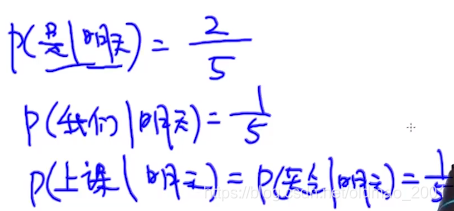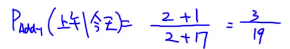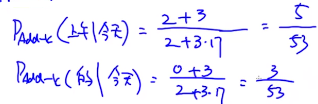公式输入请参考:
在线Latex公式
语言模型用来判断:是否一句话从语法上通顺
p
L
M
(
今
天
是
周
日
)
>
p
L
M
(
今
天
周
日
是
)
p_{LM}(今天是周日)>p_{LM}(今天周日是)
p L M ( 今 天 是 周 日 ) > p L M ( 今 天 周 日 是 )
p
L
M
(
全
民
A
I
是
趋
势
)
>
p
L
M
(
趋
势
全
民
A
I
是
)
p_{LM}(全民AI是趋势)>p_{LM}(趋势全民AI是)
p L M ( 全 民 A I 是 趋 势 ) > p L M ( 趋 势 全 民 A I 是 )
Compute the probability of a sentence or sequence of
p
(
s
)
=
p
(
w
1
,
w
2
,
w
3
,
w
4
,
w
5
⋯
w
n
)
(1)
p(s)=p(w_1, w_2,w_3,w_4, w_5\cdots w_n)\tag1
p ( s ) = p ( w 1 , w 2 , w 3 , w 4 , w 5 ⋯ w n ) ( 1 )
w
1
,
w
2
,
w
3
,
w
4
w_1, w_2,w_3,w_4
w 1 , w 2 , w 3 , w 4
Chain Rule推导在第一节 有,这里不重复了,根据Chain Rule,公式(1)可以写为:
p
(
s
)
=
p
(
w
1
,
w
2
,
w
3
,
w
4
,
w
5
⋯
w
n
)
=
p
(
w
1
)
p
(
w
2
∣
w
1
)
p
(
w
3
∣
w
1
w
2
)
p
(
w
4
∣
w
1
w
2
w
3
)
p
(
w
5
∣
w
1
w
2
w
3
w
4
)
⋯
p
(
w
n
∣
w
1
w
2
w
3
w
4
⋯
w
n
−
1
)
p(s)=p(w_1, w_2,w_3,w_4, w_5\cdots w_n)=p(w_1)p(w2|w_1)p(w_3|w_1w_2)p(w_4|w_1w_2w_3)p(w_5|w_1w_2w_3w_4)\cdots p(w_n|w_1w_2w_3w_4\cdots w_{n-1})
p ( s ) = p ( w 1 , w 2 , w 3 , w 4 , w 5 ⋯ w n ) = p ( w 1 ) p ( w 2 ∣ w 1 ) p ( w 3 ∣ w 1 w 2 ) p ( w 4 ∣ w 1 w 2 w 3 ) p ( w 5 ∣ w 1 w 2 w 3 w 4 ) ⋯ p ( w n ∣ w 1 w 2 w 3 w 4 ⋯ w n − 1 )
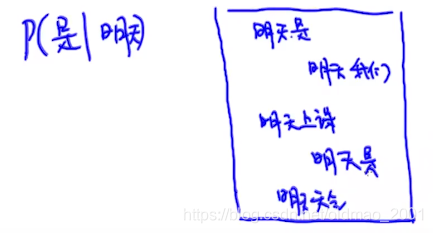
p
(
休
息
∣
今
天
,
是
,
春
节
,
我
们
,
都
)
=
1
2
p(休息|今天,是,春节,我们,都)=\cfrac{1}{2}
p ( 休 息 ∣ 今 天 , 是 , 春 节 , 我 们 , 都 ) = 2 1
p
(
运
动
∣
今
天
,
是
,
春
节
,
我
们
,
都
)
=
0
p(运动|今天,是,春节,我们,都)=0
p ( 运 动 ∣ 今 天 , 是 , 春 节 , 我 们 , 都 ) = 0
马尔科夫假设就是用来近似的计算上面的概率的。
p
(
休
息
∣
今
天
,
是
,
春
节
,
我
们
,
都
)
=
p
(
休
息
∣
都
)
p(休息|今天,是,春节,我们,都)=p(休息|都)
p ( 休 息 ∣ 今 天 , 是 , 春 节 , 我 们 , 都 ) = p ( 休 息 ∣ 都 )
p
(
休
息
∣
今
天
,
是
,
春
节
,
我
们
