文章目录
解决什么问题
看不见的物体的实例级6D位姿和维度估计,不需要准确的CAD模型,就能对同类的物体进行估计
本文创新点\贡献
- 一个共享的典型表达方式:Normalized Object Coordinate Space(NOCE),可以和深度图结合来从一个杂乱的场景中估计多物体的6D和维度。
- 为了更好的训练,提出了了一种新的上下文感知技术来生成大量的完整的混合现实数据。
- 介绍了一种新的混合现实方法,该方法可以自动生成大量的数据,这些数据由对象和真实背景的合成渲染图组成,并且具有上下文感知能力,使其更加真实。
方法
方法概述

训练一个基于区域的神经网络,预测多物体的class lable、instance mask、NOCS map,NOCS map能提供在规范空间的物体的外形和尺寸,之后将规范空间和深度图结合,使用异常点去除和对齐技术就能预测出物体的6D和size
使用预测的物体的mask能获得检测的物体的3D点云 ,同时也用NOCS map来获得 的3D表达,然后估计让 到 变换的缩放、旋转、位移,用Umeyama算法来估计这7个维度,然后用RANSAC来处理离群点
这里没有在CNN预测的时候就是用depth map,因为现在好多检测、分割的数据集都是没有depth的,CNN不适用的话,就可以用那些来训练,这样的话效果更好一些。
是个好技巧!
mask+深度图确实可以的到点云信息,而且是蛮不错的信息,而NOCS map估计的,是在单位cube里的吧,所以要做一个变换,这个R、t、scale就是要求的吗?
Normalized Object Coordinate Space (NOCS):

一句话概括
让网络预测该模型在图像上的映射图(NOCS map)
解决的点
解决测试时对CAD模型的依赖的问题
优点
在测试的时候不使用CAD模型

原理
对NOCS Map的解释():
- 物体的可见部分的NOCS中的形状重建
- 稠密的逐像素NOCS对应
还是逐像素对应套路
操作
模型部分
NOCS被定义在一个包含单位方块的3D空间中, 。
给定每个类的一些已知的目标CAD模型的集合,通过均匀缩放对象来标准化它们的大小,使其紧密包围框的对角线长度为1,并以NOCS空间为中心;同一类的物体中心和方向都是对齐的
对角线看着不是1啊,就是正方形的变成是1,难道说中心的摄像机实体的对角线长度为1? 这个摄像机是悬浮在NOCS的中间吗?
对齐应该就是规范化到一个固定的坐标系的意思吧(中心、方向都固定)
这个均匀缩放是如何做的呢?作者使用的是一些原有的位置、尺寸、方向都规范化的模型(ShapeNetCore),重点在于如何汇聚成一个?
答:一直理解错了,并没有融合成一个!
NOCS的color code:
每个NOCS中的的位置
能用一个RGB颜色元组来可视化,训练的时候用NOCS在2D图像上的投影,然后测试的时候回归NOCS map
这个投影叫做NOCS Map
但是,这个Map有什么用呢?
颜色也只是刚好如此吧,恰好颜色也是三通道,对应xyz

