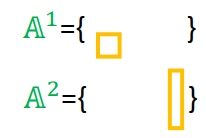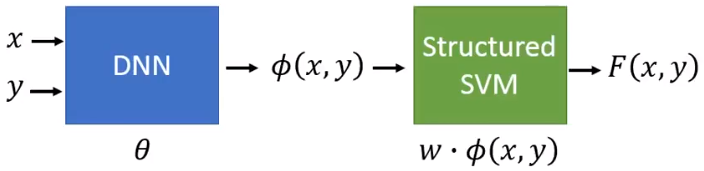公式输入请参考:
在线Latex公式
课程PPT
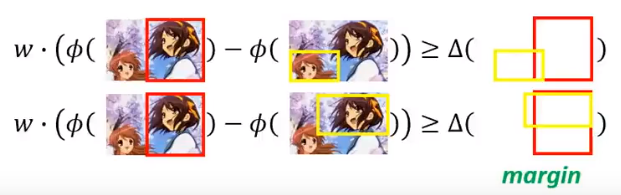
Structured SVM和之前的一个SVM的课还不一样,之前的SVM是Structured SVM的一个特例。
也就是SVM里面提到过的,数据是线性可分的,也就是说存在一个权重向量
w
^
\widehat w
w
w
^
⋅
ϕ
(
x
1
,
y
^
1
)
≥
w
^
⋅
ϕ
(
x
1
,
y
)
+
δ
w
^
⋅
ϕ
(
x
2
,
y
^
2
)
≥
w
^
⋅
ϕ
(
x
2
,
y
)
+
δ
\widehat w\cdot \phi(x^1,\widehat y^1)\geq \widehat w\cdot \phi(x^1, y)+\delta\\ \widehat w\cdot \phi(x^2,\widehat y^2)\geq \widehat w\cdot \phi(x^2, y)+\delta
w
⋅ ϕ ( x 1 , y
1 ) ≥ w
⋅ ϕ ( x 1 , y ) + δ w
⋅ ϕ ( x 2 , y
2 ) ≥ w
⋅ ϕ ( x 2 , y ) + δ
其实是上节提到过的,还没有证明的算法。这里贴过来(和上节不一样的是x,y的上标由r变成了n):
{
(
x
1
,
y
^
1
)
,
(
x
2
,
y
^
2
)
,
.
.
.
,
(
x
N
,
y
^
N
)
,
.
.
.
}
\{(x^1,\widehat y^1),(x^2,\widehat y^2),...,(x^N,\widehat y^N),...\}
{ ( x 1 , y
1 ) , ( x 2 , y
2 ) , . . . , ( x N , y
N ) , . . . }
w
w
w
w
w
w
w
=
0
w =0
w = 0
d
o
do
d o
(
x
n
,
y
^
n
(x^n,\widehat{y}^n
( x n , y
n
y
~
n
\tilde{y}^n
y ~ n
w
⋅
ϕ
(
x
n
,
y
)
w\cdot\phi(x^n,y)
w ⋅ ϕ ( x n , y )
y
~
n
=
a
r
g
m
a
x
y
∈
Y
w
⋅
ϕ
(
x
n
,
y
)
这
个
是
q
u
e
s
t
i
o
n
2
\tilde{y}^n=arg\underset{y\in Y}{max}\space w\cdot\phi(x^n,y)\quad这个是question \space2
y ~ n = a r g y ∈ Y ma x w ⋅ ϕ ( x n , y ) 这 个 是 q u e s t i o n 2
y
~
n
≠
y
^
n
\tilde{y}^n\neq\widehat{y}^n
y ~ n = y
n
w
w
w
w
→
w
+
ϕ
(
x
n
,
y
^
n
)
−
ϕ
(
x
n
,
y
~
n
)
w\to w+\phi(x^n,\widehat{y}^n)-\phi(x^n,\tilde{y}^n)
w → w + ϕ ( x n , y
n ) − ϕ ( x n , y ~ n )
u
n
t
i
l
w
i
s
n
o
t
u
p
d
a
t
e
d
→
until \space w \space is\space not\space updated \to
u n t i l w i s n o t u p d a t e d →
在本节的假定中,数据是线性可分的,为了找到
w
^
\widehat w
w
(
R
δ
)
2
(\cfrac{R}{\delta})^2
( δ R ) 2
δ
\delta
δ
ϕ
(
x
,
y
)
\phi(x,y)
ϕ ( x , y )
ϕ
(
x
,
y
′
)
\phi(x,y')
ϕ ( x , y ′ )
y
~
n
≠
y
^
n
\tilde{y}^n\neq\widehat{y}^n
y ~ n = y
n
w
w
w
w
0
=
0
→
w
1
→
w
2
→
⋯
→
w
k
→
w
k
+
1
→
⋯
w^0=0\to w^1\to w^2\to\cdots\to w^k\to w^{k+1}\to\cdots
w 0 = 0 → w 1 → w 2 → ⋯ → w k → w k + 1 → ⋯
w
k
=
w
k
−
1
+
ϕ
(
x
n
,
y
^
n
)
−
ϕ
(
x
n
,
y
~
n
)
(1)
w^k=w^{k-1}+\phi(x^n,\widehat{y}^n)-\phi(x^n,\tilde{y}^n)\tag1
w k = w k − 1 + ϕ ( x n , y
n ) − ϕ ( x n , y ~ n ) ( 1 )
w
k
w^k
w k
w
k
−
1
w^{k-1}
w k − 1
w
^
\widehat w
w
∀
n
\forall n
∀ n
∀
y
∈
Y
−
{
y
^
n
}
\forall y\in Y-\{\widehat y^n\}
∀ y ∈ Y − { y
n }
w
^
⋅
ϕ
(
x
n
,
y
^
n
)
≥
w
^
⋅
ϕ
(
x
n
,
y
)
+
δ
\widehat w\cdot \phi(x^n,\widehat y^n)\geq \widehat w\cdot \phi(x^n, y)+\delta
w
⋅ ϕ ( x n , y
n ) ≥ w
⋅ ϕ ( x n , y ) + δ
w
^
\widehat w
w
∣
∣
w
^
∣
∣
=
1
||\widehat w||=1
∣ ∣ w
∣ ∣ = 1
记
ρ
k
\rho_k
ρ k
w
^
\widehat w
w
w
k
w^k
w k
c
o
s
ρ
k
cos \rho_k
c o s ρ k
c
o
s
ρ
k
=
w
^
∣
∣
w
^
∣
∣
⋅
w
k
∣
∣
w
k
∣
∣
cos \rho_k=\cfrac{\widehat w}{||\widehat w||}\cdot\cfrac{w^k}{||w^k||}
c o s ρ k = ∣ ∣ w
∣ ∣ w
⋅ ∣ ∣ w k ∣ ∣ w k
w
^
\widehat w
w
w
k
w^k
w k
w
^
⋅
w
k
=
w
^
⋅
(
w
k
−
1
+
ϕ
(
x
n
,
y
^
n
)
−
ϕ
(
x
n
,
y
~
n
)
)
=
w
^
⋅
w
k
−
1
+
w
^
⋅
ϕ
(
x
n
,
y
^
n
)
−
w
^
⋅
ϕ
(
x
n
,
y
~
n
)
(2)
\widehat w\cdot w^k=\widehat w\cdot(w^{k-1}+\phi(x^n,\widehat{y}^n)-\phi(x^n,\tilde{y}^n))\\ =\widehat w\cdot w^{k-1}+\widehat w\cdot\phi(x^n,\widehat{y}^n) -\widehat w\cdot \phi(x^n,\tilde{y}^n)\tag2
w
⋅ w k = w
⋅ ( w k − 1 + ϕ ( x n , y
n ) − ϕ ( x n , y ~ n ) ) = w
⋅ w k − 1 + w
⋅ ϕ ( x n , y
n ) − w
⋅ ϕ ( x n , y ~ n ) ( 2 )
δ
\delta
δ
w
^
⋅
ϕ
(
x
1
,
y
^
1
)
≥
w
^
⋅
ϕ
(
x
1
,
y
)
+
δ
w
^
⋅
ϕ
(
x
2
,
y
^
2
)
≥
w
^
⋅
ϕ
(
x
2
,
y
)
+
δ
\widehat w\cdot \phi(x^1,\widehat y^1)\geq \widehat w\cdot \phi(x^1, y)+\delta\\ \widehat w\cdot \phi(x^2,\widehat y^2)\geq \widehat w\cdot \phi(x^2, y)+\delta
