一、百度
1.自我介绍
2.技能提问:
- awk sed命令,文件处理,日志过滤相关,如t.txt 统计文件中hello出现的次数,txt文件的总行数
grep -o hello t.txt | wc -l //单词出现次数
cat logfile.txt | wc -l //行数
- python数据类型有哪些,列表元素增删,request模块介绍
number(数字)、string(字符串)、Boolean(布尔值)、None(空值)、list(列表)、tuple(元组)、dict(字典)、set(集合)
append(1) //列表末尾添加一个元素
extend([2,3,4]) //列表末尾添加多个元素
insert(1,value) // 在下标出添加一个元素
remove(2) //删除单个元素,删除首个符合条件的元素,按值删除
pop(1) //删除单个或多个元素,按位删除(根据索引删除)
del list(1) //它是根据索引(元素所在位置)来删除
- C/C++什么是多态,深拷贝浅拷贝的了解并实现一个例子
定义:多态的定义简单来说就是使一条语句有多种状态。
实现方式:多态的实现方式分为三块:重载、重写、重定义。
重载是在同一作用域内(不管是模块内还是类内,只要是在同一作用域内),具有相同函数名,不同的形参个数或者形参类型。返回值可以相同也可以不同(在函数名、形参个数、形参类型都相同而返回值类型不同的情况下无法构成重载,编译器报错。
重写是在不同作用域内(一个在父类一个在子类),函数名、形参个数、形参类型、返回值类型都相同并且父类中带有virtual关键字(换言之子类中带不带virtual都没有关系)。
重定义是在不同作用域内的(一个在父类一个在子类),只要函数名相同,且不构成重写,均称之为重定义
- 网络七层协议,tcp建立连接、断开连接过程及处于那一层,http处于那一层
tcp:传输层
http:应用层,
IP:网络层。
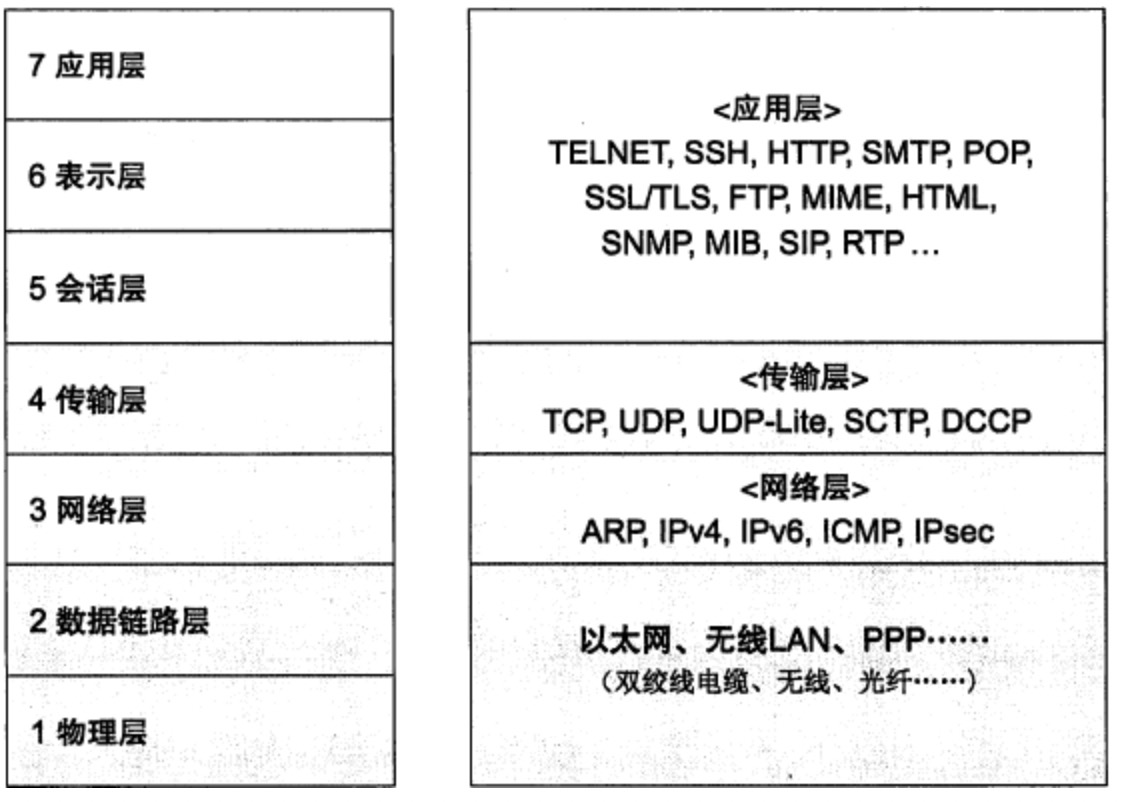
- http和https区别,get和posts区别,put和post区别,
HTTP特点:
无状态:协议对客户端没有状态存储,对事物处理没有“记忆”能力,比如访问一个网站需要反复进行登录操作
无连接:HTTP/1.1之前,由于无状态特点,每次请求需要通过TCP三次握手四次挥手,和服务器重新建立连接。比如某个客户机在短时间多次请求同一个资源,服务器并不能区别是否已经响应过用户的请求,所以每次需要重新响应请求,需要耗费不必要的时间和流量。
基于请求和响应:基本的特性,由客户端发起请求,服务端响应
简单快速、灵活
通信使用明文、请求和响应不会对通信方进行确认、无法保护数据的完整性
HTTPS特点:
基于HTTP协议,通过SSL或TLS提供加密处理数据、验证对方身份以及数据完整性保护
内容加密:采用混合加密技术,中间者无法直接查看明文内容
验证身份:通过证书认证客户端访问的是自己的服务器
保护数据完整性:防止传输的内容被中间人冒充或者篡改
HTTPS和HTTP的区别主要如下:
1、https协议需要到ca申请证书,一般免费证书较少,因而需要一定费用。
2、http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。
3、http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
4、http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
get和post区别:
1、GET请求参数直接拼接在url后面例如:url?params1=value1¶m2=value2,POST请求的参数则是放到body体
2、浏览器会自动缓存GET请求,而POST不会自动缓存,除非手动设置
3、GET 请求在浏览器中可回退,而POST会再次请求
4、GET请求时只能通过url编码,而POST则可以支持多种编码格式
5、GET的请求参数可以被完整保存到历史记录中,而POST不会被保留
6、GET产生的url可以被bookmark,而POST不可以
