SPPNet
SPP-Net是一种可以不用考虑图像大小,输出图像固定长度网络结构,并且可以做到在图像变形情况下表现稳定。SSP-net的效果已经在不同的数据集上面得到验证,速度上比R-CNN快24-102倍。在ImageNet 2014的比赛中,此方法检测中第二,分类中第三。
SPPNet经典论文《Spatial Pyramid Pooling in Deep ConvolutionalNetworks for Visual Recognition》
Introduction
SPPNet主要根据针对之前网络的两个方面进行了改进:
1.CNN固定输入的大小,导致不必要的精度损失
2.R-CNN模型候选区域在CNN内的重复计算,造成的计算冗余
为什么会出现这两个问题,原因如下:
1.一个CNN一般分为两个部分,前面的部分是卷积层,后面的部分是FC层,卷积层不要求固定大小的输入;但是FC层在设计时固定了神经元的个数,需要固定长度的输入,因此就需要在输入的时候固定输入图像的大小。但是在对候选区域进行预处理的时候,可能会让图片不完整或失真,因此造成了一定程度的识别精度损失。
解决方案:
SPPNet的解决办法是使用“空间金字塔变换层”将接收任意大小的图像输入,输出固定长度的输出向量,这样就能让SPPNet可接受任意大小的输入图片。
2.在R-CNN中,每个候选区域都要经过CNN提取特征向量,一张图片有2000个候选区域,也就是一张图片需要经过2000次CNN的前向传播,这2000重复计算过程会有大量的计算冗余,耗费大量的时间。
解决方案:
SPPNet提出了一种从候选区域到全图的特征映射(feature map)之间的对应关系,通过此种映射关系可以直接获取到候选区域的特征向量,不需要重复使用CNN提取特征,从而大幅度缩短训练时间。
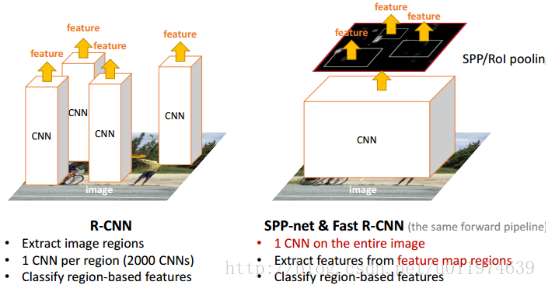
通过以上的介绍我们发现SPPNet主要有两个难点:一是空间金字塔的是怎样工作的,二是SPPNet如何把特征区域的feature map映射出来的。
下面一一来解决这两个问题:
空间金字塔变换层
经典论文:
空间金字塔变换层(Spatial Pyramid Pooling,SPP)可以对图片提取特征,例如下图就是1*1,2*2,4*4大小的bin块,将一张图片以三种方式切割并提取特征,这样我们可以得到一共1+4+16=21种特征,这就是以不同的大小的bin块来提取特征的过程就是空间金字塔变换。

上图spp layer分成1x1(塔底),2x2(塔中),4x4(塔顶)三张子图,对每个子图的每个区域作max pooling(论文使用的),出来的特征再连接到一起,就是(16+4+1)x256的特征向量。
无论输入图像大小如何,出来的特征固定是(16+4+1)x256维度。这样就实现了不管图像尺寸如何,SPP层的输出为(16+4+1)x256特征向量。
候选区域映射特征向量
SPP-net 是把原始ROI的左上角和右下角 映射到 feature map上的两个对应点。 有了feature map上的两队角点就确定了 对应的 feature map 区域(下图中橙色)。

如何映射?
左上角的点(x,y)映射到 feature map上的(x′,y′) :使得(x′,y′) 在原始图上感受野(上图绿色框)的中心点 与(x,y)尽可能接近。
参考链接:
