KNN三个重要的要素:
- k值的选取;
- 距离度量的方式;
- 分类决策规则。

图中的数据集都打好了label,一类是蓝色的正方形,一类是红色的三角形,那个绿色的圆形是我们待分类的数据。
如果K=3,那么离绿色点最近的有2个红色三角形和1个蓝色的正方形,这3个点投票,于是绿色的这个待分类点属于红色的三角形。
如果K=5,那么离绿色点最近的有2个红色三角形和3个蓝色的正方形,这5个点投票,于是绿色的这个待分类点属于蓝色的正方形。
KNN本质是基于一种数据统计的方法。它没有明显的前期训练过程,而是程序开始运行时,把数据集加载到内存后,不需要进行训练,就可以开始分类了。具体是每次来一个未知的样本点,就在附近找K个最近的点进行投票。
k值的选择
• 没有一个固定的经验,一般根据样本的分布,选择一个较小的值,可以通过交叉验证选择一个合适的k值。
• 选择较小的k值,就相当于用较小的领域中的训练实例进行预测,训练误差会减小,只有与输入实例较近或相似的训练实例才会对预测结果起作用,与此同时带来的问题是泛化误差会增大,换句话说,K值的减小就意味着整体模型变得复杂,容易发生过拟合;
• 选择较大的k值,就相当于用较大领域中的训练实例进行预测,其优点是可以减少泛化误差,但缺点是训练误差会增大。这时候,与输入实例较远(不相似的)训练实例也会对预测器作用,使预测发生错误,且K值的增大就意味着整体的模型变得简单。
• 一个极端是k等于样本数m,则完全没有分类,此时无论输入实例是什么,都只是简单的预测它属于在训练实例中最多的类,模型过于简单。
距离的度量
• 我们有很多的距离度量方式(欧式距离,曼哈顿距离,闵可夫斯基距离),但是最常用的是欧式距离。
• 欧氏距离
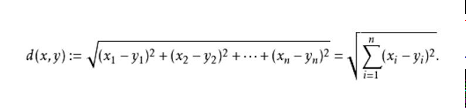
• 曼哈顿距离
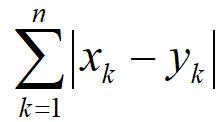
• 闵可夫斯基距离
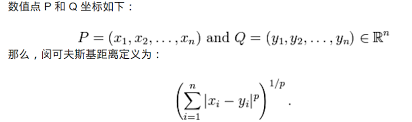
分类决策规则
• 一般都是使用多数表决法。所以我们重点是关注与k值的选择和距离的度量方式。