,
都
)
=
p
(
休
息
∣
我
们
,
都
)
p(休息|今天,是,春节,我们,都)=p(休息|我们,都)
p ( 休 息 ∣ 今 天 , 是 , 春 节 , 我 们 , 都 ) = p ( 休 息 ∣ 我 们 , 都 )
p
(
休
息
∣
今
天
,
是
,
春
节
,
我
们
,
都
)
=
p
(
休
息
∣
春
节
,
我
们
,
都
)
p(休息|今天,是,春节,我们,都)=p(休息|春节,我们,都)
p ( 休 息 ∣ 今 天 , 是 , 春 节 , 我 们 , 都 ) = p ( 休 息 ∣ 春 节 , 我 们 , 都 )
p
(
s
)
=
p
(
w
1
,
w
2
,
w
3
,
w
4
,
w
5
⋯
w
n
)
=
p
(
w
1
)
p
(
w
2
∣
w
1
)
p
(
w
3
∣
w
2
)
p
(
w
4
∣
w
3
)
p
(
w
5
∣
w
4
)
⋯
p
(
w
n
∣
w
n
−
1
)
=
p
(
w
1
)
∏
i
=
2
n
(
w
i
∣
w
i
−
1
)
p(s)=p(w_1, w_2,w_3,w_4, w_5\cdots w_n)=p(w_1)p(w2|w_1)p(w_3|w_2)p(w_4|w_3)p(w_5|w_4)\cdots p(w_n|w_{n-1})\\ =p(w_1)\prod_{i=2}^n(w_i|w_{i-1})
p ( s ) = p ( w 1 , w 2 , w 3 , w 4 , w 5 ⋯ w n ) = p ( w 1 ) p ( w 2 ∣ w 1 ) p ( w 3 ∣ w 2 ) p ( w 4 ∣ w 3 ) p ( w 5 ∣ w 4 ) ⋯ p ( w n ∣ w n − 1 ) = p ( w 1 ) i = 2 ∏ n ( w i ∣ w i − 1 )
p
(
s
)
=
p
(
w
1
,
w
2
,
w
3
,
w
4
,
w
5
⋯
w
n
)
=
p
(
w
1
)
p
(
w
2
∣
w
1
)
p
(
w
3
∣
w
1
w
2
)
p
(
w
4
∣
w
2
w
3
)
p
(
w
5
∣
w
3
w
4
)
⋯
p
(
w
n
∣
w
n
−
1
)
=
p
(
w
1
)
p
(
w
2
∣
w
1
)
∏
i
=
3
n
(
w
i
∣
w
i
−
2
w
i
−
1
)
p(s)=p(w_1, w_2,w_3,w_4, w_5\cdots w_n)=p(w_1)p(w2|w_1)p(w_3|w_1w_2)p(w_4|w_2w_3)p(w_5|w_3w_4)\cdots p(w_n|w_{n-1})\\ =p(w_1)p(w_2|w_1)\prod_{i=3}^n(w_i|w_{i-2}w_{i-1})
p ( s ) = p ( w 1 , w 2 , w 3 , w 4 , w 5 ⋯ w n ) = p ( w 1 ) p ( w 2 ∣ w 1 ) p ( w 3 ∣ w 1 w 2 ) p ( w 4 ∣ w 2 w 3 ) p ( w 5 ∣ w 3 w 4 ) ⋯ p ( w n ∣ w n − 1 ) = p ( w 1 ) p ( w 2 ∣ w 1 ) i = 3 ∏ n ( w i ∣ w i − 2 w i − 1 )
p
(
s
)
=
p
(
w
1
,
w
2
,
w
3
,
w
4
,
w
5
⋯
w
n
)
=
p
(
w
1
)
p
(
w
2
∣
w
1
)
p
(
w
3
∣
w
1
w
2
)
p
(
w
4
∣
w
1
w
2
w
3
)
p
(
w
5
∣
w
2
w
3
w
4
)
⋯
p
(
w
n
∣
w
n
−
3
w
n
−
2
w
n
−
1
)
=
p
(
w
1
)
p
(
w
2
∣
w
1
)
p
(
w
3
∣
w
1
w
2
)
∏
i
=
4
n
(
w
i
∣
w
i
−
3
w
i
−
2
w
i
−
1
)
