问答系统
问答系统,简称QA,是自然语言处理领域的一类经典问题。
问答系统的模式基本上分为两类:
1. 由输入的问题在n个候选答案中选取一个最佳的答案。
2. 由输入的问题在已有的问题中选取一个语义最相似的问题,将该已有问题的答案作为最终的答案返回。
第一种问答系统类似与京东客服的自动回答系统,很多使用过京东客服或是淘宝客服的同学会知道,当你问关商品或是关于售后以及物流的一些问题时,系统会自动回答你的问题,但是回答的这些信息都是提前放在答案库里的,所以会在答案库里的候选答案中选一个跟你的提问最匹配的答案作为回答。
第二种类型的问答系统类似与百度知道,知乎这一类问答社区的形式。在数据库中,已经得到解答的问题是有答案的,而系统需要做的就是将用户输入的问题跟这些已经有答案的问题进行语义相似度计算,返回语义最相似的问题的答案作为回答。
语义相似度
语义相似度,如同字面意思一样,就是形容两句话的语义是否相似,是不是表达着同样的意思。
在上面所介绍的两类分类问题中,都需要用到语义相似度的计算。第一类需要计算问题与n个候选答案之间的语义相似度,第二类需要计算问题与n个候选问题之间的语义相似度。
目前有许多方法可以用来计算语义相似度,例如余弦相似度(Cosine Similarity)、欧几里得距离(Euclidean Distance)、指数(exponential)、曼哈顿距离(Manhattan Distance)。今天我们要介绍的也是目前最常用的一种语义相似度计算方法:余弦相似度。
余弦相似度
在使用余弦相似度计算两条文本的语义距离时,我们还有一些前序工作需要进行,就是提取文本的语义特征向量。可以使用LSTM(Long Short-Term Memory)、GRU(Gate Recurrent Units)等循环神经网络来对文本语义特征进行提取,也可以使用Doc2Vec等算法来进行计算。
余弦相似度又称为余弦相似性,是通过计算两个向量夹角的余弦值来评估他们的相似度,在我们熟悉的二维空间中,余弦相似度的计算方法如下:
设a,b的坐标分别为: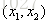
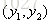
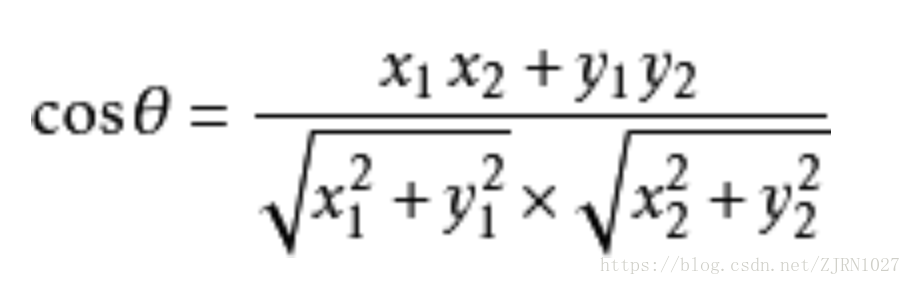
推广到多维空间中有:

在之前所述的两种问答系统中,n个候选答案(问题)之中包括一个正样本(The Ground Truth/Correct Answer/Correct Question)与多个负样本(Wrong answer/Wrong question)。然后依次计算输入问题的语义向量与候选答案(问题)之间的余弦相似度。
通过计算得到与正样本的相似度为:
与负样本的相似度为:
接下来需要设置一个边界值(Margin),来对计算出的正负样本的语义相似度进行评判。
当:
说明正负样本的相似度之差小于边界值,或是系统错误的计算出问题与负样本的相似度高于正样本。
当:
则说明系统计算出问题与正样本的相似度高于负样本,从而正确的分辨出了正样本,则不需要对网络参数进行优化和更新。
最后使用Hings Loss作为语义相似度模型的代价函数,公式如下:
最后我们贴出使用TensorFlow深度学习框架实现的语义相似度计算的部分代码:
def getCosineSimilarity(q, a):
q1 = tf.sqrt(tf.reduce_sum(tf.multiply(q, q), 1))
a1 = tf.sqrt(tf.reduce_sum(tf.multiply(a, a), 1))
mul = tf.reduce_sum(tf.multiply(q, a), 1)
cosSim = tf.div(mul, tf.multiply(q1, a1))
return cosSim
def getLoss(trueCosSim, falseCosSim, margin):
zero = tf.fill(tf.shape(trueCosSim), 0.0)
tfMargin = tf.fill(tf.shape(trueCosSim), margin)
with tf.name_scope("loss"):
losses = tf.maximum(zero, tf.subtract(tfMargin, tf.subtract(trueCosSim, falseCosSim)))
loss = tf.reduce_sum(losses)
return loss
self.trueCosSim = self.getCosineSimilarity(question2, trueAnswer2)
self.falseCosSim = self.getCosineSimilarity(question2, falseAnswer2)
self.loss = self.getLoss(self.trueCosSim, self.falseCosSim, self.margin)