深度学习的一个知识总结

罗嗦两句
好吧,可能你很奇怪为何这么久我没写博客了,从十二月开始,我不得不专心于一篇paper的撰写,在一月下旬开始我一直在恶补一些理论知识,包括应用数学、统计物理、还有一些琐碎的广义相对论知识,一些只是因为兴趣。
今天我要谈及的
今天只是试图用白话总结一下深度学习里一些常见的知识点,在看懂这篇文章前,你起码对深度学习和机器学习乃至概率统计那套把戏都比较熟悉来了。
so lets begin
卷积神经网络
哈哈你也许被傅立叶变换里那个卷积公式给混淆了,这个卷积和那个屁关系都没有。
其实就是一个叫做卷积核(Kernel)的矩阵,这个核和它想识别的特征作积所得的实数结果就会很大,从某种程度上说,不严格的说,是个滤波器。
比如下图是卷积核的可视化:

池化
你可以把它和卷积并行起来理解,虽然不同,但是他们的关系就像哪吒和红孩儿(莫名其妙的相似… …)
池化层是对输入的特征图进行压缩,一方面使特征图变小,简化网络计算复杂度;一方面进行特征压缩,提取主要特征。她的假设在于,图像中相邻位置的像素是相关的。
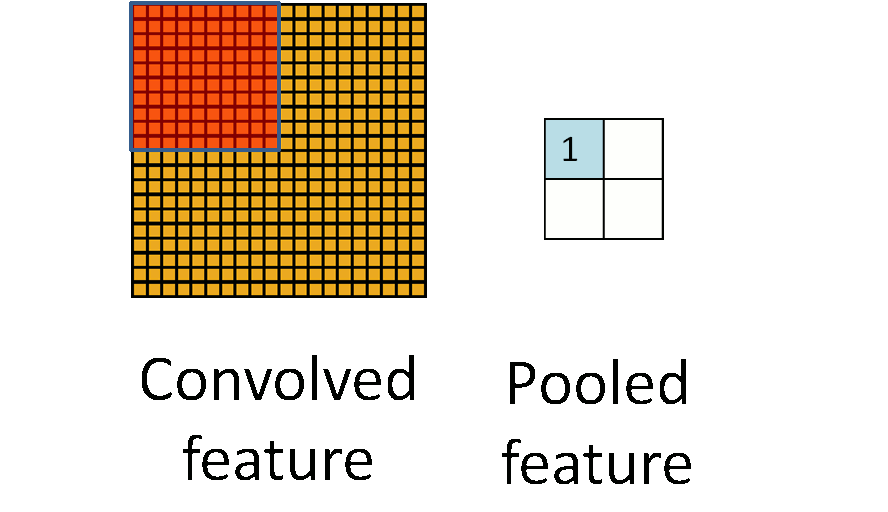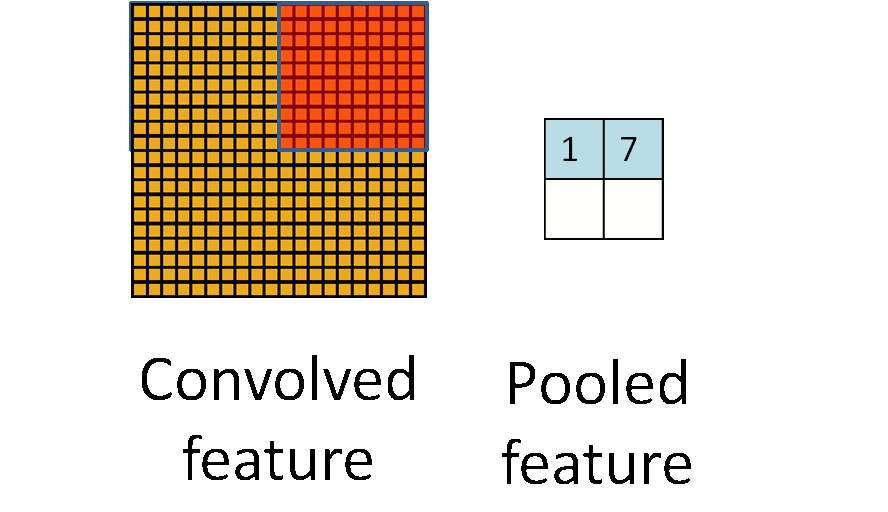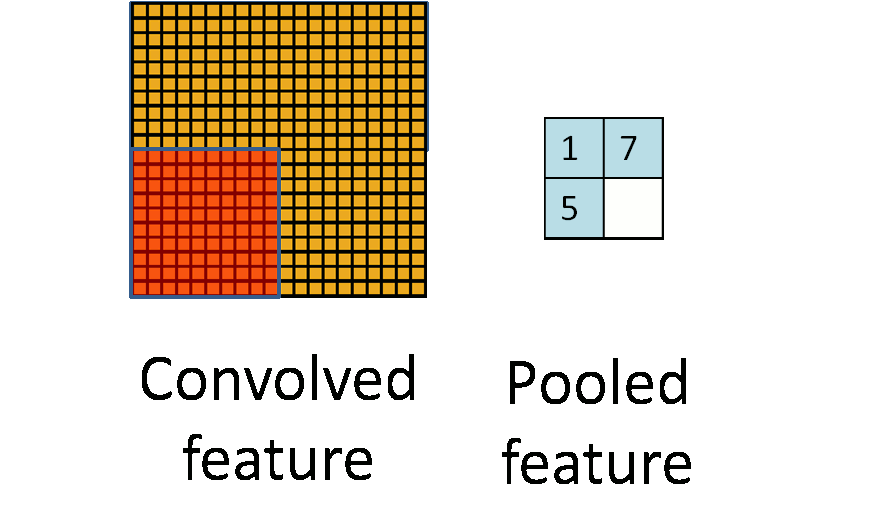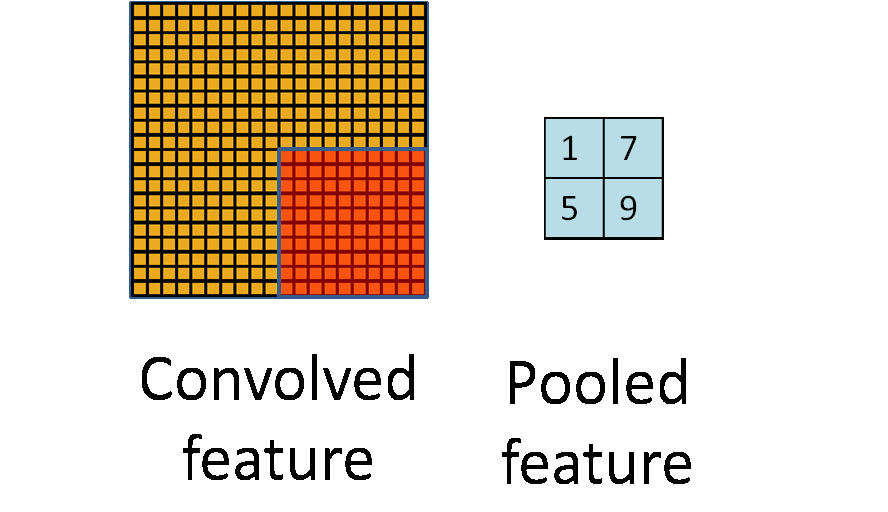
LSTM
神经网络本来是一个万能拟合器,现在我们需要处理一种时间序列模型,比如,股票价格数据,是一个高密度的时间序列数据,并且很明显上一时刻和下一时刻有关,还有自然语言也是。
