大数据技术原理与应用——大数据处理架构 Hadoop
1.概述
(1)Hadoop 简介
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台,为用户提供了系统底层细节透明的分布式基础架构
Hadoop是基于Java语言开发的,具有很好的跨平台特性,并且可以部署在廉价的计算机集群中
Hadoop的核心是分布式文件系统HDFS(Hadoop Distributed File System) 和 MapReduce
(2)Hadoop 发展简史
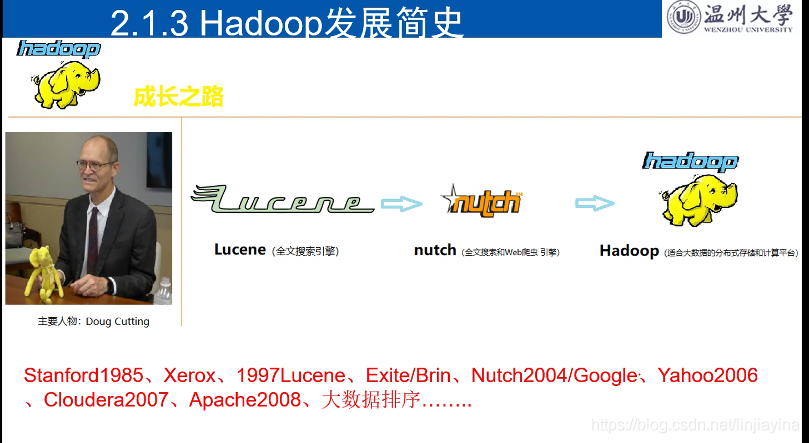
2008年1月,Hadoop正式成为Apache顶级项目,Hadoop也逐渐开始被雅虎之外的其他公司使用。
2008年4月,Hadoop打破世界纪录,成为最快排序1TB数据的系统,它采用一个由910个节点构成的集群进行运算,排序时间只用了209秒。
2009年5月,Hadoop更是把1TB数据排序时间缩短到62秒。Hadoop从此声名大噪,迅速发展成为大数据时代最具影响力的开源分布式开发平台,并成为事实上的大数据处理标准。
(3)Hadoop 的特性
Hadoop是一个能够对大量数据进行分布式处理的软件框架,并且是以一种可靠、高效、可伸缩的方式进行处理的,它具有以下几个方面的特性:
高可靠性——采用冗余数据存储方式,即使一个副本发生故障,其他副本也可以保证正常对外提供服务。
高效性——作为并行分布式计算平台,Hadoop 采用分布式存储和分布式处理两大核心技术,能够高效地处理 PB 级数据。
高可扩展性—— Hadoop 的设计目标是可以高效稳定地运行在廉价的计算机集群上,可以扩展到数以千计的计算机节点上。
高容错性——采用冗余数据存储方式,自动保存数据的多个副本,并且能够自动将失败的任务进行重新分配。
成本低—— Hadoop 采用廉价的计算机集群,成本比较低,普通用户也很容易用自己的 PC 搭建 Hadoop 运行环境。
运行在 Linux 平台上—— Hadoop 是基于 Java 语言开发的,可以较好地运行在 Linux 平台上。
支持多种编程语言—— Hadoop 上的应用程序也可以使用其他语言编写,如 C++。
(4)Hadoop 的应用现状
Hadoop凭借其突出的优势,已经在各个领域得到了广泛的应用(如银行、电信公司、大型零售商等),而互联网领域是其应用的主阵地
几乎所有主流厂商都围绕Hadoop提供开发工具、开源软件、商业化工具和技术服务
早期的Yahoo!(搜索引擎)、Facebook(数据仓库/关系分析)、eBay、Linkedln等公司,后来的Intel、微软、思科等;国内早期开始的:华为、淘宝、百度、阿里、网易、中移动等
形成一个大的圈子——>
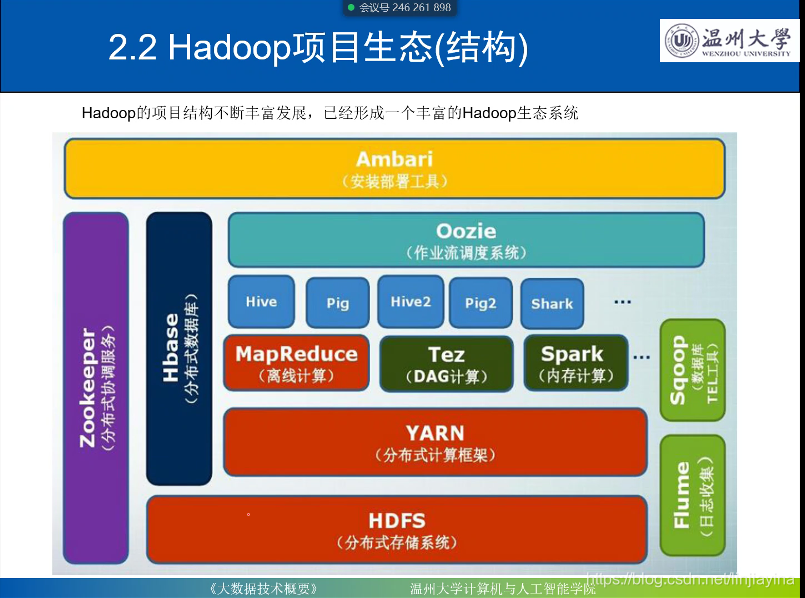
2.Hadoop项目结构

