面试被问到过很多次,遂总结一下!!!
工作中相信很多人在设计数据库表时其实都或多或少的遵循了三范式和反三范式的设计规则,但是有些东西就是这样,它明明在你面前,你却不知道它就是它!!!
1 三范式
将如下表按照三范式进行重新设计。
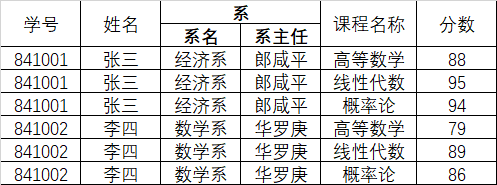
1.1 第一范式(1NF)
数据库表的每一列都是不可分割的原子数据项。
为了满足第一范式,系这个列应该拆分为系名和系主任两个列,在实际工作中我们也会经常碰到这种情况,比如说地址常常拆分成省、市、区/县。。。 这样可以使数据使用起来更灵活。
| 学号 | 姓名 | 系名 | 系主任 | 课程名称 | 分数 |
|---|---|---|---|---|---|
| 841001 | 张三 | 经济系 | 郎咸平 | 高等数学 | 88 |
| 841001 | 张三 | 经济系 | 郎咸平 | 线性代数 | 95 |
| 841001 | 张三 | 经济系 | 郎咸平 | 概率论 | 94 |
| 841002 | 李四 | 数学系 | 华罗庚 | 高等数学 | 79 |
| 841002 | 李四 | 数学系 | 华罗庚 | 线性代数 | 89 |
| 841002 | 李四 | 数学系 | 华罗庚 | 概率论 | 86 |
上诉表存在的问题:
- 存在非常严重的数据冗余:学号、姓名、系别、系主任
- 数据添加存在问题:添加新开设的系和系主任时,数据不合法
- 数据删除存在问题:张三同学毕业了,删除数据,会将系的数据一起删除
1.2 第二范式(2NF)
在1NF的基础上,非码属性必须完全依赖于码 (在1NF基础上消除非主属性对码的部分函数依赖)
几个概念:
- 函数依赖: A --> B。如果通过A属性(属性组)的值,可以唯一确定B属性的值, 则称B依赖于A。
- 例如:学号–>姓名。(学号,课程名称) --> 分数
- 完全函数依赖: A --> B。如果A是一个属性组,B属性值的确定依赖于A属性组中所有的属性值。
- 例如: (学号, 课程名称) --> 分数
- 部分函数依赖: A --> B。如果A是一个属性组,B属性值的确定只需要依赖于A属性组中某一些值即可。
- 例如:(学号,课程名称) – > 姓名
- 传递函数依赖: A --> B,B --> C。如果通过A属性(属性组)的值,可以唯一确定B属性的值,再通过B属性(属性组)的值可以唯一确定C属性的值,则称C传递函数依赖于A。
- 例如:学号–>系名,系名–>系主任
- 码: 如果在一张表中, 一个属性或属性组,被其他所有属性所完全依赖,则称这个属性性(属性组)为该表的码
- 例如:1.1表中的码为: (学号, 课程名称)
- 主属性: 码属性组中的所有属性
- 非主属性: 除去码属性组的属性
表1.1种的码为 (学号, 课程名称),除了分数完全依赖于码以外,其他属性都是非完全依赖。表拆分后如下:
- 课程分数表
| 学号 | 课程名称 | 分数 |
|---|---|---|
| 841001 | 高等数学 | 88 |
| 841001 | 线性代数 | 95 |
| 841001 | 概率论 | 94 |
| 841002 | 高等数学 | 79 |
| 841002 | 线性代数 | 89 |
| 841002 | 概率论 | 86 |
- 学生表
| 学号 | 姓名 | 系名 | 系主任 |
|---|---|---|---|
| 841001 | 张三 | 经济系 | 郎咸平 |
| 841002 | 李四 | 数学系 | 华罗庚 |
上诉表存在的问题:
- 数据添加存在问题:添加新开设的系和系主任时,数据不合法
- 数据删除存在问题:张三同学毕业了,删除数据,会将系的数据一起删除
1.3 第三范式(3NF)
在2NF的基础上,任何非主属性不依赖于其他非主属性(在2NF的基础上消除传递依赖)
学号–>系名,系名–>系主任间 存在传递依赖,继续对表进行拆分,如下:
- 课程分数表
| 学号 | 课程名称 | 分数 |
|---|---|---|
| 841001 | 高等数学 | 88 |
| 841001 | 线性代数 | 95 |
| 841001 | 概率论 | 94 |
| 841002 | 高等数学 | 79 |
| 841002 | 线性代数 | 89 |
| 841002 | 概率论 | 86 |
- 学生表
| 学号 | 姓名 | 系名 |
|---|---|---|
| 841001 | 张三 | 经济系 |
| 841002 | 李四 | 数学系 |
- 系表
| 系名 | 系主任 |
|---|---|
| 经济系 | 郎咸平 |
| 数学系 | 华罗庚 |
2 范式化设计 、反范式化设计优缺点简析
- 反范式化是针对范式化而言得
- 反范式化是为了性能和读取效率的考虑而适当的对数据库设计范式的要求进行违反,允许存在少量的冗余
- 换句话来说反范式化就是使用空间来换取时间
范式化设计优缺点:
优点:
- 可以尽量得减少数据冗余
- 范式化的更新操作比反范式化更快
- 范式化的表通常比反范式化的表更小
缺点:
- 对于查询需要对多个表进行关联
- 更难进行索引优化
反范式化设计优缺点:
优点:
- 可以减少表的关联
- 可以更好的进行索引优化
缺点:
- 存在数据冗余及数据维护异常
- 对数据的修改需要更多的成本