7、GET可接受的参数类型为ASCII字符,而POST没有限制
8、GET在ulr中传送的参数有长度限制, 而POST没有限制
真正的区别:
GET请求只会产生一个TCP包,也就是说浏览器会把所有的请求数据(header和data)一起发出去,服务器响应200时成功
POST 请求“可能” 会产生两个TCP包,第一次浏览器会先发送header,服务器响应100后,再次发送data
也就是说GET只需一次就将货物送到,而POST 会先告诉服务器我要发送数据,然后再把数据送过去,所以在调用时间上POST要稍微慢一点
udp和tcp区别:
1、TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接
2、TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保证可靠交付
3、TCP面向字节流,实际上是TCP把数据看成一连串无结构的字节流;UDP是面向报文的
UDP没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如IP电话,实时视频会议等)
4、每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信
5、TCP首部开销20字节;UDP的首部开销小,只有8个字节
6、TCP的逻辑通信信道是全双工的可靠信道,UDP则是不可靠信道
- 浏览器发起一个请求到获取页面信息经历了那些过程
1、首先,在浏览器地址栏中输入url
2、浏览器先查看浏览器缓存-系统缓存-路由器缓存,如果缓存中有,会直接在屏幕中显示页面内容。若没有,则跳到第三步操作。
3、在发送http请求前,需要域名解析(DNS解析),解析获取相应的IP地址。
4、浏览器向服务器发起tcp连接,与浏览器建立tcp三次握手。
5、握手成功后,浏览器向服务器发送http请求,请求数据包。
6、服务器处理收到的请求,将数据返回至浏览器
7、浏览器收到HTTP响应
8、读取页面内容,浏览器渲染,解析html源码
9、生成Dom树、解析css样式、js交互
10、客户端和服务器交互
11、ajax查询
其中,步骤2的具体过程是:
浏览器缓存:浏览器会记录DNS一段时间,因此,只是第一个地方解析DNS请求;
操作系统缓存:如果在浏览器缓存中不包含这个记录,则会使系统调用操作系统,获取操作系统的记录(保存最近的DNS查询缓存);
路由器缓存:如果上述两个步骤均不能成功获取DNS记录,继续搜索路由器缓存;
ISP缓存:若上述均失败,继续向ISP搜索。
- 售货机的测试case
- 登录页面(用户名和密码输入框及登录按钮)
- 项目测试流程
3.代码:
- 快排
- 链表逆序返回一个数组
- 青蛙跳台阶问题(斐波那契数列)
二、滴滴
- 一面:
技能:讲解测试的后端项目,讲解开发的工具
简单联表查询sql
代码:手写二分查找并设计用例
2.二面:
讲解工具
稳定性测试怎么测,如果上线后发现流量扛不住怎么办
三、爱奇艺
1、技能:自动化测试相关、工作中那些是可以自动化提效的
code review中发现了那些常见问题
2.非技术类问题:
- 每份工作,工作内容,具体复制,个人亮点(对业务的理解能力和掌握能力),改进点,最终收益状况,举实际例子和数据
- 离职原因
- 个人优势、劣势,近期规划
- 工作倾向:技术、业务
- 举例说清楚工作内容,另外在这个例子中最好有后续提效的点(可以是别人做的),怎么考虑的,具体怎么落地的,最终效果怎么样
- 效果切记可以量化,量化的值怎么来的
- 业务特点(逻辑复杂,流程分支太多),结果,架构,难点,提效
四、西瓜
1.一面
- 网络协议
- 长连接短连接(分别是什么,适用于什么场景)
HTTP协议长连接和短连接本质上是TCP的长连接和短连接。
短连接
连接->传输数据->关闭连接
比如HTTP是无状态的的短链接,浏览器和服务器每进行一次HTTP操作,就建立一次连接,但任务结束就中断连接。