w
⋅ ϕ ( x 1 , y
1 ) ≥ w
⋅ ϕ ( x 1 , y ) + δ w
⋅ ϕ ( x 2 , y
2 ) ≥ w
⋅ ϕ ( x 2 , y ) + δ
公式(2)中的后面两项的差是大于等于
δ
\delta
δ
w
^
⋅
ϕ
(
x
n
,
y
^
n
)
−
w
^
⋅
ϕ
(
x
n
,
y
~
n
)
≥
δ
\widehat w\cdot\phi(x^n,\widehat{y}^n) -\widehat w\cdot \phi(x^n,\tilde{y}^n)\geq\delta
w
⋅ ϕ ( x n , y
n ) − w
⋅ ϕ ( x n , y ~ n ) ≥ δ
w
^
⋅
w
k
≥
w
^
⋅
w
k
−
1
+
δ
(3)
\widehat w\cdot w^k\geq\widehat w\cdot w^{k-1}+\delta\tag3
w
⋅ w k ≥ w
⋅ w k − 1 + δ ( 3 )
w
w
w
w
0
=
0
w^0=0
w 0 = 0
w
^
⋅
w
1
≥
w
^
⋅
w
0
+
δ
→
w
^
⋅
w
1
≥
δ
\widehat w\cdot w^1\geq\widehat w\cdot w^0+\delta\to\widehat w\cdot w^1\geq\delta
w
⋅ w 1 ≥ w
⋅ w 0 + δ → w
⋅ w 1 ≥ δ
w
^
⋅
w
2
≥
w
^
⋅
w
1
+
δ
→
w
^
⋅
w
2
≥
2
δ
\widehat w\cdot w^2\geq\widehat w\cdot w^1+\delta\to\widehat w\cdot w^2\geq2\delta
w
⋅ w 2 ≥ w
⋅ w 1 + δ → w
⋅ w 2 ≥ 2 δ
w
^
⋅
w
k
≥
k
δ
\widehat w\cdot w^k\geq k\delta
w
⋅ w k ≥ k δ
c
o
s
ρ
k
cos \rho_k
c o s ρ k
c
o
s
ρ
k
cos \rho_k
c o s ρ k
∣
∣
w
^
∣
∣
=
1
||\widehat w||=1
∣ ∣ w
∣ ∣ = 1
∣
∣
w
k
∣
∣
||w^k||
∣ ∣ w k ∣ ∣
∣
∣
w
k
∣
∣
||w^k||
∣ ∣ w k ∣ ∣
∣
∣
w
k
∣
∣
2
=
∣
∣
w
k
−
1
+
ϕ
(
x
n
,
y
^
n
)
−
ϕ
(
x
n
,
y
~
n
)
∣
∣
2
=
∣
∣
w
k
−
1
∣
∣
2
+
∣
∣
ϕ
(
x
n
,
y
^
n
)
−
ϕ
(
x
n
,
y
~
n
)
∣
∣
2
+
2
w
k
−
1
⋅
(
ϕ
(
x
n
,
y
^
n
)
−
ϕ
(
x
n
,
y
~
n
)
)
(4)
||w^k||^2=||w^{k-1}+\phi(x^n,\widehat{y}^n)-\phi(x^n,\tilde{y}^n)||^2\\ =||w^{k-1}||^2+||\phi(x^n,\widehat{y}^n)-\phi(x^n,\tilde{y}^n)||^2+2w^{k-1}\cdot(\phi(x^n,\widehat{y}^n)-\phi(x^n,\tilde{y}^n))\tag4
∣ ∣ w k ∣ ∣ 2 = ∣ ∣ w k − 1 + ϕ ( x n , y
n ) − ϕ ( x n , y ~ n ) ∣ ∣ 2 = ∣ ∣ w k − 1 ∣ ∣ 2 + ∣ ∣ ϕ ( x n , y
n ) − ϕ ( x n , y ~ n ) ∣ ∣ 2 + 2 w k − 1 ⋅ ( ϕ ( x n , y
n ) − ϕ ( x n , y ~ n ) ) ( 4 )
∣
∣
ϕ
(
x
n
,
y
^
n
)
−
ϕ
(
x
n
,
y
~
n
)
∣
∣
2
>
0
||\phi(x^n,\widehat{y}^n)-\phi(x^n,\tilde{y}^n)||^2>0
∣ ∣ ϕ ( x n , y
n ) − ϕ ( x n , y ~ n ) ∣ ∣ 2 > 0
2
w
k
−
1
⋅
(
ϕ
(
x
n
,
y
^
n
)
−
ϕ
(
x
n
,
y
~
n
)
)
<
0
2w^{k-1}\cdot(\phi(x^n,\widehat{y}^n)-\phi(x^n,\tilde{y}^n))<0
2 w k − 1 ⋅ ( ϕ ( x n , y
n ) − ϕ ( x n , y ~ n ) ) < 0
ϕ
(
x
n
,
y
~
n
)
\phi(x^n,\tilde{y}^n)
ϕ ( x n , y ~ n )
ϕ
(
x
n
,
y
^
n
)
\phi(x^n,\widehat{y}^n)
ϕ ( x n , y
n )
ϕ
(
x
n
,
y
~
n
)
\phi(x^n,\tilde{y}^n)
ϕ ( x n , y ~ n )
ϕ
(
x
n
,
y
^
n
)
\phi(x^n,\widehat{y}^n)
ϕ ( x n , y
n )
R
R
R
∣
∣
w
k
∣
∣
2
≤
∣
∣
w
k
−
1
∣
∣
2
+
R
2
||w^k||^2\leq||w^{k-1}||^2+R^2
∣ ∣ w k ∣ ∣ 2 ≤ ∣ ∣ w k − 1 ∣ ∣ 2 + R 2
w
w
w
w
0
=
0
w^0=0
w 0 = 0
∣
∣
w
1
∣
∣
2
≤
∣
∣
w
0
∣
∣
2
+
R
2
→
∣
∣
w
1
∣
∣
2
≤
R
2
||w^1||^2\leq||w^{0}||^2+R^2\to||w^1||^2\leq R^2
∣ ∣ w 1 ∣ ∣ 2 ≤ ∣ ∣ w 0 ∣ ∣ 2 + R 2 → ∣ ∣ w 1 ∣ ∣ 2 ≤ R 2
∣
∣
w
2
∣
∣
2
≤
∣
∣
w
1
∣
∣
2
+
R
2
→
∣
∣
w
2
∣
∣
2
≤
2
R
2
||w^2||^2\leq||w^{1}||^2+R^2\to||w^2||^2\leq 2R^2
∣ ∣ w 2 ∣ ∣ 2 ≤ ∣ ∣ w 1 ∣ ∣ 2 + R 2 → ∣ ∣ w 2 ∣ ∣ 2 ≤ 2 R 2
∣
∣
w
k
∣
∣
2
≤
k
R
2
||w^k||^2\leq kR^2
∣ ∣ w k ∣ ∣ 2 ≤ k R 2
c
o
s
ρ
k
=
w
^
∣
∣
w
^
∣
∣
⋅
w
k
∣
∣
w
k
∣
∣
w
^
⋅
w
k
≥
k
δ
∣
∣
w
k
∣
∣
2
≤
k
R
2
cos \rho_k=\cfrac{\widehat w}{||\widehat w||}\cdot\cfrac{w^k}{||w^k||}\quad\quad \widehat w\cdot w^k\geq k\delta \quad\quad ||w^k||^2\leq kR^2
c o s ρ k = ∣ ∣ w
∣ ∣ w
⋅ ∣ ∣ w k ∣ ∣ w k w
⋅ w k ≥ k δ ∣ ∣ w k ∣ ∣ 2 ≤ k R 2
c
o
s
ρ
k
=
w
^
∣
∣
w
^
∣
∣
⋅
w
k
∣
∣
w
k
∣
∣
≥
k
δ
k
R
2
=
k
δ
R
cos \rho_k=\cfrac{\widehat w}{||\widehat w||}\cdot\cfrac{w^k}{||w^k||}\geq\cfrac{k\delta}{\sqrt{kR^2}}=\sqrt k\frac{\delta}{R}
c o s ρ k = ∣ ∣ w
∣ ∣ w
⋅ ∣ ∣ w k ∣ ∣ w k ≥ k R 2
k δ = k
R δ
c
o
s
cos
c o s
k
δ
R
≤
1
→
k
≤
(
R
δ
)
2
\sqrt k\frac{\delta}{R}\leq1\to k\leq(\cfrac{R}{\delta})^2
k
R δ ≤ 1 → k ≤ ( δ R ) 2
(
R
δ
)
2
(\cfrac{R}{\delta})^2
( δ R ) 2
How to make training fast?不行
δ
\delta
δ
在数据(也就是
ϕ
(
x
,
y
)
\phi(x,y)
ϕ ( x , y )
w
w
w
w
′
w'
w ′
w
′
′
w''
w ′ ′
Define a cost
C
C
C
w
w
w
w
w
w
C
C
C
C
C
C
C
n
C_n
C n
x
n
x^n
x n
w
w
w
y
y
y
w
⋅
ϕ
(
x
n
,
y
)
w\cdot\phi(x^n,y)
w ⋅ ϕ ( x n , y )
y
^
n
\widehat y^n
y
n
w
⋅
ϕ
(
x
n
,
y
^
n
)
w\cdot\phi(x^n,\widehat y^n)
w ⋅ ϕ ( x n , y
n )
C
C
C
C
n
C_n
C n
y
^
n
\widehat y^n
y
n
w
⋅
ϕ
(
x
n
,
y
^
n
)
w\cdot\phi(x^n,\widehat y^n)
w ⋅ ϕ ( x n , y
n )
虽然cost函数中有一个max操作,是不可导的,但是还是可以梯度下降的,例如之前激活函数ReLU虽然在0点不可导,还不是可以反向传播。
w
w
w
C
C
C
C
=
∑
n
=
1
N
C
n
C=\sum_{n=1}^NC^n
C = n = 1 ∑ N C n
C
n
=
a
r
g
m
a
x
y
[
w
⋅
ϕ
(
x
n
,
y
)
]
−
w
⋅
ϕ
(
x
n
,
y
^
n
)
C^n=arg\underset{y}{max}[w\cdot\phi(x^n,y)]-w\cdot\phi(x^n,\widehat y^n)
C n = a r g y ma x [ w ⋅ ϕ ( x n , y ) ] − w ⋅ ϕ ( x n , y
n )
▽
C
n
\triangledown C^n
▽ C n
w
w
w
y
y
y
w
w
w
w
w
w
a
r
g
m
a
x
y
[
w
⋅
ϕ
(
x
n
,
y
)
]
arg\underset{y}{max}[w\cdot\phi(x^n,y)]
a r g y ma x [ w ⋅ ϕ ( x n , y ) ]
y
′
y'
y ′
w
w
w
a
r
g
m
a
x
y
[
w
⋅
ϕ
(
x
n
,
y
)
]
arg\underset{y}{max}[w\cdot\phi(x^n,y)]
a r g y ma x [ w ⋅ ϕ ( x n , y ) ]
y
′
′
y''
y ′ ′
w
w
w
a
r
g
m
a
x
y
[
w
⋅
ϕ
(
x
n
,
y
)
]
arg\underset{y}{max}[w\cdot\phi(x^n,y)]
a r g y ma x [ w ⋅ ϕ ( x n , y ) ]
y
′
′
′
y'''
y ′ ′ ′
C
n
C^n
C n
w
w
w
C
n
=
w
⋅
ϕ
(
x
n
,
y
′
)
−
w
⋅
ϕ
(
x
n
,
y
^
n
)
C^n=w\cdot\phi(x^n,y')-w\cdot\phi(x^n,\widehat y^n)
C n = w ⋅ ϕ ( x n , y ′ ) − w ⋅ ϕ ( x n , y
n )
w
w
w
C
n
=
w
⋅
ϕ
(
x
n
,
y
′
′
)
−
w
⋅
ϕ
(
x
n
,
y
^
n
)
C^n=w\cdot\phi(x^n,y'')-w\cdot\phi(x^n,\widehat y^n)
C n = w ⋅ ϕ ( x n , y ′ ′ ) − w ⋅ ϕ ( x n , y
n )
w
w
w
C
n
=
w
⋅
ϕ
(
x
n
,
y
′
′
′
)
−
w
⋅
ϕ
(
x
n
,
y
^
n
)
C^n=w\cdot\phi(x^n,y''')-w\cdot\phi(x^n,\widehat y^n)
C n = w ⋅ ϕ ( x n , y ′ ′ ′ ) − w ⋅ ϕ ( x n , y
n )
w
w
w
▽
C
n
\triangledown C^n
▽ C n
w
w
w
▽
C
n
=
ϕ
(
x
n
,
y
′
)
−
ϕ
(
x
n
,
y
^
n
)
\triangledown C^n=\phi(x^n,y')-\phi(x^n,\widehat y^n)
▽ C n = ϕ ( x n , y ′ ) − ϕ ( x n , y
n )
w
w
w
▽
C
n
=
ϕ
(
x
n
,
y
′
′
)
−
ϕ
(
x
n
,
y
^
n
)
\triangledown C^n=\phi(x^n,y'')-\phi(x^n,\widehat y^n)
▽ C n = ϕ ( x n , y ′ ′ ) − ϕ ( x n , y
n )
w
w
w
▽
C
n
=
ϕ
(
x
n
,
y
′
′
′
)
−
ϕ
(
x
n
,
y
^
n
)
\triangledown C^n=\phi(x^n,y''')-\phi(x^n,\widehat y^n)
▽ C n = ϕ ( x n , y ′ ′ ′ ) − ϕ ( x n , y
n )
η
=
1
\eta=1
η = 1
先看看我们之前做的,实际上对于每个样本的计算,考虑的Errors都是一样的:
w
w
w
△
(
y
^
,
y
)
>
0
\triangle (\widehat y,y)>0
△ ( y
, y ) > 0
y
^
\widehat y
y
y
y
y
A
(
y
)
A(y)
A ( y )
y
y
y
△
(
y
^
,
y
)
=
1
−
A
(
y
^
)
∩
A
(
y
)
A
(
y
^
)
∪
A
(
y
)
\triangle (\widehat y,y)=1-\cfrac{A(\widehat y)\cap A(y)}{A(\widehat y)\cup A(y)}
△ ( y
, y ) = 1 − A ( y
) ∪ A ( y ) A ( y
) ∩ A ( y )
从原来的:取分数最高的那个
y
y
y
y
^
\widehat y
y
C
n
=
m
a
x
y
[
w
⋅
ϕ
(
x
n
,
y
)
]
−
w
⋅
ϕ
(
x
n
,
y
^
n
)
C^n=\underset{y}{max}[w\cdot\phi(x^n,y)]-w\cdot\phi(x^n,\widehat y^n)
C n = y ma x [ w ⋅ ϕ ( x n , y ) ] − w ⋅ ϕ ( x n , y
n )
y
y
y
Δ
\Delta
Δ
y
^
\widehat y
y
Δ
\Delta
Δ
C
n
C^n
C n
y
^
\widehat y
y
y
y
y
Δ
\Delta
Δ
Δ
\Delta
Δ
C
n
=
m
a
x
y
[
△
(
y
^
,
y
)
+
w
⋅
ϕ
(
x
n
,
y
)
]
−
w
⋅
ϕ
(
x
n
,
y
^
n
)
C^n=\underset{y}{max}[\triangle (\widehat y,y)+w\cdot\phi(x^n,y)]-w\cdot\phi(x^n,\widehat y^n)
C n = y ma x [ △ ( y
, y ) + w ⋅ ϕ ( x n , y ) ] − w ⋅ ϕ ( x n , y
n )
Δ
\Delta
Δ
C
n
C^n
C n
为了和之前没有考虑Error的梯度求解区分开来,之前用的是
y
~
\tilde y
y ~
y
ˉ
\bar y
y ˉ
{
x
n
,
y
^
n
}
\{x^n,\widehat y^n\}
{ x n , y
n }
y
ˉ
n
=
a
r
g
m
a
x
y
[
△
(
y
^
,
y
)
+
w
⋅
ϕ
(
x
n
,
y
)
]
\bar y^n=arg\underset{y}{max}[\triangle (\widehat y,y)+w\cdot\phi(x^n,y)]
y ˉ n = a r g y ma x [ △ ( y