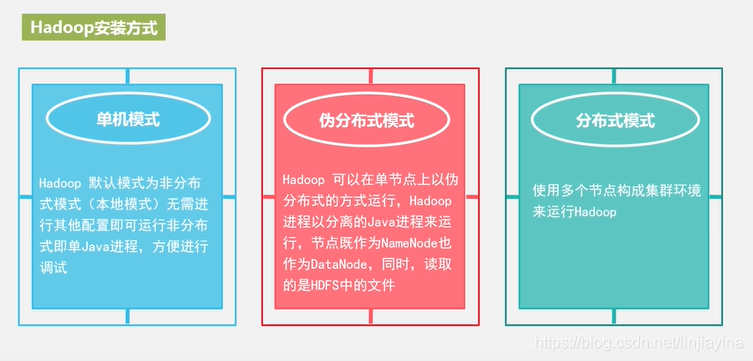
3.Hadoop的安装与使用
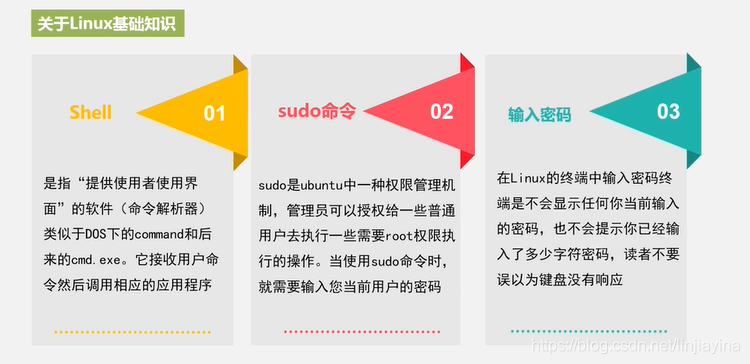
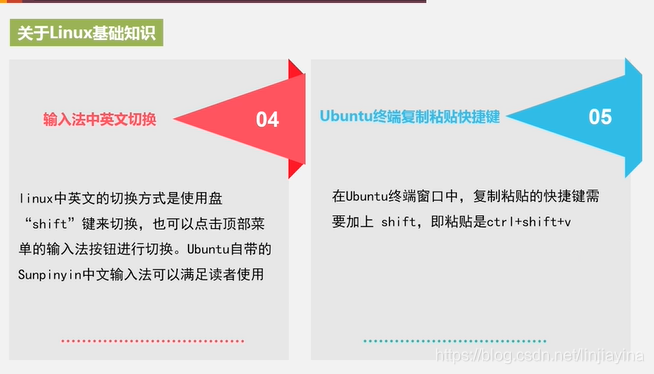
Hadoop安装之前的预备知识