CNN部分
用CNN来预测color-coded NOCS坐标的2D映射,也就是预测NOCS Map。
作者的CNN能学会生成看不见的物体的外观,再训练外观数量很多的集合的时候,也能预测物体和NOCS的逐像素对应关系。
做成NOCS的模型数量不多的时候,可以直接预测外观,但做成NOCS的模型数量很多的时候,就要用对应来处理,是这样吗?
是因为种类太多,就必须要用“模型融合”之后的模型吗?
这个方法很鲁棒,即使只有部分可见的时候。
物体对称
问题描述
许多家具物品都是关于一个轴对称的,比如杯子,作者一开始没有考虑到这个对称,就导致计算一些物体分类的结果的时候,产生很大的误差。
方法
对于每个训练数据中的catagory,定义了一个对称轴。在NOCS映射中,这个轴的预定义旋转会产生相同的损失函数值。
例如,一个筛子顶部是长方形的,那么他的对称轴就是垂直的,旋转一定的角度 后,得到相同的NOCS map和相同的loss。
对于那些不对称的物体, 的结果是唯一的(不会有其他角度的值和这个相同)
作者发现
对于大部分对称的categories足够了。
生成ground trurh NOCS map,{
},对应随着旋转轴旋转
。
然后定义对称损失函数: , 是预测的NOCS map像素
就是给所有的物体一个 1 to 的旋转角度,然后取其中最小的loss。
但是,怎么知道最小的loss就对应正确的位置?
最小的loss就是预测出的和NOCS map最像的,那么如果正好旋转到了最像的,loss就是最小的,设置 的范围很小,就是不用再旋转到另一个对称的外观的意思吧
那么之前为什么会有很大的差别呢?是因为预测错了旋转,其实是其他的对称面,结果就按着错的R来投影了,就导致loss很大?这样的话转一转确实会转到正确对应的情况
那么, 是如何获取的呢?对每个类都人工设置?如果类不多的话还好,好像也就30多个?
数据准备
在这个类别级的3D检测中,没有可获得的ground truth data是个大问题。所以作者提出一个生成数据集的方法:Context-Aware MixEd ReAlity (CAMERA)
用一种上下文感知的方式,结合真实的背景和合成的渲染的前景物体,合成的物体用可信的物理位置、亮度、缩放被渲染并组合到真实的场景中。

上下文感知混合现实方法
真实场景
场景选择:
使用31个广泛变化的室内场景的真实RGB-D图像作为背景,主要关注的桌子,是因为大部分室内活动的对象就是桌子以及和手差不多大的物体。
共搜集了31个场景的553张图片,其中4张作为验证集
合成物体
从ShapeNetCore中挑选了一些看起来真实的、和手差不多大的物体,总共挑选了六种东西:瓶子,碗,照相机,罐子,笔记本电脑和马克杯
而且还加了一些其他的类的物体来做误导,事实证明可以提高鲁棒性,即使场景中有其他物体,也能预测出想要预测的物体。
包含了1085个独立的物体实例,其中184用来做验证集
上下文感知融合
为了提高真实性,引入了看似真实的照明,使用了一个平面检测算法来获得真是平面的像素级分割。
这么厉害的算法吗
然后在分割的平面上能放物体的地方,随机设置位置和方向,然后放置几个虚拟光源来模拟真实的室内照明条件。
猜测:假设有了分割就能得到平面,根据外观能得到旋转信息,然后用深度图就可以知道距离,从而得到位移信息,这样就能对物体做对应的射影,让他的位置符合平面的约束
但是虚拟光源怎么搞?如何得知室内的光源
最后,我们把渲染的和真实的图像结合起来,用完美的ground trurh的NOCS地图,mask 和 class lable来产生一个真实的合成。
总计渲染了300K个合成图像,其中25K用作验证集
混合现实使用的Unity和平面检测的自定义插件和点采样技术。
真实世界数据
获取了一些真实世界的数据,然后用半自动的技术来标注
使用结构传感器(就是生成RGB-D图的工具吧)从18个不同的场景(7个用来训练,5个用来验证,6个用来测试)共搜集了8K张RGB-D图片,4300用来训练,950用来验证,2750用来测试。
训练