, y ) + w ⋅ ϕ ( x n , y ) ]
△
(
y
^
,
y
)
\triangle (\widehat y,y)
△ ( y
, y )
▽
C
n
(
w
)
=
ϕ
(
x
n
,
y
ˉ
n
)
−
ϕ
(
x
n
,
y
^
n
)
\triangledown C^n(w)=\phi(x^n,\bar y^n)-\phi(x^n,\widehat y^n)
▽ C n ( w ) = ϕ ( x n , y ˉ n ) − ϕ ( x n , y
n )
w
→
w
−
η
[
ϕ
(
x
n
,
y
ˉ
n
)
−
ϕ
(
x
n
,
y
^
n
)
]
w\to w-\eta[\phi(x^n,\bar y^n)-\phi(x^n,\widehat y^n)]
w → w − η [ ϕ ( x n , y ˉ n ) − ϕ ( x n , y
n ) ]
Minimizing the new cost function is minimizing the upper bound of the errors on training set.这里降低训练数据集中的Error上限不一定会减小Cost,只是有可能变小。
y
y
y
y
~
\tilde y
y ~
y
~
=
a
r
g
m
a
x
y
w
⋅
ϕ
(
x
n
,
y
)
\tilde y=arg\underset{y}{max}w\cdot\phi(x^n,y)
y ~ = a r g y ma x w ⋅ ϕ ( x n , y )
w
w
w
y
~
\tilde y
y ~
y
^
\widehat y
y
C
′
C'
C ′
C
′
=
∑
n
=
1
N
Δ
(
y
^
n
,
y
~
n
)
C'=\sum_{n=1}^N\Delta(\widehat y^n,\tilde y^n)
C ′ = n = 1 ∑ N Δ ( y
n , y ~ n )
w
w
w
C
′
C'
C ′
y
y
y
Δ
(
⋅
,
⋅
)
\Delta(\cdot,\cdot)
Δ ( ⋅ , ⋅ )
C
′
C'
C ′
C
C
C
C
′
=
∑
n
=
1
N
Δ
(
y
^
n
,
y
~
n
)
≤
C
=
∑
n
=
1
N
C
n
C'=\sum_{n=1}^N\Delta(\widehat y^n,\tilde y^n)\leq C=\sum_{n=1}^NC^n
C ′ = n = 1 ∑ N Δ ( y
n , y ~ n ) ≤ C = n = 1 ∑ N C n
Δ
(
y
^
n
,
y
~
n
)
≤
C
n
\Delta(\widehat y^n,\tilde y^n)\leq C^n
Δ ( y
n , y ~ n ) ≤ C n
[
w
⋅
ϕ
(
x
n
,
y
~
n
)
−
w
⋅
ϕ
(
x
n
,
y
^
n
)
]
≥
0
[w\cdot\phi(x^n,\tilde y^n)-w\cdot\phi(x^n,\widehat y^n)]\geq0
[ w ⋅ ϕ ( x n , y ~ n ) − w ⋅ ϕ ( x n , y
n ) ] ≥ 0
Δ
(
y
^
n
,
y
~
n
)
≤
Δ
(
y
^
n
,
y
~
n
)
+
[
w
⋅
ϕ
(
x
n
,
y
~
n
)
−
w
⋅
ϕ
(
x
n
,
y
^
n
)
]
\Delta(\widehat y^n,\tilde y^n)\leq\Delta(\widehat y^n,\tilde y^n)+[w\cdot\phi(x^n,\tilde y^n)-w\cdot\phi(x^n,\widehat y^n)]
Δ ( y
n , y ~ n ) ≤ Δ ( y
n , y ~ n ) + [ w ⋅ ϕ ( x n , y ~ n ) − w ⋅ ϕ ( x n , y
n ) ]
Δ
(
y
^
n
,
y
~
n
)
+
[
w
⋅
ϕ
(
x
n
,
y
~
n
)
−
w
⋅
ϕ
(
x
n
,
y
^
n
)
]
=
[
Δ
(
y
^
n
,
y
~
n
)
+
w
⋅
ϕ
(
x
n
,
y
~
n
)
]
−
w
⋅
ϕ
(
x
n
,
y
^
n
)
\Delta(\widehat y^n,\tilde y^n)+[w\cdot\phi(x^n,\tilde y^n)-w\cdot\phi(x^n,\widehat y^n)]=[\Delta(\widehat y^n,\tilde y^n)+w\cdot\phi(x^n,\tilde y^n)]-w\cdot\phi(x^n,\widehat y^n)
Δ ( y
n , y ~ n ) + [ w ⋅ ϕ ( x n , y ~ n ) − w ⋅ ϕ ( x n , y
n ) ] = [ Δ ( y
n , y ~ n ) + w ⋅ ϕ ( x n , y ~ n ) ] − w ⋅ ϕ ( x n , y
n )
y
~
n
\tilde y^n
y ~ n
y
y
y
[
Δ
(
y
^
n
,
y
~
n
)
+
w
⋅
ϕ
(
x
n
,
y
~
n
)
]
≤
m
a
x
y
[
Δ
(
y
^
n
,
y
)
+
w
⋅
ϕ
(
x
n
,
y
)
]
[\Delta(\widehat y^n,\tilde y^n)+w\cdot\phi(x^n,\tilde y^n)]\leq \underset{y}{max}[\Delta(\widehat y^n, y)+w\cdot\phi(x^n,y)]
[ Δ ( y
n , y ~ n ) + w ⋅ ϕ ( x n , y ~ n ) ] ≤ y ma x [ Δ ( y
n , y ) + w ⋅ ϕ ( x n , y ) ]
Δ
(
y
^
n
,
y
~
n
)
≤
m
a
x
y
[
Δ
(
y
^
n
,
y
)
+
w
⋅
ϕ
(
x
n
,
y
)
]
−
w
⋅
ϕ
(
x
n
,
y
^
n
)
=
C
n
\Delta(\widehat y^n,\tilde y^n)\leq \underset{y}{max}[\Delta(\widehat y^n, y)+w\cdot\phi(x^n,y)]-w\cdot\phi(x^n,\widehat y^n)=C^n
Δ ( y
n , y ~ n ) ≤ y ma x [ Δ ( y
n , y ) + w ⋅ ϕ ( x n , y ) ] − w ⋅ ϕ ( x n , y
n ) = C n
我们把上面的解决方案称为:Margin rescaling:
C
n
=
m
a
x
y
[
Δ
(
y
^
n
,
y
)
+
w
⋅
ϕ
(
x
n
,
y
)
]
−
w
⋅
ϕ
(
x
n
,
y
^
n
)
C^n=\underset{y}{max}[\Delta(\widehat y^n, y)+w\cdot\phi(x^n,y)]-w\cdot\phi(x^n,\widehat y^n)
C n = y ma x [ Δ ( y
n , y ) + w ⋅ ϕ ( x n , y ) ] − w ⋅ ϕ ( x n , y
n )
C
n
=
m
a
x
y
Δ
(
y
^
n
,
y
)
[
1
+
w
⋅
ϕ
(
x
n
,
y
)
]
−
w
⋅
ϕ
(
x
n
,
y
^
n
)
]
C^n=\underset{y}{max}\Delta(\widehat y^n, y)[1+w\cdot\phi(x^n,y)]-w\cdot\phi(x^n,\widehat y^n)]
C n = y ma x Δ ( y
n , y ) [ 1 + w ⋅ ϕ ( x n , y ) ] − w ⋅ ϕ ( x n , y
n ) ]
y
y
y
y
^
\widehat y
y
Δ
\Delta
Δ
y
y
y
y
^
\widehat y
y
Δ
\Delta
Δ
w
w
w
Δ
\Delta
Δ
Δ
\Delta
Δ
Training data and testing data can have different distribution.