p(s)=p(w_1, w_2,w_3,w_4, w_5\cdots w_n)=p(w_1)p(w2|w_1)p(w_3|w_1w_2)p(w_4|w_1w_2w_3)p(w_5|w_2w_3w_4)\cdots p(w_n|w_{n-3}w_{n-2}w_{n-1})\\ =p(w_1)p(w_2|w_1)p(w_3|w_1w_2)\prod_{i=4}^n(w_i|w_{i-3}w_{i-2}w_{i-1})
p ( s ) = p ( w 1 , w 2 , w 3 , w 4 , w 5 ⋯ w n ) = p ( w 1 ) p ( w 2 ∣ w 1 ) p ( w 3 ∣ w 1 w 2 ) p ( w 4 ∣ w 1 w 2 w 3 ) p ( w 5 ∣ w 2 w 3 w 4 ) ⋯ p ( w n ∣ w n − 3 w n − 2 w n − 1 ) = p ( w 1 ) p ( w 2 ∣ w 1 ) p ( w 3 ∣ w 1 w 2 ) i = 4 ∏ n ( w i ∣ w i − 3 w i − 2 w i − 1 )
假如已知:
p
(
是
∣
今
天
)
=
0.01
p
(
今
天
)
=
0.002
p
(
周
日
∣
是
)
=
0.001
p
(
周
日
I
今
天
)
=
0.0001
p
(
周
日
)
=
0.02
p
(
是
∣
周
日
)
=
0.0002
p(是|今天)=0.01\\ p(今天)=0.002\\ p(周日|是)=0.001\\ p(周日I今天)=0.0001\\ p(周日)=0.02\\ p(是|周日)=0.0002
p ( 是 ∣ 今 天 ) = 0 . 0 1 p ( 今 天 ) = 0 . 0 0 2 p ( 周 日 ∣ 是 ) = 0 . 0 0 1 p ( 周 日 I 今 天 ) = 0 . 0 0 0 1 p ( 周 日 ) = 0 . 0 2 p ( 是 ∣ 周 日 ) = 0 . 0 0 0 2
p
(
今
天
是
周
日
)
>
p
(
今
天
周
日
是
)
p(今天是周日)>p(今天周日是)
p ( 今 天 是 周 日 ) > p ( 今 天 周 日 是 )
公式:
p
(
s
)
=
p
(
w
1
,
w
2
,
w
3
,
w
4
,
w
5
⋯
w
n
)
=
p
(
w
1
)
p
(
w
2
)
p
(
w
3
)
p
(
w
4
)
p
(
w
5
)
⋯
p
(
w
n
)
p(s)=p(w_1, w_2,w_3,w_4, w_5\cdots w_n)=p(w_1)p(w2)p(w_3)p(w_4)p(w_5)\cdots p(w_n)
p ( s ) = p ( w 1 , w 2 , w 3 , w 4 , w 5 ⋯ w n ) = p ( w 1 ) p ( w 2 ) p ( w 3 ) p ( w 4 ) p ( w 5 ) ⋯ p ( w n )
p
(
今
天
,
是
,
春
节
,
我
们
,
都
,
休
息
)
=
p
(
今
天
)
p
(
是
)
p
(
春
节
)
p
(
我
们
)
p
(
都
)
p
(
休
息
)
p(今天,是,春节,我们,都,休息)=p(今天)p(是)p(春节)p(我们)p(都)p(休息)
p ( 今 天 , 是 , 春 节 , 我 们 , 都 , 休 息 ) = p ( 今 天 ) p ( 是 ) p ( 春 节 ) p ( 我 们 ) p ( 都 ) p ( 休 息 )
p
(
今
天
,
春
节
,
是
,
都
,
我
们
,
休
息
)
=
p
(
今
天
)
p
(
春
节
)
p
(
是
)
p
(
都
)
p
(
我
们
)
p
(
休
息
)
p(今天,春节,是,都,我们,休息)=p(今天)p(春节)p(是)p(都)p(我们)p(休息)
p ( 今 天 , 春 节 , 是 , 都 , 我 们 , 休 息 ) = p ( 今 天 ) p ( 春 节 ) p ( 是 ) p ( 都 ) p ( 我 们 ) p ( 休 息 )
基于1st order Markov Assumption
p
(
s
)
=
p
(
w
1
,
w
2
,
w
3
,
w
4
,
w
5
⋯
w
n
)
=
p
(
w
1
)
p
(
w
2
∣
w
1
)
p
(
w
3
∣
w
2
)
p
(
w
4
∣
w
3
)
p
(
w
5
∣
w
4
)
⋯
p
(
w
n
∣
w
n
−
1
)
=
p
(
w
1
)
∏
i
=
2
n
(
w
i
∣
w
i
−
1
)
p(s)=p(w_1, w_2,w_3,w_4, w_5\cdots w_n)=p(w_1)p(w2|w_1)p(w_3|w_2)p(w_4|w_3)p(w_5|w_4)\cdots p(w_n|w_{n-1})\\ =p(w_1)\prod_{i=2}^n(w_i|w_{i-1})
p ( s ) = p ( w 1 , w 2 , w 3 , w 4 , w 5 ⋯ w n ) = p ( w 1 ) p ( w 2 ∣ w 1 ) p ( w 3 ∣ w 2 ) p ( w 4 ∣ w 3 ) p ( w 5 ∣ w 4 ) ⋯ p ( w n ∣ w n − 1 ) = p ( w 1 ) i = 2 ∏ n ( w i ∣ w i − 1 )
当N>2的时候,也把这个模型称为:higher order LM
先看看公式:
p
(
s
)
=
p
(
w
1
,
w
2
,
w
3
,
w
4
,
w
5
⋯
w
n
)
=
p
(
w
1
)
p
(
w
2
)
p
(
w
3
)
p
(
w
4
)
p
(
w
5
)
⋯
p
(
w
n
)
p(s)=p(w_1, w_2,w_3,w_4, w_5\cdots w_n)=p(w_1)p(w2)p(w_3)p(w_4)p(w_5)\cdots p(w_n)
p ( s ) = p ( w 1 , w 2 , w 3 , w 4 , w 5 ⋯ w n ) = p ( w 1 ) p ( w 2 ) p ( w 3 ) p ( w 4 ) p ( w 5 ) ⋯ p ( w n )
p
(
w
n
)
p(w_n)
p ( w n )
2
1
9
4
\cfrac{2}{19^4}
1 9 4 2
先看公式:
p
(
s
)
=
p
(
w
1
,
w
2
,
w
3
,
w
4
,
w
5
⋯
w
n
)
=
p
(
w
1
)
p
(
w
2
∣
w
1
)
p
(
w
3
∣
w
2
)
p
(
w
4
∣
w
3
)
p
(
w
5
∣
w
4
)
⋯
p
(
w
n
∣
w
n
−
1
)
=
p
(
w
1
)
∏
i
=
2
n
(
w
i
∣
w
i
−
1
)
p(s)=p(w_1, w_2,w_3,w_4, w_5\cdots w_n)=p(w_1)p(w2|w_1)p(w_3|w_2)p(w_4|w_3)p(w_5|w_4)\cdots p(w_n|w_{n-1})\\ =p(w_1)\prod_{i=2}^n(w_i|w_{i-1})
p ( s ) = p ( w 1 , w 2 , w 3 , w 4 , w 5 ⋯ w n ) = p ( w 1 ) p ( w 2 ∣ w 1 ) p ( w 3 ∣ w 2 ) p ( w 4 ∣ w 3 ) p ( w 5 ∣ w 4 ) ⋯ p ( w n ∣ w n − 1 ) = p ( w 1 ) i = 2 ∏ n ( w i ∣ w i − 1 )
p
(
w
n
∣
w
n
−
1
)
p(w_n|w_{n-1})
p ( w n ∣ w n − 1 )
N=3,用同样的语料库:
p
L
M
(
今
天
上
午
有
课
程
)
=
p
L
M
(
今
天
)
p
L
M
(
上
午
∣
今
天
)
p
L
M
(
有
∣
今
天
,
上
午
)
p
L
M
(
课