所以不得不先说RNN:Recurrent Neural Networks

可以看见
时刻的网络
有两个输入即:
但是RNN对长期依赖的模式的学习不太好,主要是长链条的学习会导致的大梯度和高复杂计算不太现实。
Long Short Term 网络—— 一般就叫做 LSTM ——是一种 RNN 特殊的类型,可以学习长期依赖信息。LSTM 由Hochreiter & Schmidhuber (1997)提出,并在近期被Alex Graves进行了改良和推广。在很多问题,LSTM 都取得相当巨大的成功,并得到了广泛的使用。

所以LSTM其实就是加了几个非线性门,每个门其实是一个小的神经网络,这样的一个A叫做一个LSTM单元。
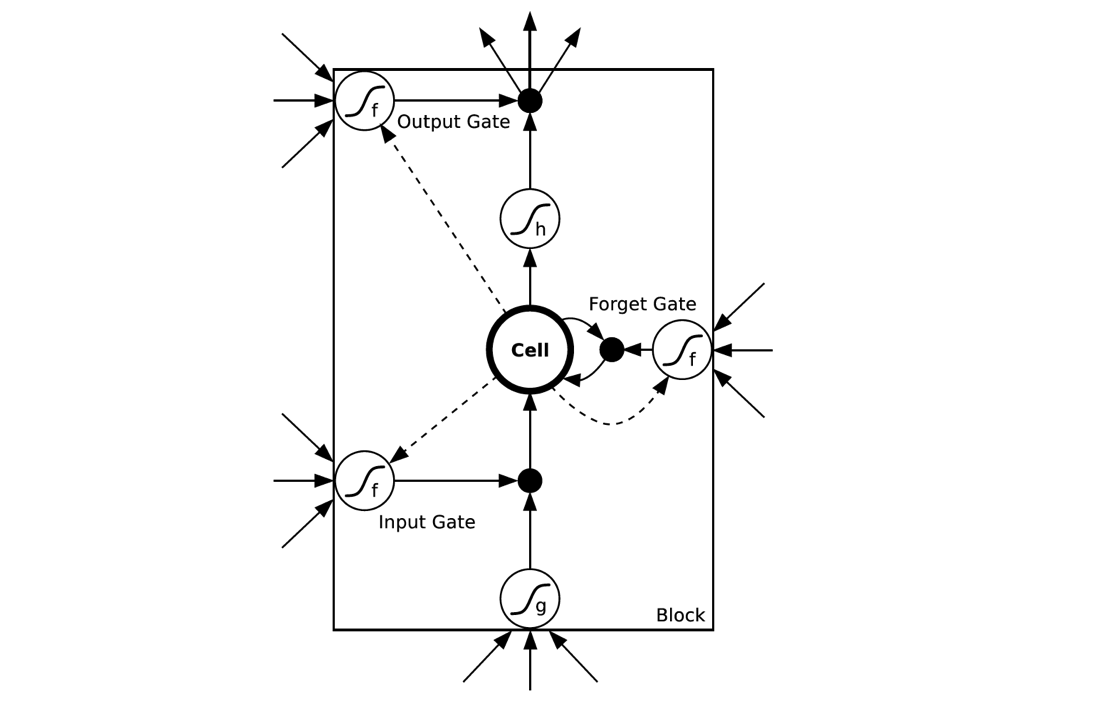
LSTM的反向传播算法
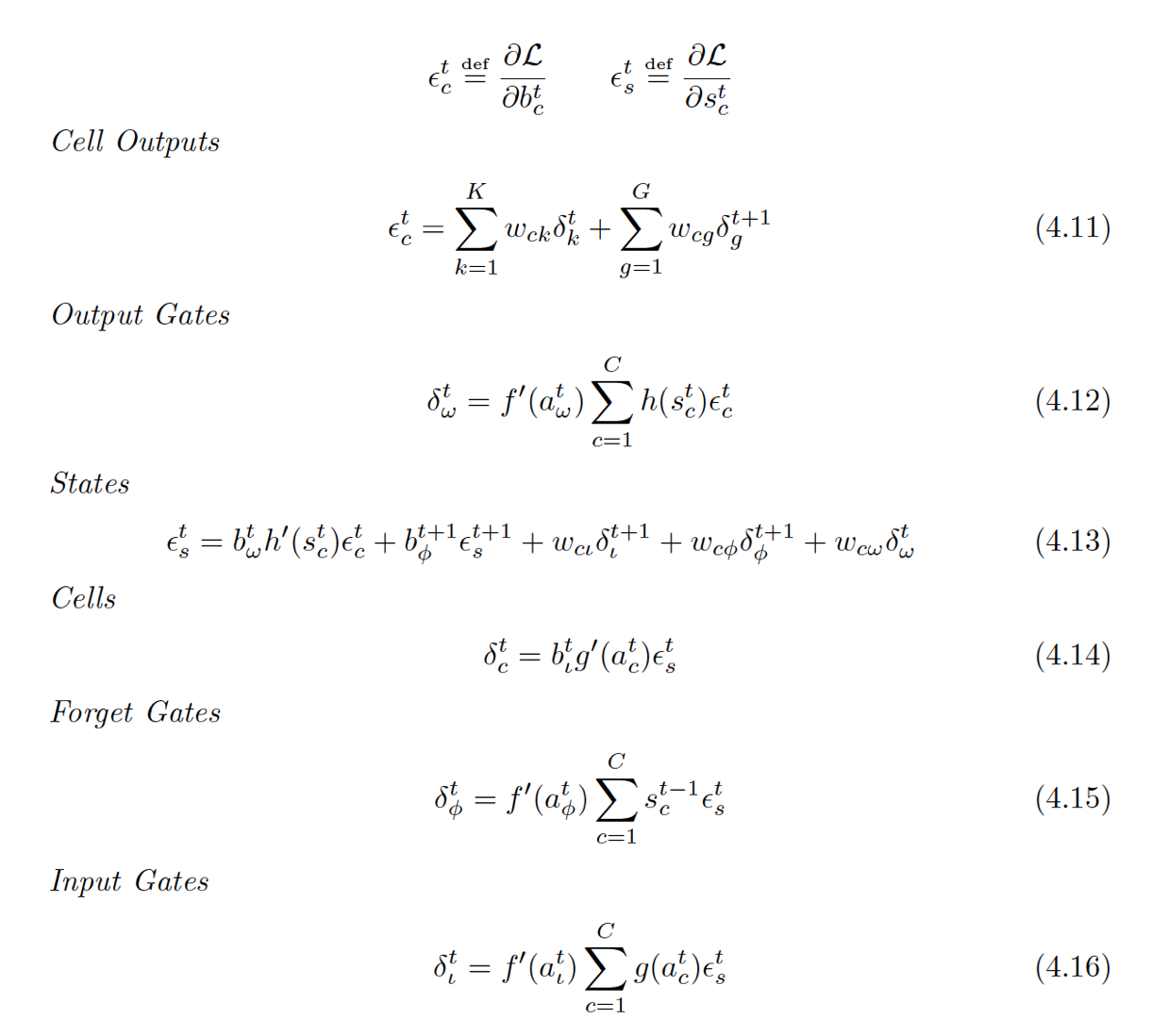
VAE
我真的不是在说什么许嵩。。。我们谈及的是ariational Auto-Encoder,变分自编码器。其实自编码器就是将样本通过编码器生成为一个特征向量,解码器就是将这个特征向量解码为原来的样本。这和密码学里的加密解密很相似。
这里的编码器和解码器都各自是一个神经网络
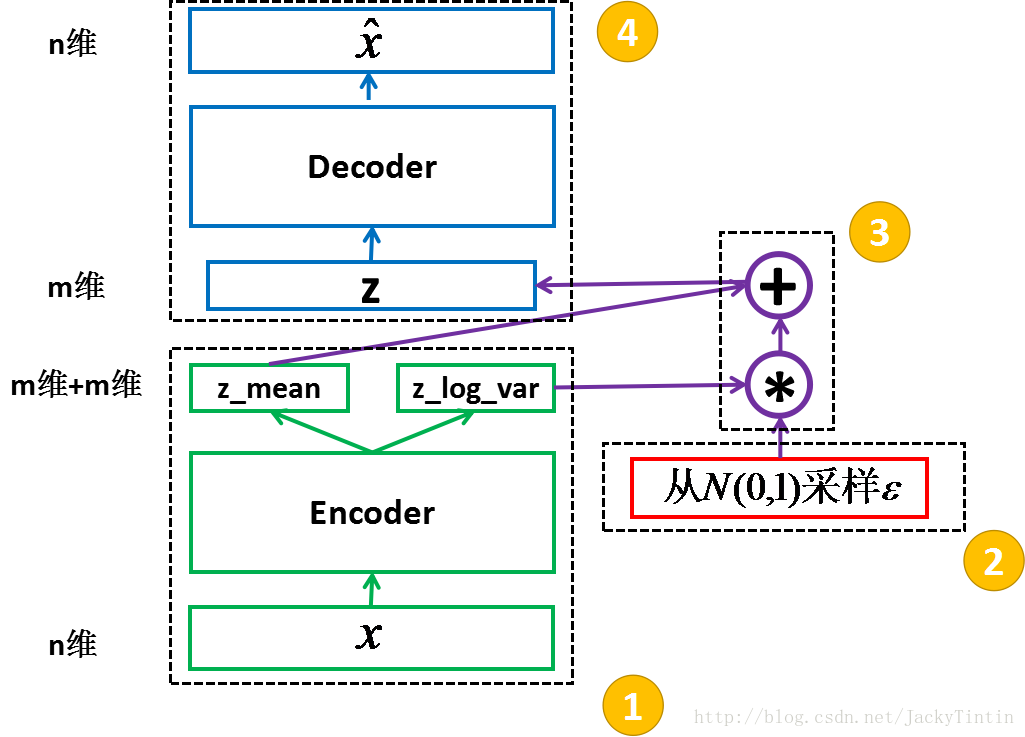
注意了,变分自编码器的思想是大红大紫的GAN的基础,思考,当我们从样本
生成编码
的时候,我们同时训练解码器使其由
生成
,最小化
.最后我们去掉编码器,此时的
就已经有实际的表达意义了!它的改变再加上解码器来工作就可以生成假样本
。
改变
时,数字样本的方向也发生改变,说明
蕴含了这个特征:

你是否疑惑,为啥叫变分?
我们的目标是
,而:
而 很难算,我们用
来替代计算,此处不详谈。无论 还是 都是神经网络。
GAN
对抗神经网络,大名鼎鼎。其原理不需多言,就是一个生成器(编码器)和一个判别器,注意其训练是生成器和判别器交替优化(交替做梯度更新)

还有就是一开始生成器目标项
的梯度下降极慢,所以一开始是对
作梯度更新来逼近
接近1的地方。

强化学习
强化学习吸收了Markov链的思想,事实上如果你熟悉深度学习你会发现很多模型都和Markov链有或多或少的关系。它把学习模型抽象成了一个代理者,和环境的形式。
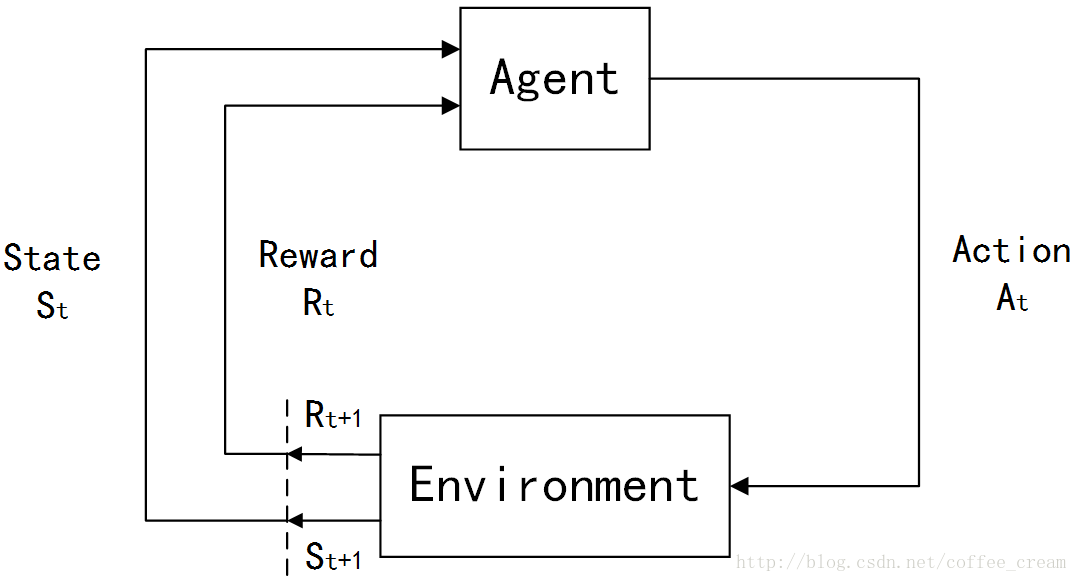
环境给予代理状态值和奖励值,代理给予环境动作值。我认为代理很像玩游戏的玩家,而环境则如同游戏机。这样理解似乎很合理,事实上强化学习模型还真的是被广泛用来训练玩游戏,还有围棋(AlphaGo)。
我就直接谈其最终形式了:
其中 描述量化了 即状态 时采取行动 有多好,而 描述了状态 时情况有多好。