课程内容
- 符号的介绍
- 模仿学习(imitate learning)
符号

符号含义这里不再赘述,这里需要注意的是:state与observation的区别。正如课堂中老师所说:
The state is actually the sufficient kind of summary of what‘s going on in the world.
The observation is a consequence of state but it might be a lossy consequence.
状态就是对当前环境的完全描述,对于人类来说,还包含了人对物理世界的理解,如下图所示,状态包含的不仅仅是像素还有对动物运动的分析等等;而观察得到的就是图片像素,相当于状态的序列子集,如果是观察的信息少于状态,那就是不完全观察,否则就是完全观察。
如果完全观察,动作可以仅由当前状态决定,相当于马尔科夫链。(eg:Q学习)
如果是不完全观察,那么当前的观察结合前一个时间的观察,由此作出的决策会更好。(eg:模仿学习)
举一个栗子,来更形象地解释:

☺豹子追逐羚羊,如果图片中的豹子被小汽车遮挡住,那就是不完全观察,由于不完全观察,不知道豹子是否存在于环境中,故不知道羚羊是否应该逃跑,在当前判断中,如果结合着前一时刻小汽车没有遮挡豹子的观察,就可以推测豹子现在的位置,帮助判断羚羊是否应该逃跑。
模仿学习
【英伟达NVIDIA自动驾驶小车】

使得小汽车平稳驾驶的主要因素之一:小汽车有三个摄像头装在左侧、中间、右侧,当左侧摄像头观察到的视野偏左时,小汽车方向盘向右转动;右侧摄像头同理。以此来达到校正目的。这种方法虽然不具有普适性,但是它告诉我们:纠正误差很重要!
【行车轨迹】

图中黑色线是训练时得到的轨迹;红色线是模仿得到的轨迹。导致偏离原始路线的原因是:在模仿过程中遇到了训练过程中没有遇到的状态,无法做出正确的判断,这些没有遇到的状态很大程度上有随机误差产生。

解决该问题的方法:通过引入不同误差,人为解决误差产生后的解决方法,将这些数据作为训练样本。人工标注数据的方法有些笨拙,可以使用能够规划的算法代替人工。
DAgger算法
DAgger算法全称:dataset aggregation(数据集聚合),解决了分布不匹配的问题。

希望训练数据的分布与模拟的分布相等!

目标:用模拟分布代替原始数据分布。
算法流程:
- 根据数据集D训练策略π
- 运行得到的策略π,得到只包含观察的数据集Dπ
- 人工标记Dπ中每个观察对应的行为
- 聚合:将D和Dπ组成新的D
- 再次执行第一步
这是一种on-line学习方式。算法在应用过程中遇到的问题:
- 不是所有问题都是马尔科夫行为
- 有些观察可能会对应多种行为选择
解决方法:
- 对于不全是马尔科夫行为的问题
(马尔科夫行为就是,当前的行为选择至于当前的状态有关。对此,一种标准的前向神经网络通常仅依赖于当前观察数据的图像分类问题,即通过前向神经网络即可解决。)
针对不仅仅是当前的数据,可以采用递归神经网络(RNN)或者长短时记忆模型(LSTM)处理。 - 多行为选择的问题
从离散和连续两个角度分析:
对于离散问题:softmax放在网络结构的最后。
对于连续问题:
(1)output mixture of Gaussians(高斯混合输出):低维有效。输出的是N个均值、N个方差、以及对所有项的标量权重。如图,混合密度网络。

(2)latent variable models(隐变量模型):数学形式好。输出仍然是简单的高斯分布,在输入端给神经网络随机源

神经网络有效利用噪声的参考:

(3)autoregressive discretization(自动回归离散化):使用简单。离散化高维的连续变量,会导致维数灾难。这种方法一次只离散化一个维度,以避免维数灾难。(eg:假设有五个行为决策,首先对第一个行为决策离散化,并使用softmax,然后分布采样,得到行为决策的第一个维度的结果。然后给剩余的神经网络这个离散化的采样,然后让它结合从第一个维度的所有采样以及第二个维度的条件来预测一个离散化的结果,之后只要重复这个过程就可以了。)

cost function 与 reward function
由下图可以发现,cost function和reward function是在不同领域的两种定义,二者互为相反数。

在模仿学习中,reward function(或者cost function)的几种常见的定义:
损失函数可以衡量现实与期望的差距,对于上面的【行车轨迹】问题,就是红线与黑线的差距。
- 定义奖赏函数为符合专家行为的对数概率:
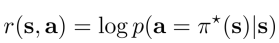
- 定义成和0-1损失函数类似的样子:
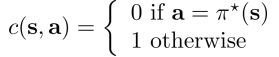
DAgger可以用来最小化损失函数。在实际问题中,存在许多不确定因素,假设如果遇到和训练集相同的状态,学习后的犯错率为ε,而当遇到训练集中没有包含的状态时,学习后的犯错率就不能是ε了!!在此使用DAgger,使得:
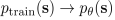
这样,由下图所示,状态只要符合相同的分布即可,不需要严格属于训练集。而对于也不服从分布的情况,后续讨论。

相关论文


资源参考
课程官网:http://rail.eecs.berkeley.edu/deeprlcourse/
观看全部中英双语课程:https://ai.yanxishe.com/page/groupDetail/30?from=bilibili
伯克利大学 CS 294-112 《深度强化学习》为官方开源最新版本,由伯克利大学该门课程授课讲师 Sergey Levine 授权 AI 研习社翻译。添加字幕君微信:leiphonefansub 拉你入学习小组。更多经典课程在 ai.yanxishe.com
感谢字幕组的翻译!