程
∣
今
天
,
上
午
,
有
)
p_{LM}(今天上午有课程)=p_{LM}(今天)p_{LM}(上午|今天)p_{LM}(有|今天,上午)p_{LM}(课程|今天,上午,有)
p L M ( 今 天 上 午 有 课 程 ) = p L M ( 今 天 ) p L M ( 上 午 ∣ 今 天 ) p L M ( 有 ∣ 今 天 , 上 午 ) p L M ( 课 程 ∣ 今 天 , 上 午 , 有 )
p
L
M
(
有
∣
今
天
,
上
午
)
=
1
/
2
p_{LM}(有|今天,上午)=1/2
p L M ( 有 ∣ 今 天 , 上 午 ) = 1 / 2
p
L
M
(
课
程
∣
今
天
,
上
午
,
有
)
=
1
p_{LM}(课程|今天,上午,有)=1
p L M ( 课 程 ∣ 今 天 , 上 午 , 有 ) = 1
Q:训练出来的语言模型效果好还是坏?
公式:
P
e
r
p
l
e
x
i
t
y
=
2
−
(
x
)
x:average log likelihood
Perplexity=2^{-(x)} \text{ x:average log likelihood}
P e r p l e x i t y = 2 − ( x ) x:average log likelihood
x
=
l
o
g
0.002
+
l
o
g
0.01
+
l
o
g
0.1
+
l
o
g
0.01
+
l
o
g
0.02
l
o
g
0.1
6
x=\cfrac{log0.002+log0.01+log0.1+log0.01+log0.02log0.1}{6}
x = 6 l o g 0 . 0 0 2 + l o g 0 . 0 1 + l o g 0 . 1 + l o g 0 . 0 1 + l o g 0 . 0 2 l o g 0 . 1
在Estimating Probability这节中,我们需要对等于0的概率进行处理,如果不处理就会出现两个明显不同的语句概率都为0的情况,无法分辨语法的好坏。
语料库
没有加平滑项之前:
P
M
L
E
(
w
i
∣
w
i
−
1
)
=
c
(
w
i
−
1
,
w
i
)
c
(
w
i
)
(2)
P_{MLE}(w_i|w_{i-1})=\cfrac{c(w_{i-1},w_i)}{c(w_i)}\tag2
P M L E ( w i ∣ w i − 1 ) = c ( w i ) c ( w i − 1 , w i ) ( 2 )
P
A
d
d
−
1
(
w
i
∣
w
i
−
1
)
=
c
(
w
i
−
1
,
w
i
)
+
1
c
(
w
i
)
+
V
P_{Add-1}(w_i|w_{i-1})=\cfrac{c(w_{i-1},w_i)+1}{c(w_i)+V}
P A d d − 1 ( w i ∣ w i − 1 ) = c ( w i ) + V c ( w i − 1 , w i ) + 1
语料库
这里V=17
3
19
+
1
19
,
⋯
,
1
19
16
个
=
1
\cfrac{3}{19}+\underset{16个}{\cfrac{1}{19},\cdots,\cfrac{1}{19}}=1
1 9 3 + 1 6 个 1 9 1 , ⋯ , 1 9 1 = 1
和Add-one Smoothing非常像,只是把1改为k
P
A
d
d
−
k
(
w
i
∣
w
i
−
1
)
=
c
(
w
i
−
1
,
w
i
)
+
k
c
(
w
i
)
+
k
V
P_{Add-k}(w_i|w_{i-1})=\cfrac{c(w_{i-1},w_i)+k}{c(w_i)+kV}
P A d d − k ( w i ∣ w i − 1 ) = c ( w i ) + k V c ( w i − 1 , w i ) + k
k
=
1
,
2
,
3
,
4
,
5
,
6
,
.