具体就是 浏览器client发起并建立TCP连接 -> client发送HttpRequest报文 -> server接收到报文->server handle并发送HttpResponse报文给前端,发送完毕之后立即调用socket.close方法->client接收response报文->client最终会收到server端断开TCP连接的信号->client 端断开TCP连接,具体就是调用close方法。
也可以这样说:短连接是指SOCKET连接后,发送接收完数据后马上断开连接。
因为连接后接收了数据就断开了,所以每次数据接受处理不会有联系。 这也是HTTP协议无状态的原因之一。
长连接
连接->传输数据->保持连接 -> 传输数据-> ...........->直到一方关闭连接,多是客户端关闭连接。
长连接指建立SOCKET连接后不管是否使用都保持连接,但安全性较差。

如果业务来往比较频繁,则选择长连接。
如果server要主动给client发数据,则选择长连接。
- http及https区别,前端输入一个url界面没有响应怎么排查这个问题,测试流程,验收测试在那个阶段、
- 黑盒白盒区别,白盒测试方法,
- 编程题(输出数组中出现次数最多且值最大的数字),
- 写常用sql,hive跟mysql区别,
Hive采用了类SQL的查询语言HQL(hive query language)。除了HQL之外,其余无任何相似的地方。Hive是为了数据仓库设计的。
存储位置:Hive在Hadoop上;Mysql将数据存储在设备或本地系统中;
数据更新:Hive不支持数据的改写和添加,是在加载的时候就已经确定好了;数据库可以CRUD;
索引:Hive无索引,每次扫描所有数据,底层是MR,并行计算,适用于大数据量;MySQL有索引,适合在线查询数据;
执行:Hive底层是MarReduce;MySQL底层是执行引擎;
可扩展性:Hive:大数据量,慢慢扩去吧;MySQL:相对就很少了
- 头条的消息系统(评论、点赞、消息提醒等)怎么设计测试用例(从前后端分别考虑)
- DNS工作原理
DNS是应用层协议,事实上他是为其他应用层协议工作的,包括不限于HTTP和SMTP以及FTP,用于将用户提供的主机名解析为IP地址。
具体过程如下:
①用户主机上运行着DNS的客户端,就是我们的PC机或者手机客户端运行着DNS客户端了。
②浏览器将接收到的url中抽取出域名字段,就是访问的主机名,比如http://www.baidu.com/,并将这个主机名传送给DNS应用的客户端。
③DNS客户机端向DNS服务器端发送一份查询报文,报文中包含着要访问的主机名字段(中间包括一些列缓存查询以及分布式DNS集群的工作)。
④该DNS客户机最终会收到一份回答报文,其中包含有该主机名对应的IP地址。
⑤一旦该浏览器收到来自DNS的IP地址,就可以向该IP地址定位的HTTP服务器发起TCP连接。
- 平时涉及哪些测试方法
2.二面
- java多态、
- 多线程安全问题、
什么是线程安全问题?简单的说,当多个线程在共享同一个变量,做读写的时候,会由于其他线程的干扰,导致数据误差,就会出现线程安全问题。
使用多线程同步(synchronized)或者加锁lock
为什么这两种方法可以解决线程的安全问题?
当把可能发生冲突的代码包裹在synchronized或者lock里面后,同一时刻只会有一个线程执行该段代码,其他线程必须等该线程执行完毕释放锁以后,才能去抢锁,获得锁以后,才拥有执行权,这样就解决的数据的冲突,实现了线程的安全。
- codeReview发现的典型问题、
- 一张表里某个字段升级后需要测试哪些,
- 视频如何测试、
- 工作中怎么合理安排工作内容、
- 个人优势、
- 单例有几种实现方式、
饿汉式2种(静态常量饿汉式、静态代码块饿汉式)
懒汉式3种(线程不安全懒汉式、线程安全懒汉式、同步代码块懒汉式)
还有3种(双重检查、静态内部类、枚举方式)
- 写sql(如果统计某张表里每个小时(存的年月日时分秒格式)的数据量)、
- 算法题(找到字符串中第一个非重复的字符)、
- 测试工作中用到什么辅助性的工具、
- 最近面了哪些公司,为什么离职、对哪些公司比较有意向
- 介绍整体项目背景及项目做的事请及测试内容及测试形式,工作中的痛点是怎么推进的。