w
w
w
λ
\lambda
λ
{
x
n
,
y
^
n
}
\{x^n,\widehat y^n\}
{ x n , y
n }
y
ˉ
=
a
r
g
m
a
x
y
[
△
(
y
^
,
y
)
+
w
⋅
ϕ
(
x
n
,
y
)
]
\bar y=arg\underset{y}{max}[\triangle (\widehat y,y)+w\cdot\phi(x^n,y)]
y ˉ = a r g y ma x [ △ ( y
, y ) + w ⋅ ϕ ( x n , y ) ]
▽
C
n
(
w
)
=
ϕ
(
x
n
,
y
ˉ
n
)
−
ϕ
(
x
n
,
y
^
n
)
+
w
\triangledown C^n(w)=\phi(x^n,\bar y^n)-\phi(x^n,\widehat y^n)+w
▽ C n ( w ) = ϕ ( x n , y ˉ n ) − ϕ ( x n , y
n ) + w
w
w
w
1
2
∣
∣
w
∣
∣
2
\cfrac{1}{2}||w||^2
2 1 ∣ ∣ w ∣ ∣ 2
w
w
w
w
→
w
−
η
[
ϕ
(
x
n
,
y
ˉ
n
)
−
ϕ
(
x
n
,
y
^
n
)
]
−
η
w
=
(
1
−
η
)
w
−
η
[
ϕ
(
x
n
,
y
ˉ
n
)
−
ϕ
(
x
n
,
y
^
n
)
]
w\to w-\eta[\phi(x^n,\bar y^n)-\phi(x^n,\widehat y^n)]-\eta w\\ =(1-\eta)w-\eta[\phi(x^n,\bar y^n)-\phi(x^n,\widehat y^n)]
w → w − η [ ϕ ( x n , y ˉ n ) − ϕ ( x n , y
n ) ] − η w = ( 1 − η ) w − η [ ϕ ( x n , y ˉ n ) − ϕ ( x n , y
n ) ]
把之前得到的结果写出来,然后看看Structured SVM是这么回事:
描述1 :
w
w
w
C
C
C
C
=
1
2
∣
∣
w
∣
∣
2
+
λ
∑
n
=
1
N
C
n
C=\cfrac{1}{2}||w||^2+\lambda\sum_{n=1}^NC^n
C = 2 1 ∣ ∣ w ∣ ∣ 2 + λ n = 1 ∑ N C n
C
n
=
m
a
x
y
[
Δ
(
y
^
n
,
y
)
+
w
⋅
ϕ
(
x
n
,
y
)
]
−
w
⋅
ϕ
(
x
n
,
y
^
n
)
C^n=\underset{y}{max}[\Delta(\widehat y^n, y)+w\cdot\phi(x^n,y)]-w\cdot\phi(x^n,\widehat y^n)
C n = y ma x [ Δ ( y
n , y ) + w ⋅ ϕ ( x n , y ) ] − w ⋅ ϕ ( x n , y
n )
移项:
C
n
+
w
⋅
ϕ
(
x
n
,
y
^
n
)
=
m
a
x
y
[
Δ
(
y
^
n
,
y
)
+
w
⋅
ϕ
(
x
n
,
y
)
]
(1)
C^n+w\cdot\phi(x^n,\widehat y^n)=\underset{y}{max}[\Delta(\widehat y^n, y)+w\cdot\phi(x^n,y)] \tag 1
C n + w ⋅ ϕ ( x n , y
n ) = y ma x [ Δ ( y
n , y ) + w ⋅ ϕ ( x n , y ) ] ( 1 )
说明 :
f
(
x
)
=
m
a
x
y
(
y
)
(a)
f(x)=\underset{y}{max}(y)\tag a
f ( x ) = y ma x ( y ) ( a )
y
=
{
1
,
2
,
3
,
4
,
5
,
6
,
7
,
8
,
9
}
y=\{1,2,3,4,5,6,7,8,9\}
y = { 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 }
f
(
x
)
=
9
f(x)=9
f ( x ) = 9
f
(
x
)
≥
∀
y
(b)
f(x)\geq \forall y\tag b
f ( x ) ≥ ∀ y ( b )
f
(
x
)
f(x)
f ( x )
m
i
n
i
m
i
z
e
f
(
x
)
minimize\quad f(x)
m i n i m i z e f ( x )
根据说明 ,我们的目标是minimizing
C
C
C
f
o
r
∀
y
:
C
n
+
w
⋅
ϕ
(
x
n
,
y
^
n
)
≥
Δ
(
y
^
n
,
y
)
+
w
⋅
ϕ
(
x
n
,
y
)
for \quad\forall y:\\C^n+w\cdot\phi(x^n,\widehat y^n)\geq \Delta(\widehat y^n, y)+w\cdot\phi(x^n,y)
f o r ∀ y : C n + w ⋅ ϕ ( x n , y
n ) ≥ Δ ( y
n , y ) + w ⋅ ϕ ( x n , y )
w
⋅
ϕ
(
x
n
,
y
^
n
)
−
w
⋅
ϕ
(
x
n
,
y
)
≥
Δ
(
y
^
n
,
y
)
−
C
n
w\cdot\phi(x^n,\widehat y^n)-w\cdot\phi(x^n,y)\geq \Delta(\widehat y^n, y)-C^n
w ⋅ ϕ ( x n , y
n ) − w ⋅ ϕ ( x n , y ) ≥ Δ ( y
n , y ) − C n
描述2 :
w
w
w
C
C
C
C
=
1
2
∣
∣
w
∣
∣
2
+
λ
∑
n
=
1
N
C
n
C=\cfrac{1}{2}||w||^2+\lambda\sum_{n=1}^NC^n
C = 2 1 ∣ ∣ w ∣ ∣ 2 + λ n = 1 ∑ N C n
f
o
r
∀
n
:
f
o
r
∀
y
:
w
⋅
ϕ
(
x
n
,
y
^
n
)
−
w
⋅
ϕ
(
x
n
,
y
)
≥
Δ
(
y
^
n
,
y
)
−
C
n
for \quad\forall n:\\for \quad\forall y:\\w\cdot\phi(x^n,\widehat y^n)-w\cdot\phi(x^n,y)\geq \Delta(\widehat y^n, y)-C^n
f o r ∀ n : f o r ∀ y : w ⋅ ϕ ( x n , y
n ) − w ⋅ ϕ ( x n , y ) ≥ Δ ( y
n , y ) − C n
到这里,通常是把
C
C
C
ε
\varepsilon
ε
描述3 :
w
,
ε
1
,
⋯
,
ε
N
w,\varepsilon^1,\cdots,\varepsilon^N
w , ε 1 , ⋯ , ε N
C
C
C
C
=
1
2
∣
∣
w
∣
∣
2
+
λ
∑
n
=
1
N
ε
n
C=\cfrac{1}{2}||w||^2+\lambda\sum_{n=1}^N\varepsilon^n
C = 2 1 ∣ ∣ w ∣ ∣ 2 + λ n = 1 ∑ N ε n
f
o
r
∀
n
:
f
o
r
∀
y
:
w
⋅
ϕ
(
x
n
,
y
^
n
)
−
w
⋅
ϕ
(
x
n
,
y
)
≥
Δ
(
y
^
n
,
y
)
−
ε
n
(2)
for \quad\forall n:\\for \quad\forall y:\\w\cdot\phi(x^n,\widehat y^n)-w\cdot\phi(x^n,y)\geq \Delta(\widehat y^n, y)-\varepsilon^n\tag2
f o r ∀ n : f o r ∀ y : w ⋅ ϕ ( x n , y
n ) − w ⋅ ϕ ( x n , y ) ≥ Δ ( y
n , y ) − ε n ( 2 )
对于描述3中的公式2,如果
y
=
y
^
n
y=\widehat y^n
y = y
n
w
⋅
ϕ
(
x
n
,
y
^
n
)
−
w
⋅
ϕ
(
x
n
,
y
)
=
0
Δ
(
y
^
n
,
y
)
=
0
w\cdot\phi(x^n,\widehat y^n)-w\cdot\phi(x^n,y)=0\\ \Delta(\widehat y^n, y)=0
w ⋅ ϕ ( x n , y
n ) − w ⋅ ϕ ( x n , y ) = 0 Δ ( y
n , y ) = 0
ε
n
≥
0
\varepsilon^n\geq0
ε n ≥ 0
F
o
r
∀
y
≠
y
^
n
:
w
⋅
ϕ
(
x
n
,
y
^
n
)
−
w
⋅
ϕ
(
x
n
,
y
)
≥
Δ
(
y
^
n
,
y
)
−
ε
n
,
ε
n
≥
0
For \space \forall y\neq\widehat y^n:\\w\cdot\phi(x^n,\widehat y^n)-w\cdot\phi(x^n,y)\geq \Delta(\widehat y^n, y)-\varepsilon^n,\varepsilon^n\geq0
F o r ∀ y = y
n : w ⋅ ϕ ( x n , y
n ) − w ⋅ ϕ ( x n , y ) ≥ Δ ( y
n , y ) − ε n , ε n ≥ 0
Δ
\Delta
Δ
w
w
w
∀
y
≠
y
^
\forall y \neq \widehat y
∀ y = y
w
w
w
Δ
\Delta
Δ
Δ
−
ε
\Delta-\varepsilon
Δ − ε
ε
≥
0
\varepsilon\geq0
ε ≥ 0
ε
≤
0
\varepsilon\leq0
ε ≤ 0
ε
\varepsilon
ε
ε
→
∞
\varepsilon\to\infty
ε → ∞
w
w
w
ε
\varepsilon
ε
x
1
x^1
x 1
y
^
1
\widehat y^1
y
1
x
2
x^2
x 2
y
^
2
\widehat y^2
y
2
ε
1
+
ε
2
\varepsilon^1+\varepsilon^2
ε 1 + ε 2 描述3 的内容了。
下图是参数
w
,
ε
1
,
.
.
.
,
ε
N
w,\varepsilon^1,...,\varepsilon^N
w , ε 1 , . . . , ε N
C
C
C
C
C
C
f
o
r
∀
n
:
f
o
r
∀
y
,
y
≠
y
^
:
w
⋅
ϕ
(
x
n
,
y
^
n
)
−
w
⋅
ϕ
(
x
n
,
y
)
≥
Δ
(
y
^
n
,
y
)
−
ε
n
,
ε
n
≥
0
for \quad\forall n:\\for \quad\forall y, y\neq\widehat y:\\w\cdot\phi(x^n,\widehat y^n)-w\cdot\phi(x^n,y)\geq \Delta(\widehat y^n, y)-\varepsilon^n,\varepsilon^n\geq0
f o r ∀ n : f o r ∀ y , y = y
: w ⋅ ϕ ( x n , y
n ) − w ⋅ ϕ ( x n , y ) ≥ Δ ( y
n , y ) − ε n , ε n ≥ 0
A
n
A^n
A n
f
o
r
∀
n
:
f
o
r
y
∈
A
n
,
y
≠
y
^
:
w
⋅
[
ϕ
(
x
n
,
y
^
n
)
−
ϕ
(
x
n
,
y
)
]
≥
Δ
(
y
^
n
,
y
)
−
ε
n
,
ε
≥
0
for \quad\forall n:\\for \quad y\in A^n, y\neq\widehat y:\\w\cdot[\phi(x^n,\widehat y^n)-\phi(x^n,y)]\geq \Delta(\widehat y^n, y)-\varepsilon^n,\varepsilon\geq0
f o r ∀ n : f o r y ∈ A n , y = y
: w ⋅ [ ϕ ( x n , y
n ) − ϕ ( x n , y ) ] ≥ Δ ( y
n , y ) − ε n , ε ≥ 0
Elements in working set
A
n
A^n
A n
A
n
A^n
A n
A
1
,
A
2
,
.
.
.
,
A
N
A^1,A^2,...,A^N
A 1 , A 2 , . . . , A N
A
n
A^n
A n
A
n
A^n
A n
w
w
w
w
w
w
A
n
A^n
A n
Quadratic Program (QP):凸优化的二次规划问题。
A
n
=
n
u
l
l
A^n=null
A n = n u l l the most violated one ,这个选择标准后面再解释(应该是按垂直距离),先假设找出这条:
y
′
y'
y ′
y
′
y'
y ′
A
n
=
A
n
∪
{
y
′
}
A^n=A^n\cup \{y'\}
A n = A n ∪ { y ′ }
y
′
′
y''
y ′ ′
y
′
′
y''
y ′ ′
A
n
=
A
n
∪
{
y
′
′
}
=
{
y
′
,
y
′
′
}
A^n=A^n\cup \{y''\}=\{y',y''\}
A n = A n ∪ { y ′ ′ } = { y ′ , y ′ ′ }
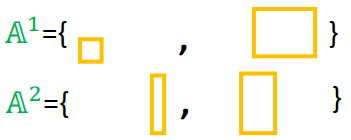
上面挖了个坑,如何找到最小值相对应最不满足的约束条件是什么?现在来填:
w
′
w'
w ′
ε
′
\varepsilon′
ε ′
Constraint:
w
⋅
[
ϕ
(
x
,
y
^
)
−
ϕ
(
x
,
y
)
]
≥
Δ
(
y
^
,
y
)
−
ε
\text{Constraint:}\quad w\cdot[\phi(x,\widehat y)-\phi(x,y)]\geq \Delta(\widehat y, y)-\varepsilon
Constraint: w ⋅ [ ϕ ( x , y
) − ϕ ( x , y ) ] ≥ Δ ( y
, y ) − ε
Violate a Constraint:
w
′
⋅
[
ϕ
(
x
,
y
^
)
−
ϕ
(
x
,
y
)
]
<
Δ
(
y
^
,
y
)
−
ε
′
\text{Violate a Constraint:}\quad w'\cdot[\phi(x,\widehat y)-\phi(x,y)]< \Delta(\widehat y, y)-\varepsilon'
Violate a Constraint: w ′ ⋅ [ ϕ ( x , y
) − ϕ ( x , y ) ] < Δ ( y
, y ) − ε ′
Degree of Violation:
Δ
(
y
^
,
y
)
−
ε
′
−
w
′
⋅
[
ϕ
(
x
,
y
^
)
−
ϕ
(
x
,
y
)
]
\text{Degree of Violation:}\quad \Delta(\widehat y, y)-\varepsilon'-w'\cdot[\phi(x,\widehat y)-\phi(x,y)]
Degree of Violation: Δ ( y
, y ) − ε ′ − w ′ ⋅ [ ϕ ( x , y
) − ϕ ( x , y ) ]
ε
′
\varepsilon'
ε ′
ϕ
(
x
,
y
^
)
\phi(x,\widehat y)
ϕ ( x , y
)
Δ
(
y
^
,
y
)
+
w
′
⋅
ϕ
(
x
,
y
)
\Delta(\widehat y, y)+w'\cdot\phi(x,y)
Δ ( y
, y ) + w ′ ⋅ ϕ ( x , y )
The most violated one:
a
r
g
m
a
x
y
[
Δ
(
y
^
,
y
)
+
w
′
⋅
ϕ
(
x
,
y
)
]
\text{The most violated one:}\quad arg\underset{y}{max}[\Delta(\widehat y, y)+w'\cdot\phi(x,y)]
The most violated one: a r g y ma x [ Δ ( y
, y ) + w ′ ⋅ ϕ ( x , y ) ]
Given training data:
{
(
x
1
,
y
^
1
)
,
(
x
2
,
y
^
2
)
,
.
.
.
,
(
x
N
,
y
^
N
)
}
\{(x^1,\widehat y^1),(x^2,\widehat y^2),...,(x^N,\widehat y^N)\}
{ ( x 1 , y
1 ) , ( x 2 , y
2 ) , . . . , ( x N , y
N ) }
A
1
=
n
u
l
l
,
A
2
=
n
u
l
l
,
.
.
.
,
A
N
=
n
u
l
l
A^1=null,A^2=null,...,A^N=null
A 1 = n u l l , A 2 = n u l l , . . . , A N = n u l l
解决 QP with Working Set
A
1
,
A
2
,
.
.
.
,
A
N
A^1,A^2,...,A^N
A 1 , A 2 , . . . , A N
w
w
w
(
x
n
,
y
^
n
)
(x^n,\widehat y^n)
( x n , y
n )
find the most violated constraints:
y
ˉ
n
=
a
r
g
m
a
x
y
[
Δ
(
y
^
n
,
y
)
+
w
′
⋅
ϕ
(
x
,
y
n
)
]
\text{find the most violated constraints: }\bar y^n=arg\underset{y}{max}[\Delta(\widehat y^n, y)+w'\cdot\phi(x,y^n)]
find the most violated constraints: y ˉ n = a r g y ma x [ Δ ( y
n , y ) + w ′ ⋅ ϕ ( x , y n ) ]
A
n
=
A
n
∪
y
ˉ
n
A^n=A^n\cup\bar y^n
A n = A n ∪ y ˉ n
Until
A
1
,
A
2
,
.
.
.
,
A
N
A^1,A^2,...,A^N
A 1 , A 2 , . . . , A N
w
w
w
A
1
=
n
u
l
l
,
A
2
=
n
u
l
l
A^1=null,A^2=null
A 1 = n u l l , A 2 = n u l l
ε
1
>
0
,
ε
2
>
0
\varepsilon^1>0,\varepsilon^2>0
ε 1 > 0 , ε 2 > 0
w
=
0
w=0
w = 0
w
=
0
w=0
w = 0
y
ˉ
1
=
a
r
g
m
a
x
y
[
Δ
(
y
^
1
,
y
)
+
0
⋅
ϕ
(
x
,
y
1
)
]
\bar y^1=arg\underset{y}{max}[\Delta(\widehat y^1, y)+0\cdot\phi(x,y^1)]
y ˉ 1 = a r g y ma x [ Δ ( y
1 , y ) + 0 ⋅ ϕ ( x , y 1 ) ]
w
=
0
w=0
w = 0
Δ
\Delta
Δ
Δ
\Delta
Δ
y
ˉ
1
\bar y^1
y ˉ 1
y
2
y^2
y 2
y
ˉ
2
=
a
r
g
m
a
x
y
[
Δ
(
y
^
2
,
y
)
+
0
⋅
ϕ
(
x
,
y
2
)
]
\bar y^2=arg\underset{y}{max}[\Delta(\widehat y^2, y)+0\cdot\phi(x,y^2)]
y ˉ 2 = a r g y ma x [ Δ ( y
2 , y ) + 0 ⋅ ϕ ( x , y 2 ) ]
w
=
w
1
w=w^1
w = w 1
w
1
w^1
w 1
y
ˉ
1
=
a
r
g
m
a
x
y
[
Δ
(
y
^
1
,
y
)
+
0
⋅
ϕ
(
x
,
y
1
)
]
\bar y^1=arg\underset{y}{max}[\Delta(\widehat y^1, y)+0\cdot\phi(x,y^1)]
y ˉ 1 = a r g y ma x [ Δ ( y
1 , y ) + 0 ⋅ ϕ ( x , y 1 ) ]
y
ˉ
1
=
1.55
\bar y^1=1.55
y ˉ 1 = 1 . 5 5
w
=
w
2
w=w^2
w = w 2
A
1
,
A
2
A^1,A^2
A 1 , A 2
这里有学生提问,老师又补充了一些知识,在Structured SVM的原版文章中,作者在更新working set上有一个条件,就是在the most violated的约束基础上还要加一个值,满足这个条件的约束才加入working set中,否则不加,这个值越大,整个算法的迭代次数就越少。
•Problem 1: Evaluation
K
K
K
{
w
1
,
w
2
,
.
.
.
,
w
K
}
\{w^1,w^2,...,w^K\}
{ w 1 , w 2 , . . . , w K }
y
y
y
y
∈
{
1
,
2
,
.
.
.
,
k
,
.
.
.
,
K
}
y\in\{1,2,...,k,...,K\}
y ∈ { 1 , 2 , . . . , k , . . . , K }
F
(
x
,
y
)
=
w
y
⋅
x
→
F(x,y)=w^y\cdot\overrightarrow{x}
F ( x , y ) = w y ⋅ x
x
→
\overrightarrow{x}
x
x
x
x
x
x
x
x
→
\overrightarrow{x}
x
F
(
x
,
y
)
F(x,y)
F ( x , y )
F
(
x
,
y
)
=
w
⋅
ϕ
(
x
,
y
)
F(x,y)=w\cdot\phi(x,y)
F ( x , y ) = w ⋅ ϕ ( x , y )
w
w
w
ϕ
(
x
,
y
)
\phi(x,y)
ϕ ( x , y )
x
x
x
x
→
\overrightarrow{x}
x
ϕ
(
x
,
y
)
\phi(x,y)
ϕ ( x , y )
w
=
[
w
1
w
2
⋮
w
k
⋮
w
K
]
ϕ
(
x
,
y
)
=
[
0
0
⋮
x
→
⋮
0
]
w=\begin{bmatrix}w^1\\ w^2\\ \vdots\\ w^k\\ \vdots\\ w^K\end{bmatrix}\quad \phi(x,y)=\begin{bmatrix}0\\ 0\\ \vdots\\ \overrightarrow{x}\\ \vdots\\ 0\end{bmatrix}
w = ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ w 1 w 2 ⋮ w k ⋮ w K ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤ ϕ ( x , y ) = ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ 0 0 ⋮ x
⋮ 0 ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤
F
(
x
,
y
)
=
w
y
⋅
x
→
F(x,y)=w^y\cdot\overrightarrow{x}
F ( x , y ) = w y ⋅ x
y
y
y
y
^
\widehat y
y
y
^
=
a
r
g
m
a
x
y
∈
{
1
,
2
,
.
