程序描述:
主线程启动10个子线程并将表示子线程序号的变量地址作为参数传递给子线程。子线程接收参数 -> sleep-> 全局变量++ -> sleep -> 输出参数和全局变量。
要求:
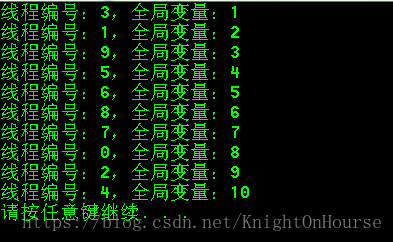
1.子线程输出的线程序号不能重复。
2.全局变量的输出必须递增。
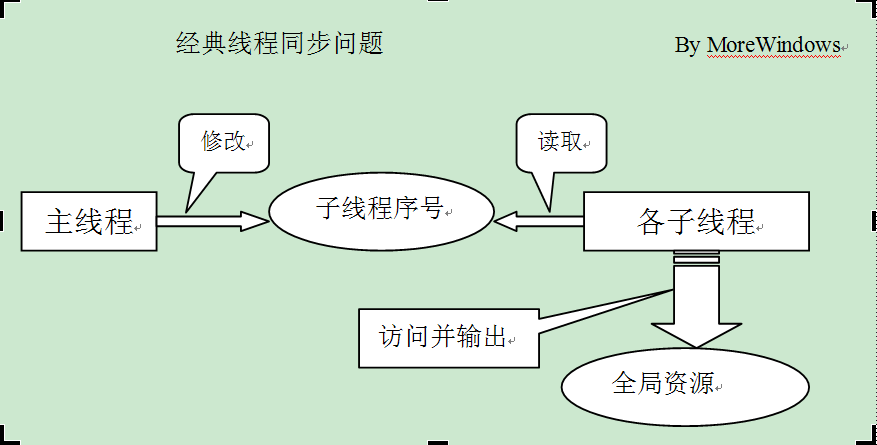
下面画了个简单的示意图:
分析下这个问题的考察点,主要考察点有二个:
1.主线程创建子线程并传入一个指向变量地址的指针作参数,由于线程启动须要花费一定的时间,所以在子线程根据这个指针访问并保存数据前,主线程应等待子线程保存完毕后才能改动该参数并启动下一个线程。这涉及到主线程与子线程之间的同步。
2.子线程之间会互斥的改动和输出全局变量。要求全局变量的输出必须递增。这涉及到各子线程间的互斥。
实现代码如下:
#include<ctime>
#include<cstdio>
#include<iostream>
#include <fstream>
using namespace std;
#include <boost/thread.hpp>
#include <boost/thread/mutex.hpp>
#include <boost/thread/lock_types.hpp>
#include <boost/thread/condition_variable.hpp>
using namespace boost;
typedef boost::mutex CMutex;
typedef boost::condition_variable_any CCondVar;
typedef boost::lock_guard<CMutex> CLockGuard;
typedef boost::unique_lock<CMutex> CUniqueLock;
class CSemaphore{
private:
int iResCnt;
CMutex oMutex;
CCondVar oCondVar;
public:
explicit CSemaphore(unsigned int res = 0) : iResCnt(res){}
void Release(){
{
CLockGuard oLockGuard(oMutex);
iResCnt = iResCnt + 1;
}
oCondVar.notify_one();
}
void WaitFor(){
CUniqueLock oUniqueLock(oMutex);
while(iResCnt == 0){
oCondVar.wait(oUniqueLock);
}
iResCnt = iResCnt - 1;
}
};
long lGlobVar = 0;//全局资源,各线程间互斥访问
CMutex oMutexGlobVar;//互斥量:守护全局变量
CSemaphore oSemaphorePtrParam;//信号量:主线程与子线程之间的同步
void ThreadProc(void* threadno){
//由于创建线程是要一定的开销的,所以新线程并不能第一时间执行到这来
int iThreadNo = *(int*)threadno;
oSemaphorePtrParam.Release();//信号量++
this_thread::sleep(posix_time::seconds(rand()%5));
oMutexGlobVar.lock();
lGlobVar++;//处理全局资源
this_thread::sleep(posix_time::seconds(rand()%3));
cout << "线程编号:" << iThreadNo << ",全局变量:" << lGlobVar << endl;
oMutexGlobVar.unlock();
}
void main()
{
srand((unsigned)time(NULL));//设置随机数的种子
boost::thread oThreads[10];
for(int i = 0; i < 10; i++){//等子线程接收到参数时主线程可能改变了这个
//创建线程【传递的参数为线程编号】
oThreads[i] = boost::thread(ThreadProc, &i);
oSemaphorePtrParam.WaitFor();//等待信号量>0 ,信号量--
}
//保证子线程已全部运行结束
for(int i = 0; i < 10; i++) oThreads[i].join();
}
运行结果如下: