"thread_one").start();
//在二号线程副本中加入a-j共10个字母,然后输出
new Thread(new Runnable() {
@Override
public void run() {
List<String> strings = new ArrayList<>();
strings.add("a");
strings.add("b");
strings.add("c");
strings.add("d");
strings.add("e");
strings.add("f");
strings.add("g");
strings.add("h");
strings.add("i");
strings.add("j");
threadLocalDemo.setThreadLocal(strings);
threadLocalDemo.getThreadLocal();
}
},"thread_two").start();
}
}
/**
* 输出结果:
* thread_two ### a
* thread_two ### b
* thread_two ### c
* thread_two ### d
* thread_two ### e
* thread_two ### f
* thread_two ### g
* thread_two ### h
* thread_two ### i
* thread_two ### j
* thread_one ### 0
* thread_one ### 1
* thread_one ### 2
* thread_one ### 3
* thread_one ### 4
* thread_one ### 5
* thread_one ### 6
* thread_one ### 7
* thread_one ### 8
* thread_one ### 9
*/
与Synchonized的区别
Synchronized用于线程间的数据共享(使变量或代码块在某一时该只能被一个线程访问),是一种以延长访问时间来换取线程安全性的策略;
而ThreadLocal则用于线程间的数据隔离(为每一个线程都提供了变量的副本),是一种以空间来换取线程安全性的策略。
常用方法
get()方法,获取在当前线程中存入的信息(当前副本):
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
主要依靠ThreadLocalMap来实现功能,ThreadLocalMap是一个弱引用。
set()方法,将某些值保存在当前线程中(当前副本):
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
主要依靠ThreadLocalMap来实现主要功能。
remove方法,清除掉set()方法设置的值。
public void remove() {
ThreadLocalMap m = getMap(Thread.currentThread());
if (m != null)
m.remove(this);
}
原子类
在多线程操作时能保证变量的原子性。
jdk 1.8中部分的原子类:
- AtomicBoolean
- AtomicInteger
- AtomicIntegerArray
- AtomicLong
- AtomicLongArray
- AtomicMarkableReference
- AtomicReference
- AtomicReferenceArray
简单使用(以Integer为例):
import java.util.concurrent.atomic.AtomicInteger;
/**
* Date:2019/5/11
* Time:23:38
* Author:Zheng Changdao
* Explanation:
* 原子类的简单使用
*/
public class AtomicObjDemo {
public static void main(String[] args) {
//新建对象
AtomicInteger integer = new AtomicInteger();
//设置初始值
integer.set(1);
//获取值
integer.get();
//自增之后再获取
integer.incrementAndGet();
//先取值后自增
integer.getAndIncrement();
//自减再取值
integer.decrementAndGet();
}
}
Lock类
synchronized的不足
第一大不足:由于我们没办法设置synchronized关键字在获取锁的时候等待时间,所以synchronized可能会导致线程为了加锁而无限期地处于阻塞状态。
第二大不足:使用synchronized关键字等同于使用了互斥锁,即其他线程都无法获得锁对象的访问权。这种策略对于读多写少的应用而言是很不利的,因为即使多个读者看似可以并发运行,但他们实际上还是串行的,并将最终导致并发性能的下降。
Lock接口
实现提供比使用synchronized方法和语句可以获得的更广泛的锁定操作。 它们允许更灵活的结构化,可能具有完全不同的属性,并且可以支持多个相关联的对象Condition 。
锁是用于通过多个线程控制对共享资源的访问的工具。 通常,锁提供对共享资源的独占访问:一次只能有一个线程可以获取锁,并且对共享资源的所有访问都要求首先获取锁。 但是,一些锁可能允许并发访问共享资源,如ReadWriteLock的读锁。
所有Lock实施必须执行与内置监视器锁相同的内存同步语义,如The Java Language Specification (17.4 Memory Model) 所述 :
成功的lock操作具有与成功锁定动作相同的内存同步效果。
成功的unlock操作具有与成功解锁动作相同的内存同步效果。
不成功的锁定和解锁操作以及重入锁定/解锁操作,不需要任何内存同步效果。
Lock接口中主要有以下几个方法:
//获得锁
void lock();
//获取锁定,除非当前线程是 interrupted
void lockInterruptibly() throws InterruptedException;
//获取锁定,除非当前线程是 interrupted
boolean tryLock();
//如果在给定的等待时间内是空闲的,并且当前的线程尚未得到 interrupted,则获取该锁
boolean tryLock(long time, TimeUnit unit) throws InterruptedException;
//释放锁
void unlock();
//返回一个新Condition绑定到该实例Lock实例
Condition newCondition();
ReentrantLock类
可重入的意义在于持有锁的线程可以继续持有,并且要释放对等的次数后才真正释放该锁。
ReentrantLock类常用方法及其源码:
private final Sync sync;
//获得锁
public void lock() {
sync.lock();
}
//获得锁,可被打断
public void lockInterruptibly() throws InterruptedException {
sync.acquireInterruptibly(1);
}
//释放锁
public void unlock() {
sync.release(1);
}
释放锁时,一定要放在finally代码块中,必须保证如果报错或者异常时,所也能被释放不会引起灾难。
ReentrantReadWriteLock类
对写入和读取操作加锁。
常用方法如下:
//获取写入锁
public ReentrantReadWriteLock.WriteLock writeLock() { return writerLock; }
//获得阅读锁
public ReentrantReadWriteLock.ReadLock readLock() { return readerLock; }
阅读锁和写入锁的常用方法与普通锁相似。
容器类
BlockingQueue
从源码来看阻塞队列继承于Queue:
public interface BlockingQueue<E> extends Queue<E>
与普通的Queue相比,新增两个阻塞接口put和take以及两个阻塞超时接口offer和poll。
put会在队列满的时候阻塞,直到有空间时被唤醒;take在队 列空的时候阻塞,直到有东西拿的时候才被唤醒。
源码如下:
boolean offer(E e);
void put(E e) throws InterruptedException;
boolean offer(E e, long timeout, TimeUnit unit)
throws InterruptedException;
E take() throws InterruptedException;
ConcurrentHashMap
HashMap是线程不安全的,在多线程的环境下,操作HashMap会导致线程安全的问题。若使用同步包装器下的HashMap,则会造成很大的性能问题。为此,JDK提供了ConcurrentHashMap来解决此问题。 (线程安全且性能较好)
public class ConcurrentHashMap<K,V> extends AbstractMap<K,V>
implements ConcurrentMap<K,V>, Serializable
ConcurrentHashMap 的使用方法与普通HashMap相似。
管理类
管理类的概念比较泛,用于管理线程,本身不是多线程的,但提供了一些机制来利用上述的工具做一些封装。
ThreadPoolExecutor
本身不是线程,而是管理线程的类。
ThreadPoolExecutor有以下四种构造方法:
第一种,创建一个新的ThreadPoolExecutor和给定的初始参数、默认线程工厂和拒绝处理程序:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
第二种,创建一个新的ThreadPoolExecutor和给定的初始参数和默认线程工厂:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
threadFactory, defaultHandler);
}
第三种,创建一个新的ThreadPoolExecutor和给定的初始参数和默认拒绝执行处理的程序:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
RejectedExecutionHandler handler) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), handler);
}
第四种,创建一个新的ThreadPoolExecutor和给定的初始参数:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
参数含义
corePoolSize:池内线程初始值与最小值,就算是空闲状态,也会保持该数量线程。
maximumPoolSize:线程最大值,线程的增长始终不会超过该值。
keepAliveTime:当池内线程数高于corePoolSize时,经过多少时间多余的空闲线程才会被回收。回收前处于wait状态
unit: 时间单位,可以使用TimeUnit的实例,如TimeUnit.MILLISECONDS
workQueue:待入任务(Runnable)的等待场所,该参数主要影响调度策略,如公平与否,是否产生饿死(starving)
threadFactory:线程工厂类,有默认实现,如果有自定义的需要则需要自己实现ThreadFactory接口并作为参数传入。
资料参考
线程世界(http://www.threadworld.cn/)
Java中的多线程你只要看这一篇就够了(https://www.jianshu.com/p/40d4c7aebd66)