安装虚拟机



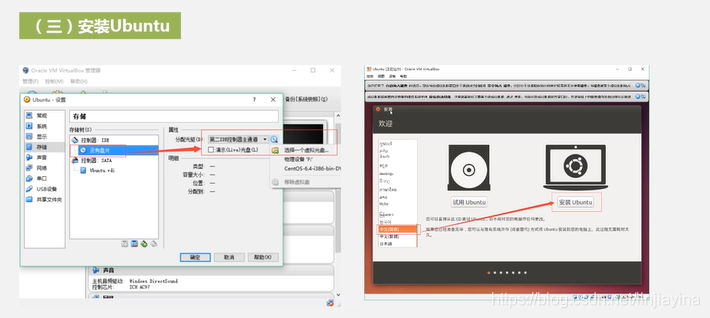
安装双系统

安装后Window和Ubuntu 14.04都可以用,默认windows优先启动,可以在电脑启动时,选择进入Ubuntu系统而不是Windows系统。
Hadoop的安装与使用

创建hadoop用户

SSH登录权限设置

安装JAVA环境

单机安装配置


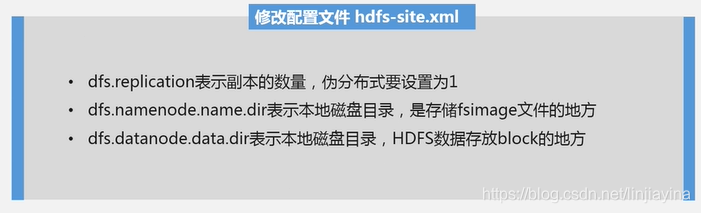
伪分布式安装配置





4.Hadoop集群的部署和使用
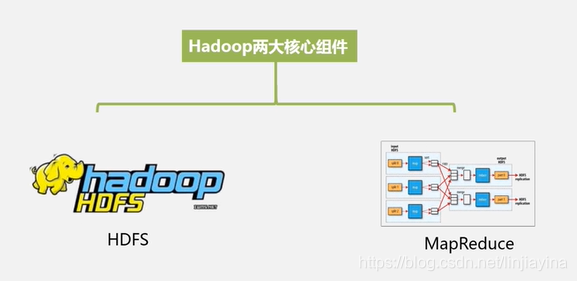
Hadoop两大核心组件
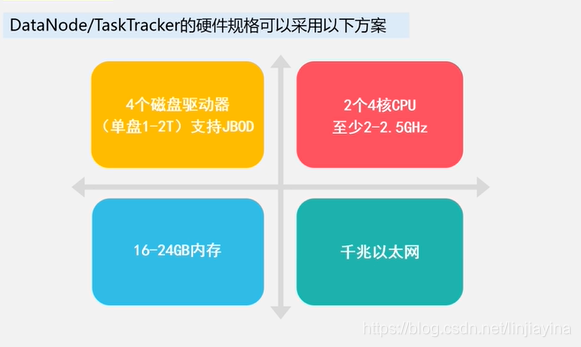
集群硬件配置
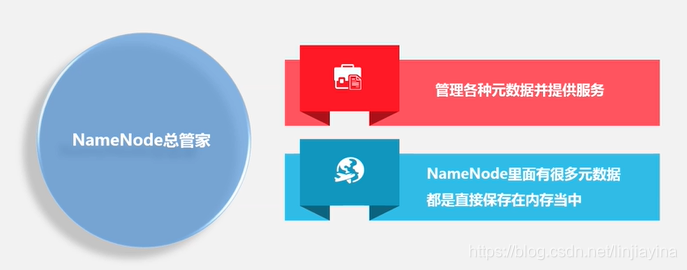
1.NameNode
2.DataNode