.
.
,
k
,
.
.
.
,
K
}
F
(
x
,
y
)
=
a
r
g
m
a
x
y
∈
{
1
,
2
,
.
.
.
,
k
,
.
.
.
,
K
}
w
y
⋅
x
→
\widehat y=arg\underset{y\in\{1,2,...,k,...,K\}}{max}F(x,y)=arg\underset{y\in\{1,2,...,k,...,K\}}{max}w^y\cdot\overrightarrow{x}
y
= a r g y ∈ { 1 , 2 , . . . , k , . . . , K } ma x F ( x , y ) = a r g y ∈ { 1 , 2 , . . . , k , . . . , K } ma x w y ⋅ x
w
,
ε
1
,
.
.
.
,
ε
N
w,\varepsilon^1,...,\varepsilon^N
w , ε 1 , . . . , ε N
C
C
C
C
=
1
2
∣
∣
w
∣
∣
2
+
λ
∑
n
=
1
N
ε
n
C=\cfrac{1}{2}||w||^2+\lambda\sum_{n=1}^N\varepsilon^n
C = 2 1 ∣ ∣ w ∣ ∣ 2 + λ n = 1 ∑ N ε n
F
o
r
∀
n
:
For\space\forall n:
F o r ∀ n :
F
o
r
∀
y
≠
y
^
n
:
\quad \quad For\space\forall y\ne\widehat y^n:
F o r ∀ y = y
n :
w
⋅
[
ϕ
(
x
n
,
y
^
n
)
−
ϕ
(
x
n
,
y
)
]
≥
Δ
(
y
^
n
,
y
)
−
ε
n
,
ε
n
≥
0
(3)
w\cdot[\phi(x^n,\widehat y^n)-\phi(x^n,y)]\geq \Delta(\widehat y^n, y)-\varepsilon^n,\varepsilon^n\geq0\tag3
w ⋅ [ ϕ ( x n , y
n ) − ϕ ( x n , y ) ] ≥ Δ ( y
n , y ) − ε n , ε n ≥ 0 ( 3 )
N
N
N
K
K
K
K
−
1
K-1
K − 1
N
(
K
−
1
)
N(K-1)
N ( K − 1 )
w
⋅
ϕ
(
x
n
,
y
^
n
)
=
w
y
^
n
⋅
x
→
,
w
⋅
ϕ
(
x
n
,
y
)
=
w
y
⋅
x
→
(4)
w\cdot\phi(x^n,\widehat y^n)=w^{\widehat y^n}\cdot\overrightarrow{x},\quad w\cdot\phi(x^n,y)=w^y\cdot\overrightarrow{x}\tag4
w ⋅ ϕ ( x n , y
n ) = w y
n ⋅ x
, w ⋅ ϕ ( x n , y ) = w y ⋅ x
( 4 )
w
y
^
n
⋅
x
→
−
w
y
⋅
x
→
≥
Δ
(
y
^
n
,
y
)
−
ε
n
,
ε
n
≥
0
w^{\widehat y^n}\cdot\overrightarrow{x}-w^y\cdot\overrightarrow{x}\geq \Delta(\widehat y^n, y)-\varepsilon^n,\varepsilon^n\geq0
w y
n ⋅ x
− w y ⋅ x
≥ Δ ( y
n , y ) − ε n , ε n ≥ 0
(
w
y
^
n
−
w
y
)
⋅
x
→
≥
Δ
(
y
^
n
,
y
)
−
ε
n
,
ε
n
≥
0
(w^{\widehat y^n}-w^y)\cdot\overrightarrow{x}\geq \Delta(\widehat y^n, y)-\varepsilon^n,\varepsilon^n\geq0
( w y
n − w y ) ⋅ x
≥ Δ ( y
n , y ) − ε n , ε n ≥ 0
Δ
(
y
^
n
,
y
)
\Delta(\widehat y^n, y)
Δ ( y
n , y )
y
∈
d
o
g
,
c
a
t
,
b
u
s
,
c
a
r
Δ
(
y
^
=
d
o
g
,
y
=
c
a
t
)
=
1
Δ
(
y
^
=
d
o
g
,
y
=
b
u
s
)
=
100
y\in dog,cat,bus,car\\ \Delta (\widehat y=dog,y=cat)=1\\ \Delta (\widehat y=dog,y=bus)=100
y ∈ d o g , c a t , b u s , c a r Δ ( y
= d o g , y = c a t ) = 1 Δ ( y
= d o g , y = b u s ) = 1 0 0
就是多分类中的K=2的场景,这个时候
y
∈
{
1
,
2
}
y\in\{1,2\}
y ∈ { 1 , 2 }
F
o
r
∀
y
≠
y
^
n
:
For\space\forall y\ne\widehat y^n:
F o r ∀ y = y
n :
(
w
y
^
n
−
w
y
)
⋅
x
→
≥
Δ
(
y
^
n
,
y
)
−
ε
n
,
ε
n
≥
0
(w^{\widehat y^n}-w^y)\cdot\overrightarrow{x}\geq \Delta(\widehat y^n, y)-\varepsilon^n,\varepsilon^n\geq0
( w y
n − w y ) ⋅ x
≥ Δ ( y
n , y ) − ε n , ε n ≥ 0
Δ
(
y
^
n
,
y
)
=
1
\Delta(\widehat y^n, y)=1
Δ ( y
n , y ) = 1
y
=
1
y=1
y = 1
(
w
1
−
w
2
)
⋅
x
→
≥
1
−
ε
n
(w^1-w^2)\cdot\overrightarrow{x}\geq 1-\varepsilon^n
( w 1 − w 2 ) ⋅ x
≥ 1 − ε n
y
=
2
y=2
y = 2
(
w
2
−
w
1
)
⋅
x
→
≥
1
−
ε
n
(w^2-w^1)\cdot\overrightarrow{x}\geq 1-\varepsilon^n
( w 2 − w 1 ) ⋅ x
≥ 1 − ε n
(
w
1
−
w
2
)
=
w
(w^1-w^2)=w
( w 1 − w 2 ) = w
y
=
1
y=1
y = 1
w
⋅
x
→
≥
1
−
ε
n
w\cdot\overrightarrow{x}\geq 1-\varepsilon^n
w ⋅ x
≥ 1 − ε n
y
=
2
y=2
y = 2
−
w
⋅
x
→
≥
1
−
ε
n
-w\cdot\overrightarrow{x}\geq 1-\varepsilon^n
− w ⋅ x
≥ 1 − ε n
ε
n
\varepsilon^n
ε n
Structured SVM有一个很大的缺陷,就是它是linear的(怪怪的,不是说有一个核的方法来做划分平面,来解决非线性划分方法吗),而且特征的定义(就是那个
ϕ
(
x
,
y
)
\phi(x,y)
ϕ ( x , y )
C
=
1
2
∣
∣
θ
∣
∣
2
+
1
2
∣
∣
θ
′
∣
∣
2
+
λ
∑
n
=
1
N
C
n
C=\cfrac{1}{2}||\theta||^2+\cfrac{1}{2}||\theta'||^2+\lambda\sum_{n=1}^NC^n
C = 2 1 ∣ ∣ θ ∣ ∣ 2 + 2 1 ∣ ∣ θ ′ ∣ ∣ 2 + λ n = 1 ∑ N C n
C
n
=
m
y
a
x
[
Δ
(
y
^
n
,
y
)
+
F
(
x
n
,
y
)
]
−
F
(
x
n
,
y
^
n
)
C^n= \underset{y}max{}[\Delta(\widehat y^n, y)+F(x^n,y)]-F(x^n,\widehat y^n)
C n = y m a x [ Δ ( y
n , y ) + F ( x n , y ) ] − F ( x n , y
n )