.
.
,
100
k=1,2,3,4,5,6,...,100
k = 1 , 2 , 3 , 4 , 5 , 6 , . . . , 1 0 0
f
(
k
)
f(k)
f ( k )
先看例子,假如说我们从语料库从得到下面词语的出现次数:核心思路 :
p
(
w
n
∣
w
n
−
1
,
w
n
−
2
)
=
λ
1
p
(
w
n
∣
w
n
−
1
,
w
n
−
2
)
+
λ
2
p
(
w
n
∣
w
n
−
1
)
+
λ
3
p
(
w
n
)
λ
1
+
λ
2
+
λ
3
=
1
p(w_n|w_{n-1},w_{n-2})=\lambda_1p(w_n|w_{n-1},w_{n-2})\\ +\lambda_2p(w_n|w_{n-1})\\ +\lambda_3p(w_n)\\ \lambda_1+\lambda_2+\lambda_3=1
p ( w n ∣ w n − 1 , w n − 2 ) = λ 1 p ( w n ∣ w n − 1 , w n − 2 ) + λ 2 p ( w n ∣ w n − 1 ) + λ 3 p ( w n ) λ 1 + λ 2 + λ 3 = 1
https://blog.csdn.net/lt326030434/article/details/87893601
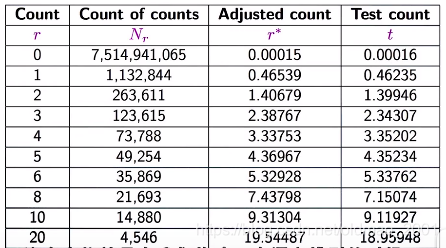
假设你在钓鱼,已经抓到了18只鱼:
N
c
N_c
N c
N
3
=
1
,
N
2
=
2
,
N
1
=
3
N_3=1,N_2=2,N_1=3
N 3 = 1 , N 2 = 2 , N 1 = 3
P
M
L
E
=
0
P_{MLE}=0
P M L E = 0
P
G
T
=
N
1
N
P_{GT}=\cfrac{N_1}{N}
P G T = N N 1
P
M
L
E
=
c
N
P_{MLE}=\cfrac{c}{N}
P M L E = N c
P
G
T
=
(
c
+
1
)
N
c
+
1
N
c
∗
1
N
P_{GT}=\cfrac{(c+1)N_{c+1}}{N_c}*\cfrac{1}{N}
P G T = N c ( c + 1 ) N c + 1 ∗ N 1
P
G
T
=
(
c
+
1
)
N
c
+
1
N
c
P_{GT}=\cfrac{(c+1)N_{c+1}}{N_c}
P G T = N c ( c + 1 ) N c + 1
0.00015
=
N
1
N
=
1132844
7514941065
0.00015=\cfrac{N_1}{N}=\cfrac{1132844}{7514941065}
0 . 0 0 0 1 5 = N N 1 = 7 5 1 4 9 4 1 0 6 5 1 1 3 2 8 4 4
P
G
T
=
(
c
+
1
)
N
c
+
1
N
c
=
(
1
+
1
)
263611
1132844
=
0.46539
P_{GT}=\cfrac{(c+1)N_{c+1}}{N_c}=\cfrac{(1+1)263611}{1132844}=0.46539
P G T = N c ( c + 1 ) N c + 1 = 1 1 3 2 8 4 4 ( 1 + 1 ) 2 6 3 6 1 1 = 0 . 4 6 5 3 9
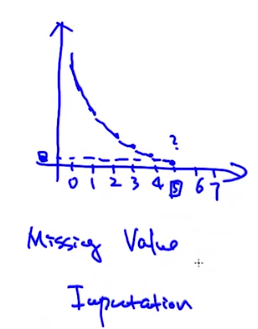
可以看到这个方法在计算出现c频次的单词个数概率的计算要依赖c+1频次的单词出现次数。