import pandas as pd
import jieba
#pip install jieba
数据源:
http://www.sogou.com/labs/resource/ca.php
df_news = pd.read_table('./data/val.txt',names=['category','theme','URL','content'],encoding='utf-8')
df_news = df_news.dropna()
df_news.head()

df_news.shape

分词:使用结吧分词器
# 结吧分词器要求使用list格式
content = df_news.content.values.tolist()
print (content[1000])

进行分词:
content_S = []
for line in content:
current_segment = jieba.lcut(line)
if len(current_segment) > 1 and current_segment != '\r\n': #换行符
content_S.append(current_segment)
content_S[1000]

df_content=pd.DataFrame({'content_S':content_S})
df_content.head()

清洗
stopwords=pd.read_csv("stopwords.txt",index_col=False,sep="\t",quoting=3,names=['stopword'], encoding='utf-8')
stopwords.head(20)

def drop_stopwords(contents,stopwords):
contents_clean = []
all_words = []
for line in contents:
line_clean = []
for word in line:
if word in stopwords:
continue
line_clean.append(word)
all_words.append(str(word))
contents_clean.append(line_clean)
return contents_clean,all_words
#print (contents_clean)
contents = df_content.content_S.values.tolist()
stopwords = stopwords.stopword.values.tolist()
contents_clean,all_words = drop_stopwords(contents,stopwords)
#df_content.content_S.isin(stopwords.stopword)
#df_content=df_content[~df_content.content_S.isin(stopwords.stopword)]
#df_content.head()
df_content=pd.DataFrame({'contents_clean':contents_clean})
df_content.head()

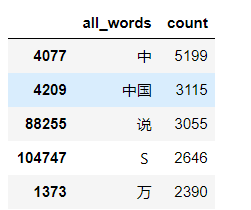
df_all_words=pd.DataFrame({'all_words':all_words})
df_all_words.head()

words_count=df_all_words.groupby(by=['all_words'])['all_words'].agg({"count":numpy.size})
words_count=words_count.reset_index().sort_values(by=["count"],ascending=False)
words_count.head()
from wordcloud import WordCloud
import matplotlib.pyplot as plt
%matplotlib inline
import matplotlib
matplotlib.rcParams['figure.figsize'] = (10.0, 5.0)
wordcloud=WordCloud(font_path="./data/simhei.ttf",background_color="white",max_font_size=80)
word_frequence = {x[0]:x[1] for x in words_count.head(100).values}
wordcloud=wordcloud.fit_words(word_frequence)
plt.imshow(wordcloud)

TF-IDF :提取关键词
import jieba.analyse
index = 2400
print (df_news['content'][index])
content_S_str = "".join(content_S[index])
print (" ".join(jieba.analyse.extract_tags(content_S_str, topK=5, withWeight=False)))

LDA :主题模型
格式要求:list of list形式,分词好的的整个语料
from gensim import corpora, models, similarities
import gensim
#http://radimrehurek.com/gensim/
#做映射,相当于词袋
dictionary = corpora.Dictionary(contents_clean)
corpus = [dictionary.doc2bow(sentence) for sentence in contents_clean]
lda = gensim.models.ldamodel.LdaModel(corpus=corpus, id2word=dictionary, num_topics=20) #类似Kmeans自己指定K值
#4号分类结果
print (lda.print_topic(4, topn=5))
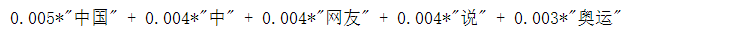
for topic in lda.print_topics(num_topics=20, num_words=5):
print (topic[1])

使用贝叶斯算法进行新闻分类
df_train=pd.DataFrame({'contents_clean':contents_clean,'label':df_news['category']})
df_train.tail()

df_train.label.unique()

label_mapping = {"汽车": 1, "财经": 2, "科技": 3, "健康": 4, "体育":5, "教育": 6,"文化": 7,"军事": 8,"娱乐": 9,"时尚": 0}
df_train['label'] = df_train['label'].map(label_mapping)
df_train.head()

from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(df_train['contents_clean'].values, df_train['label'].values, random_state=1)
#x_train = x_train.flatten()
x_train[0][1]

words = []
for line_index in range(len(x_train)):
try:
#x_train[line_index][word_index] = str(x_train[line_index][word_index])
words.append(' '.join(x_train[line_index]))
except:
print (line_index,word_index)
words[0]

print (len(words))

举个栗子
from sklearn.feature_extraction.text import CountVectorizer
texts=["dog cat fish","dog cat cat","fish bird", 'bird']
cv = CountVectorizer()
cv_fit=cv.fit_transform(texts)
print(cv.get_feature_names())
print(cv_fit.toarray())
print(cv_fit.toarray().sum(axis=0))
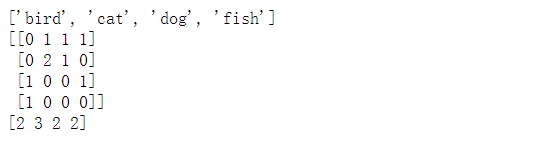
from sklearn.feature_extraction.text import CountVectorizer
texts=["dog cat fish","dog cat cat","fish bird", 'bird']
cv = CountVectorizer(ngram_range=(1,4))
cv_fit=cv.fit_transform(texts)
print(cv.get_feature_names())
print(cv_fit.toarray())
print(cv_fit.toarray().sum(axis=0))

from sklearn.feature_extraction.text import CountVectorizer
vec = CountVectorizer(analyzer='word', max_features=4000, lowercase = False)
vec.fit(words)

from sklearn.naive_bayes import MultinomialNB
classifier = MultinomialNB()
classifier.fit(vec.transform(words), y_train)

test_words = []
for line_index in range(len(x_test)):
try:
#x_train[line_index][word_index] = str(x_train[line_index][word_index])
test_words.append(' '.join(x_test[line_index]))
except:
print (line_index,word_index)
test_words[0]

classifier.score(vec.transform(test_words), y_test)

from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(analyzer='word', max_features=4000, lowercase = False)
vectorizer.fit(words)

from sklearn.naive_bayes import MultinomialNB
classifier = MultinomialNB()
classifier.fit(vectorizer.transform(words), y_train)
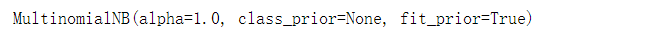
classifier.score(vectorizer.transform(test_words), y_test)

