Transformer
下图展示了Transformer模型的架构,与seq2seq模型相似,Transformer同样基于编码器-解码器架构,其区别主要在于以下三点:
1.Transformer blocks:将seq2seq模型重的循环网络替换为了Transformer Blocks,该模块包含一个多头注意力层(Multi-head Attention Layers)以及两个position-wise feed-forward networks(FFN)。对于解码器来说,另一个多头注意力层被用于接受编码器的隐藏状态。
2. Add and norm:多头注意力层和前馈网络的输出被送到两个“add and norm”层进行处理,该层包含残差结构以及层归一化。
3.Position encoding:由于自注意力层并没有区分元素的顺序,所以一个位置编码层被用于向序列元素里添加位置信息。

多头注意力层
在我们讨论多头注意力层之前,先来迅速理解以下自注意力(self-attention)的结构。自注意力模型是一个正规的注意力模型,序列的每一个元素对应的key,value,query是完全一致的。如图10.3.2 自注意力输出了一个与输入长度相同的表征序列,与循环神经网络相比,自注意力对每个元素输出的计算是并行的,所以我们可以高效的实现这个模块。

多头注意力层包含个并行的自注意力层,每一个这种层被成为一个head。对每个头来说,在进行注意力计算之前,我们会将query、key和value用三个现行层进行映射,这个注意力头的输出将会被拼接之后输入最后一个线性层进行整合。

class MultiHeadAttention(nn.Module):
def __init__(self, input_size, hidden_size, num_heads, dropout, **kwargs):
super(MultiHeadAttention, self).__init__(**kwargs)
self.num_heads = num_heads
self.attention = DotProductAttention(dropout)
self.W_q = nn.Linear(input_size, hidden_size, bias=False)
self.W_k = nn.Linear(input_size, hidden_size, bias=False)
self.W_v = nn.Linear(input_size, hidden_size, bias=False)
self.W_o = nn.Linear(hidden_size, hidden_size, bias=False)
def forward(self, query, key, value, valid_length):
# query, key, and value shape: (batch_size, seq_len, dim),
# where seq_len is the length of input sequence
# valid_length shape is either (batch_size, )
# or (batch_size, seq_len).
# Project and transpose query, key, and value from
# (batch_size, seq_len, hidden_size * num_heads) to
# (batch_size * num_heads, seq_len, hidden_size).
query = transpose_qkv(self.W_q(query), self.num_heads)
key = transpose_qkv(self.W_k(key), self.num_heads)
value = transpose_qkv(self.W_v(value), self.num_heads)
if valid_length is not None:
# Copy valid_length by num_heads times
device = valid_length.device
valid_length = valid_length.cpu().numpy() if valid_length.is_cuda else valid_length.numpy()
if valid_length.ndim == 1:
valid_length = torch.FloatTensor(np.tile(valid_length, self.num_heads))
else:
valid_length = torch.FloatTensor(np.tile(valid_length, (self.num_heads,1)))
valid_length = valid_length.to(device)
output = self.attention(query, key, value, valid_length)
output_concat = transpose_output(output, self.num_heads)
return self.W_o(output_concat)
def transpose_qkv(X, num_heads):
# Original X shape: (batch_size, seq_len, hidden_size * num_heads),
# -1 means inferring its value, after first reshape, X shape:
# (batch_size, seq_len, num_heads, hidden_size)
X = X.view(X.shape[0], X.shape[1], num_heads, -1)
# After transpose, X shape: (batch_size, num_heads, seq_len, hidden_size)
X = X.transpose(2, 1).contiguous()
# Merge the first two dimensions. Use reverse=True to infer shape from
# right to left.
# output shape: (batch_size * num_heads, seq_len, hidden_size)
output = X.view(-1, X.shape[2], X.shape[3])
return output
# Saved in the d2l package for later use
def transpose_output(X, num_heads):
# A reversed version of transpose_qkv
X = X.view(-1, num_heads, X.shape[1], X.shape[2])
X = X.transpose(2, 1).contiguous()
return X.view(X.shape[0], X.shape[1], -1)
基于位置的前馈网络
Transformer 模块另一个非常重要的部分就是基于位置的前馈网络(FFN),它接受一个形状为(batch_size,seq_length, feature_size)的三维张量。Position-wise FFN由两个全连接层组成,他们作用在最后一维上。因为序列的每个位置的状态都会被单独地更新,所以我们称他为position-wise,这等效于一个1x1的卷积。
下面我们来实现PositionWiseFFN:
class PositionWiseFFN(nn.Module):
def __init__(self, input_size, ffn_hidden_size, hidden_size_out, **kwargs):
super(PositionWiseFFN, self).__init__(**kwargs)
self.ffn_1 = nn.Linear(input_size, ffn_hidden_size)
self.ffn_2 = nn.Linear(ffn_hidden_size, hidden_size_out)
def forward(self, X):
return self.ffn_2(F.relu(self.ffn_1(X)))
与多头注意力层相似,FFN层同样只会对最后一维的大小进行改变;除此之外,对于两个完全相同的输入,FFN层的输出也将相等。
Add and Norm
除了上面两个模块之外,Transformer还有一个重要的相加归一化层,它可以平滑地整合输入和其他层的输出,因此我们在每个多头注意力层和FFN层后面都添加一个含残差连接的Layer Norm层。这里 Layer Norm 与7.5小节的Batch Norm很相似,唯一的区别在于Batch Norm是对于batch size这个维度进行计算均值和方差的,而Layer Norm则是对最后一维进行计算。层归一化可以防止层内的数值变化过大,从而有利于加快训练速度并且提高泛化性能。
layernorm = nn.LayerNorm(normalized_shape=2, elementwise_affine=True)
batchnorm = nn.BatchNorm1d(num_features=2, affine=True)
X = torch.FloatTensor([[1,2], [3,4]])
print('layer norm:', layernorm(X))
print('batch norm:', batchnorm(X))
#layer norm: tensor([[-1.0000, 1.0000],
# [-1.0000, 1.0000]], grad_fn=<NativeLayerNormBackward>)
#batch norm: tensor([[-1.0000, -1.0000],
# [ 1.0000, 1.0000]], grad_fn=<NativeBatchNormBackward>)
class AddNorm(nn.Module):
def __init__(self, hidden_size, dropout, **kwargs):
super(AddNorm, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
self.norm = nn.LayerNorm(hidden_size)
def forward(self, X, Y):
return self.norm(self.dropout(Y) + X)
位置编码

class PositionalEncoding(nn.Module):
def __init__(self, embedding_size, dropout, max_len=1000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(dropout)
self.P = np.zeros((1, max_len, embedding_size))
X = np.arange(0, max_len).reshape(-1, 1) / np.power(
10000, np.arange(0, embedding_size, 2)/embedding_size)
self.P[:, :, 0::2] = np.sin(X)
self.P[:, :, 1::2] = np.cos(X)
self.P = torch.FloatTensor(self.P)
def forward(self, X):
if X.is_cuda and not self.P.is_cuda:
self.P = self.P.cuda()
X = X + self.P[:, :X.shape[1], :]
return self.dropout(X)
编码器
我们已经有了组成Transformer的各个模块,现在我们可以开始搭建了!编码器包含一个多头注意力层,一个position-wise FFN,和两个 Add and Norm层。对于attention模型以及FFN模型,我们的输出维度都是与embedding维度一致的,这也是由于残差连接天生的特性导致的,因为我们要将前一层的输出与原始输入相加并归一化。
class EncoderBlock(nn.Module):
def __init__(self, embedding_size, ffn_hidden_size, num_heads,
dropout, **kwargs):
super(EncoderBlock, self).__init__(**kwargs)
self.attention = MultiHeadAttention(embedding_size, embedding_size, num_heads, dropout)
self.addnorm_1 = AddNorm(embedding_size, dropout)
self.ffn = PositionWiseFFN(embedding_size, ffn_hidden_size, embedding_size)
self.addnorm_2 = AddNorm(embedding_size, dropout)
def forward(self, X, valid_length):
Y = self.addnorm_1(X, self.attention(X, X, X, valid_length))
return self.addnorm_2(Y, self.ffn(Y))
现在我们来实现整个Transformer 编码器模型,整个编码器由n个刚刚定义的Encoder Block堆叠而成,因为残差连接的缘故,中间状态的维度始终与嵌入向量的维度d一致;同时注意到我们把嵌入向量乘以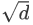 以防止其值过小。
以防止其值过小。
class TransformerEncoder(d2l.Encoder):
def __init__(self, vocab_size, embedding_size, ffn_hidden_size,
num_heads, num_layers, dropout, **kwargs):
super(TransformerEncoder, self).__init__(**kwargs)
self.embedding_size = embedding_size
self.embed = nn.Embedding(vocab_size, embedding_size)
self.pos_encoding = PositionalEncoding(embedding_size, dropout)
self.blks = nn.ModuleList()
for i in range(num_layers):
self.blks.append(
EncoderBlock(embedding_size, ffn_hidden_size,
num_heads, dropout))
def forward(self, X, valid_length, *args):
X = self.pos_encoding(self.embed(X) * math.sqrt(self.embedding_size))
for blk in self.blks:
X = blk(X, valid_length)
return X
解码器
class DecoderBlock(nn.Module):
def __init__(self, embedding_size, ffn_hidden_size, num_heads,dropout,i,**kwargs):
super(DecoderBlock, self).__init__(**kwargs)
self.i = i
self.attention_1 = MultiHeadAttention(embedding_size, embedding_size, num_heads, dropout)
self.addnorm_1 = AddNorm(embedding_size, dropout)
self.attention_2 = MultiHeadAttention(embedding_size, embedding_size, num_heads, dropout)
self.addnorm_2 = AddNorm(embedding_size, dropout)
self.ffn = PositionWiseFFN(embedding_size, ffn_hidden_size, embedding_size)
self.addnorm_3 = AddNorm(embedding_size, dropout)
def forward(self, X, state):
enc_outputs, enc_valid_length = state[0], state[1]
# state[2][self.i] stores all the previous t-1 query state of layer-i
# len(state[2]) = num_layers
# If training:
# state[2] is useless.
# If predicting:
# In the t-th timestep:
# state[2][self.i].shape = (batch_size, t-1, hidden_size)
# Demo:
# love dogs ! [EOS]
# | | | |
# Transformer
# Decoder
# | | | |
# I love dogs !
if state[2][self.i] is None:
key_values = X
else:
# shape of key_values = (batch_size, t, hidden_size)
key_values = torch.cat((state[2][self.i], X), dim=1)
state[2][self.i] = key_values
if self.training:
batch_size, seq_len, _ = X.shape
# Shape: (batch_size, seq_len), the values in the j-th column are j+1
valid_length = torch.FloatTensor(np.tile(np.arange(1, seq_len+1), (batch_size, 1)))
valid_length = valid_length.to(X.device)
else:
valid_length = None
X2 = self.attention_1(X, key_values, key_values, valid_length)
Y = self.addnorm_1(X, X2)
Y2 = self.attention_2(Y, enc_outputs, enc_outputs, enc_valid_length)
Z = self.addnorm_2(Y, Y2)
return self.addnorm_3(Z, self.ffn(Z)), state
对于Transformer解码器来说,构造方式与编码器一样,除了最后一层添加一个dense layer以获得输出的置信度分数。下面让我们来实现一下Transformer Decoder,除了常规的超参数例如vocab_size embedding_size 之外,解码器还需要编码器的输出 enc_outputs 和句子有效长度 enc_valid_length。

class TransformerDecoder(d2l.Decoder):
def __init__(self, vocab_size, embedding_size, ffn_hidden_size,
num_heads, num_layers, dropout, **kwargs):
super(TransformerDecoder, self).__init__(**kwargs)
self.embedding_size = embedding_size
self.num_layers = num_layers
self.embed = nn.Embedding(vocab_size, embedding_size)
self.pos_encoding = PositionalEncoding(embedding_size, dropout)
self.blks = nn.ModuleList()
for i in range(num_layers):
self.blks.append(
DecoderBlock(embedding_size, ffn_hidden_size, num_heads,
dropout, i))
self.dense = nn.Linear(embedding_size, vocab_size)
def init_state(self, enc_outputs, enc_valid_length, *args):
return [enc_outputs, enc_valid_length, [None]*self.num_layers]
def forward(self, X, state):
X = self.pos_encoding(self.embed(X) * math.sqrt(self.embedding_size))
for blk in self.blks:
X, state = blk(X, state)
return self.dense(X), state
