之前有过一段时间下决心去学大数据相关知识,从R入门,一本书被我从头到尾操作了一遍,并且也尝试了分析简单数据,的确是有幸一窥究竟,然而,数据的世界博大精深,真的不是那么容易入门的,所以终究又放下了,后来一直忙微服务的具体实现,也就不了了之。
一个人的精力是有限的,怎么才能快速提升自己的能力呢?困惑中迷茫前行。现在坚定下来,扩展自己的视野,从底层突破和提高,深究原理的实现,才能更快的成长。大数据虽然也是一个绕不过的坎,但量力而行,快速出成果。
最近在改造系统的日志部分,为了能够挖掘内部所含的信息,我决定开拓自己的视野,跳出以前的dotnet圈子,找更加成熟的方案,看能否快速部署和产生出自己需要的东西。

需求点
公司的需求是压缩空间~~,而我思考的是,日志到底是干什么的,我们能用来干什么?
1、快速发现问题,全文搜索功能
2、深度挖掘,发现客户习惯,访问压力等
偶遇
真的是跳出局限点了,忽然发现很大的世界!
业内已经如火如荼了,而外界茫然无知。今天早上还看到csdn推送的一篇文章:西安,不需要互联网。是的西安的环境真的落后1线城市几个数量级,这也源于我们自身不愿意跳出来看世界的缘故吧~~
Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎 Apache Lucene(TM) 基础上的搜索引擎.当然 Elasticsearch 并不仅仅是 Lucene 那么简单,它不仅包括了全文搜索功能,还可以进行以下工作:
分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。
扫描二维码关注公众号,回复: 9525333 查看本文章
实时分析的分布式搜索引擎。
可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。

看着这介绍,真的是一个强大的开箱即用产品啊!想起以前自己使用Lucene时的困难场景,真是好大的进步啊!搭起环境,用起来,不是什么难事,为我司的日志提供更宽广的大数据分析,不正是公司渴望而不可求的真实需求吗?
跳出来,不要在局限在当下的问题点,快速应用!
安装Elasticsearch
虚拟机搭建好,java安装上,都是很顺利的,下载启动,咔嚓~~~
uncaught exception in thread [main]
org.elasticsearch.bootstrap.StartupException: java.lang.RuntimeException: can not run elasticsearch as root
问题不大,提示不要用Root账号启动,换个其他账号,这个是为了安全安全!
建立个新账号:
adduser *** //添加用户
passwd *** //给用户赋值
添加完用户之后:
用root用户执行 : chown -R 用户名 文件夹名
之后再使用新用户启动就OK了。
增量编码压缩算法
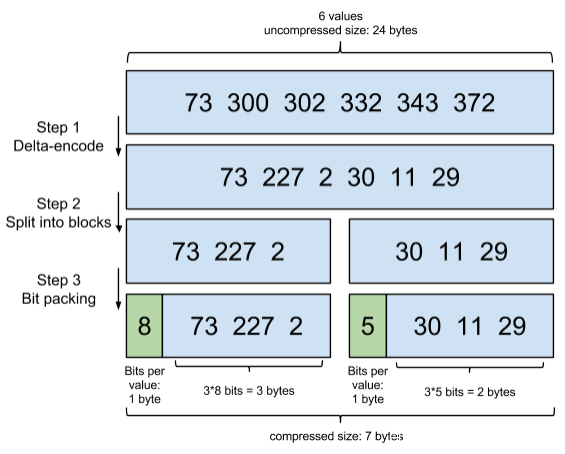
压缩是拿CPU换IO的最重要手段之一,不论索引是放在硬盘还是内存中。索引压缩的算法有几十种,跟文本压缩不同,索引压缩算法不仅仅需要考虑压缩率,更要考虑压缩和解压性能,否则会解压太慢而起不到CPU换IO的作用。增量编码压缩比较简单了:一句话而言:将大数变小数,按字节存储。
原理就是通过增量,将原来的大数变成小数仅存储增量值,再精打细算按bit排好队,最后通过字节存储,而不是尽管是2也是用int(4个字节)来存储这么随意。
Roaring bitmaps
提起Roaring bitmaps,就必须先从bitmap说起。Bitmap是一种数据结构,假设有要存储数据:[1,3,4,7,10]
对应的bitmap就是: [1, 0, 1, 1, 0, 0, 1, 0, 0, 1]
对应的bitmap的数组索引:1, 2, 3, 4, 5, 6, 7, 8 ,9, 10
非常直观,用0/1表示某个值是否存在,比如10这个值就对应第10位,对应的bit值是1,这样用一个字节就可以代表8个文档id,旧版本(5.0之前)的Lucene就是用这样的方式来压缩的,但这样的压缩方式仍然不够高效,如果有1亿个文档,那么需要12.5MB的存储空间,这仅仅是对应一个索引字段(我们往往会有很多个索引字段)。于是有人想出了Roaring bitmaps这样更高效的数据结构。
Bitmap的缺点是存储空间随着文档个数线性增长,Roaring bitmaps需要打破这个魔咒就一定要用到某些指数特性:
将posting list按照65535为界限分块,比如第一块所包含的文档id范围在0~65535之间,第二块的id范围是65536~131071,以此类推。再用<商,余数>的组合表示每一组id,这样每组里的id范围都在0~65535内了,剩下的就好办了,既然每组id不会变得无限大,那么我们就可以通过最有效的方式对这里的id存储。
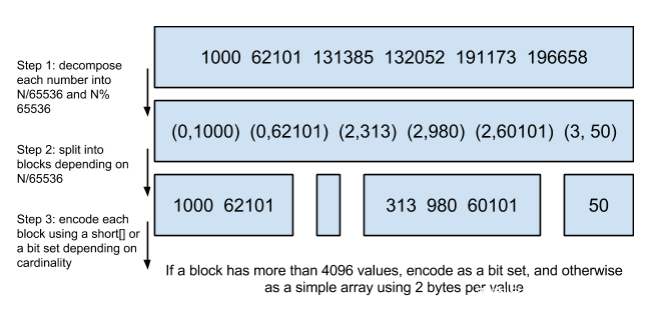
为什么是以65535为界限?",程序员的世界里除了1024外,65535也是一个经典值,因为它=2^16-1,正好是用2个字节能表示的最大数,一个short的存储单位,注意到上图里的最后一行,意思是如果是大块,用节省点用bitset存,小块就2个字节我也不计较了,用一个short[]存着方便。
那为什么用4096来区分大块还是小块呢?4096*2bytes = 8192bytes < 1KB, 磁盘一次寻道可以顺序把一个小块的内容都读出来,再大一位就超过1KB了,需要两次读。
