
BeauifulSoup库与HTML详解
在学习python爬虫时又一个非常好用的解析HTML的库那就是BeautifulSoup库,下面就让我们来详细的介绍一下BeautifulSoup库的使用以及HTML的解析。
1. BeautifulSoup
1.1 BeautifulSoup库的安装
打开cmd终端输入一下代码:pip install BeautifulSoup4 注意:S P大写
安装完成后如图:
测试BeautifulSoup4:
# -*- coding:utf-8 -*-
# -Author-= JamesBen
# Email: [email protected]
import requests
from bs4 import BeautifulSoup
def get_HTMLText(url):
try :
use = {'User-Agent': 'Mozilla/5.0'} #此行代码骗过服务器我们是使用浏览器进行访问的,防止有些网站对我们进行拦截
r = requests.get(url, timeout = 30,headers = use)
r.raise_for_status() #如果状态不是200引发HTTPError异常
r.encoding = r.apparent_encoding #将文本的编辑方式传给头,防止造成编码错路出现乱码
demo = r.text
soup = BeautifulSoup(demo,"html.parser")
return soup
except :
return "产生异常"
if __name__ == "__main__":
url = "https://www.amazon.cn/"
print(get_HTMLText(url))
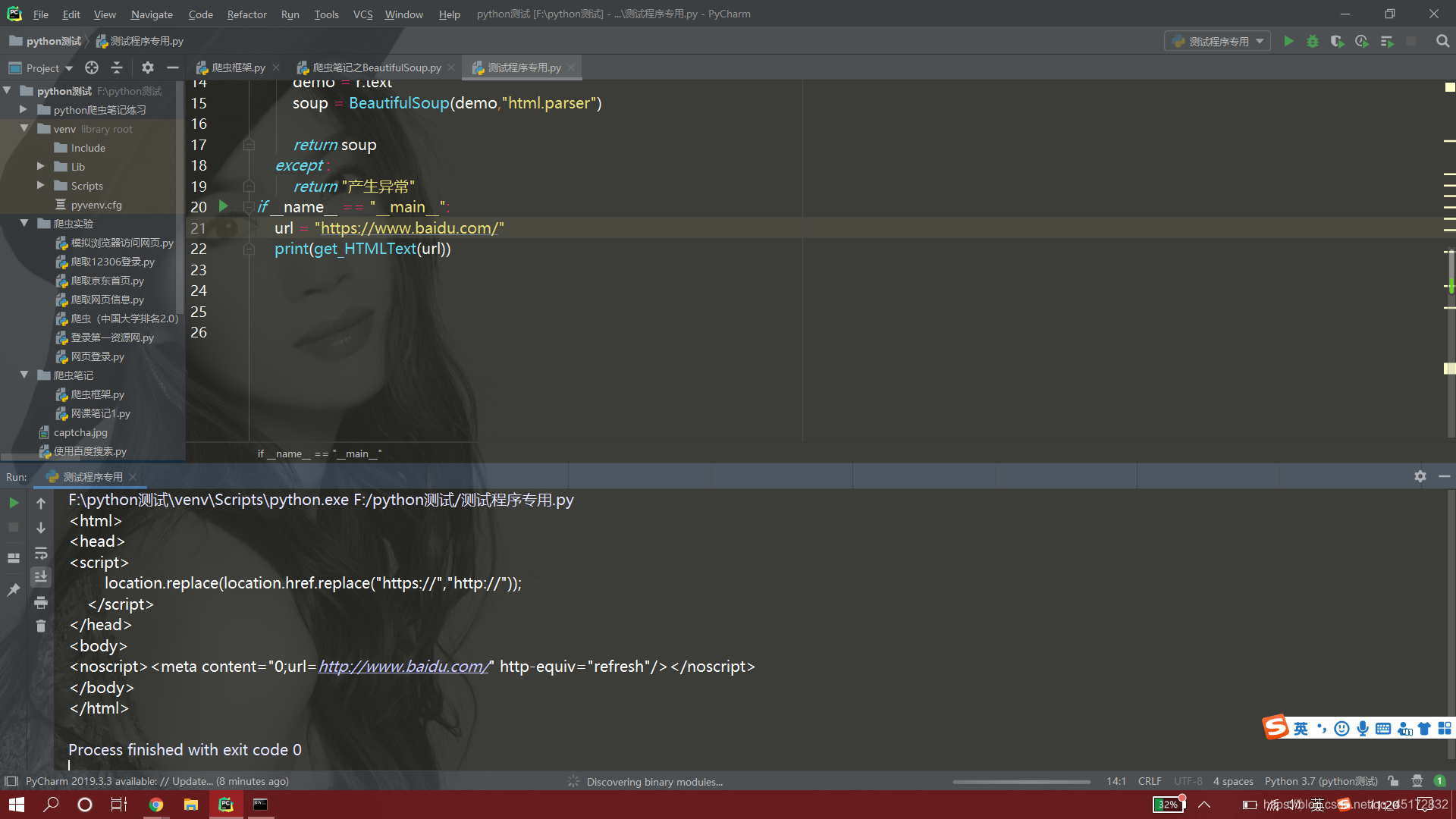
若代码运行如下,则表明安装成功:
1.2 BeautifulSoup库的使用
- 手动获得源代码,在网页右键查看源代码就可以了
- 使用requests库自动获取源代码例如:
# -*- coding:utf-8 -*-
# -Author-= JamesBen
# Email: [email protected]
import requests
from bs4 import BeautifulSoup
url = "http://baidu.com"
r = request.get(url) #get网页上的所有内容
demo = r.text #将源代码传给demo,此时demo就是网页源码了
1.3 BeautifulSoup库的解析器
| 解析器 | 使用方法 | 条件 |
|---|---|---|
| bs4的HTML解析器 | BeautifulSoup(mk,“html.parser”) | 安装bs4库 |
| lxml的HTML解析器 | BeautifulSoup(mk,“lxml”) | pip install lxml |
| lxml的XML解析器 | BeautifulSoup(mk,“xml”) | pip install lxml |
| html5lib解析器 | BeautifulSoup(mk,“html5lib”) | pip install html5lib |
1.4 BeautifulSoup库的基本元素
| 基本元素 | 说明 |
|---|---|
| Tag | 标签,最基本的信息组成单元,分别用<>和</>表明开头 |
| Name | 标签的名字, … 的名字是"p",格式:.name |
| Attributes | 标签的属性,字典形式组织,格式:.attrs |
| NavigableString | 标签内非属性字符串,<>…</>中的字符串,格式为:.string |
| Comment | 标签内字符串注释部分,一种特殊的comment |
注意:.name智能返回第一个,而不是全部的name标签
标签使用样例:
>>> from bs4 import BeautifulSoup
>>> url = "https://baidu.com"
>>> import requests
>>> r = requests.get(url)
>>> demo = r.text
>>> soup = BeautifulSoup(demo,'html.parser')
>>> soup.title
<title>百度一下,你就知道</title>
>>> soup.div.name #打印标签的名字
'div'
>>> soup.div.parent.parent.name #打印父亲节点的名字
'html'
>>> tag = soup.div
>>> tag.attrs #打印标签的属性
{'id': 'wrapper'} #字典类型
>>> tag.attrs['id'] #打印属性的指定信息
'wrapper'
>>> soup.a.string #获取标签内的字符串
'新闻'
提示学习来源:北京理工大学慕课

