[root@hdp-1 bin]# ./spark-shell --master spark://hdp-1:7077 --executor-memory 500m --total-executor-cores 1 --driver-class-path /root/Jar_File/mysql-connector-java-5.1.39.jar
一定要加载MySQL的驱动包,不然创建Dataframe会报错误
在spark-shell中提供的sparksession对象是spark,sparkcontext对象时sc.
在创建DataFrame之前,为了支持RDD转换为Dataframe及后续的sql操作,需要通过improt语句(即 import spark.implicits._)导入相应的包,启用隐式转换。
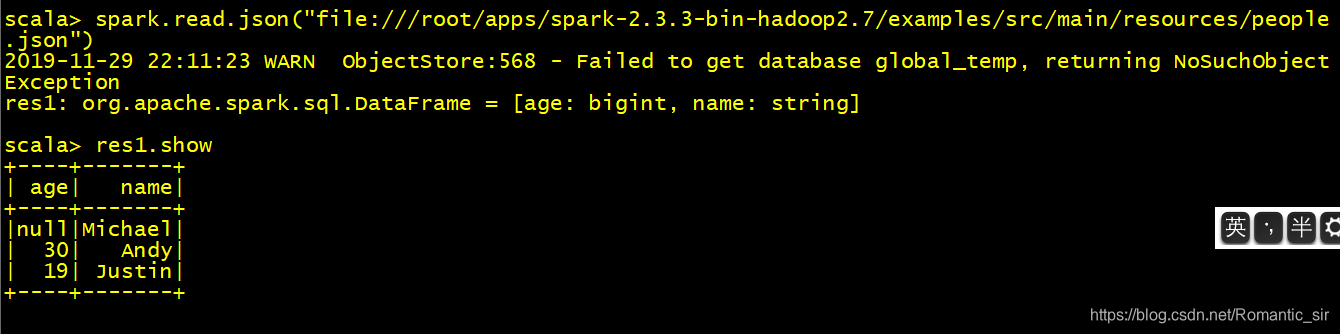
可以通过spark.read创建Dataframe
例如:spark.read.json("file:///root/people.json") 这里是文件路径
spark.read.csv("file:///root/people.csv")
spark.read.parquet("file:///root/people.parquet")