MapReduce两大核心组件
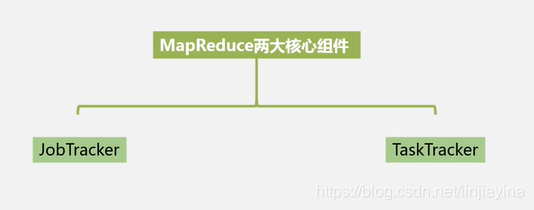
我们在做MapReduce应用程序开发时,每一次都是以MapReduce作业的形式去完成具体计算任务的,而JobTracker相当于一个管家,每次都由它对整个用户的作业进行管理,它会把整个用户大的作业拆分成很多小作业,分发到不同机器上去执行,然后JobTracker去协调不同的机器执行,不同的机器上面安装了TaskTracker,TaskTracker部署在不同的机器上,每一个TaskTracker负责跟踪和执行分配给自己的那一小部分作业。
冷备份 SecondaryNameNode
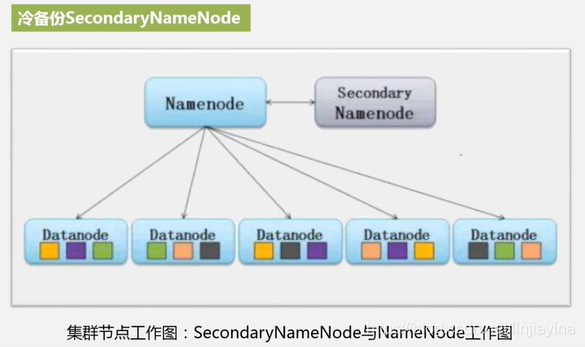
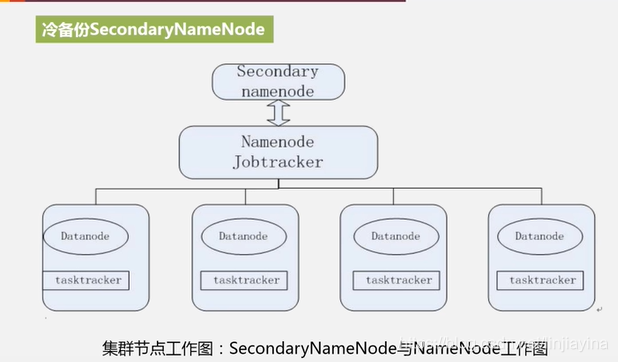
热备定义
一旦NameNode出问题,SecondaryNameNode马上顶上来。
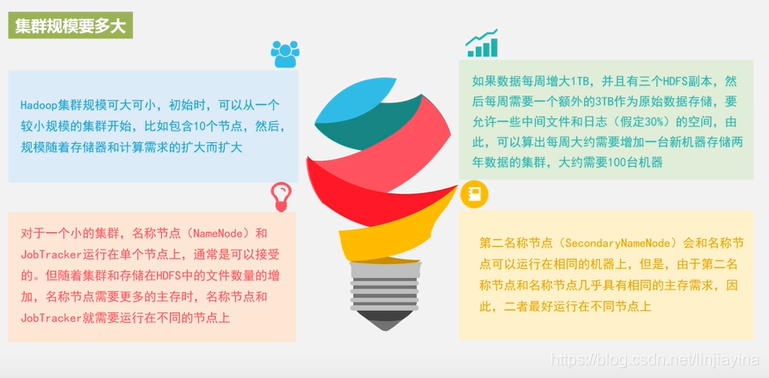
集群规模要多大
1.Hadoop集群规模可大可小,初始时,可以从一个较小规模的集群开始,比如包含10个节点,然后,规模随着存储器和计算需求的扩大而扩大。
2.如果数据每周增大1TB,并且有三个HDFS副本,然后每周需要一个额外的3TB作为原始数据存储,要允许一些中间文件和日志(假定30%)的空间,由此,可以算出每周大约需要增加一台新机器存储两年数据的集群,大约需要100台机器。
3.对于一个小的集群,名称节点(NameNode)和JobTracker运行在单个节点上,通常是可以接受的。但随着集群和存储在HDFS中的文件数量的增加,名称节点需要更多的主存时,名称节点JobTracker就需要运行在不同的节点上。
4.第二名称节点(Secondary NameNode)会和名称节点可以运行在相同的机器上,但是,由于第二名称节点和名称节点几乎具有相同的主存需求,因此,二者最好运行在不同节点上。
Hadoop集群基准测试
1.Hadoop自带有一些基准测试程序,被打包在测试程序JAR文件中
2.用TestDFSIO基准测试,来测试HDFS的IO性能
3.用排序测试MapReduce:Hadoop自带一个部分排序的程序,这个测试过程的整个数据集都会通过洗牌(Shuffle)传输至Reducer,可以充分测试MapReduce的性能
在云计算环境中使用Hadoop