backbone
使用的ResNet50和FPN
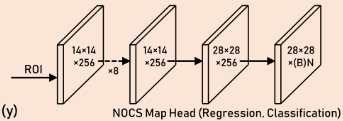
网络结构
使用的Mask RCNN的框架,在后面的head中添加了三个额外的heads来预测NOCS Map Head的 坐标(就是colored boxes)。这些头也能直接预测像素的回归和分类
像素的话就和CDPN和PVNet一样了
使用ReLU激活函数和 卷积。
每个ROI的输出是 ,N是种类的数量,每个种类都包含一个坐标(一个头只预测 中的一种)
我之前做的实验是把 放到一个head中,看起来一个head管一个效果更好
但是一个头只预测一种,那怎么知道有多少个NOCS map点需要预测呢?
训练的时候,只有NOCS map对loss function有影响。
比较回归和分类
为了预测NOCS map,即可以回归每个像素的值,也可以通过离散化像素的值将它看成一个分类问题:
- 直接回归比较困难,因为可能在训练的时候引入不稳定性。
- 分类的话,类别数又太多了( ),会在训练的时候引入更多的参数,比直接回归还困难
实验证明,设置 的像素分类,效果比直接回归更好
然后再用32个分类映射回去,这个就是调参调出来的把,CDPN用的是65
损失函数
类别、box、mask头的损失函数用的和Mask RCNN相同的。
对于NOCS map heads,用了两个损失函数:
- 一个标准的softmax损失函数来做分类
是对做了NOCS的模型的分类吗
-
损失函数来做回归
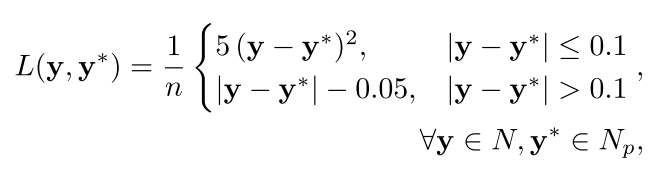
是ground truthNOCS map的像素值
是预测的NOCS map像素值
是ROI中的mask像素的数量
是ground truth和预测的NOCS map
训练方案
初始化
用在COCO上的2D实例分割的ResNet50、RPN、FPN来初始化backbone。
对于所有的heads,用[Delving deep into rectifiers: Surpassing human-level performance on imagenet classificatio]的技术来初始化。
参数设置
| 类 | 数值 |
|---|---|
| batch size | 2 |
| learning rate | 0.001 |
| SGD | 0.9 |
| weight decay |
训练流程

- 固定住ResNet50的全部权重,只训练head的层,对RPN和FPN做10K个迭代
- 固定住ResNet50的level 4以下的层,训练3K个迭代
- 固定住ResNet50的level 4以下的层,训练70K个迭代
每次切换到下一流程的时候,learning rate下降10倍
这整的也太花哨了,也不说明为啥这样
实验
自己做了个baseline来检测效果,从depth map和instance mask中获取3D点云信息,使用ICP[3]对齐mask point到对应的类里面随机选择的模型里。对于实例级的3D位姿估计,和[49]比较结果
作者提的这些数据集我应该是用不到,但是在没有什么可比较的内容的情况下,可以学习作者的方法
作者使用了多种资源进行训练,有的有depth map,有的没有,为了平衡这些数据集,每个batch都从多个数据资源里按照一定比例选择图片
该实验表明,通过学习预测密集的NOCS map,我们的算法能够提供关于物体形状、部件和可见性的额外详细信息,这些信息对于正确估计物体的6D姿态和大小至关重要。

其中B表示没有上下文的情况,结果显示,只是用
的时候,效果是最差的,同时使用上下文结合且利用三种数据集(6 : 2 : 2)的时候效果最好
分析一下为什么:
或许就是因为数据的种类更丰富,拟合的更好?
只在 或 上训练的话,由于数据集比较小,所以容易过拟合

结果表明:像素分类始终优于回归,分类的时候,使用32 bins对于位姿估计最好;使用128 bins的时候对于检测更好
检测用啥bin? 对 x y z?
结果还显示有对称loss的时候精度更高
局限性
- 结果依赖RPN还有category预测,可能会对结果产生不正确、消极的影响
- 依赖深度图
- 训练的时候还是需要CAD模型,有没有直接用训练数据生成统一模型的方法?
根据R、t和image的mask来建模,还要加上缩放
我记得之前也有个论文说是结果依赖RPN
总结
- 将坐标规范化
- 训练方式独特,按照level划分
- 从多个数据集按比例采样
- 数据不够多的时候的处理方法
- 回归与分类的分析比较
