什么是CurrentHashMap
我们都知道HashMap并不是并发线程安全的类,在高并发情况下,HashMap会存在各种问题,甚至put操作会出现死循环,导致CPU利用率接近100%。这时候我们很容易想到一个和它类似但是线程安全的类HashTable,但是HashTable使用的线程安全策略过于简单粗暴,直接在所有get/put相关操作上加上synchronized,等于线程存取操作时把整个Hash表给锁上了,其他线程只能阻塞串行化操作,所以性能非常差,无法达到系统并发量需求。CurrentHashMap的设计就十分精巧了,它能保证实现线程安全的同时,又极大的减少了对性能的影响。
实现原理
jdk1.8之前
在JDK1.7中ConcurrentHashMap采用了数组+Segment+分段锁的方式实现,主要思想是利用对数组进行分段加锁,降低锁的粒度,从而提高性能。
对比HashMap和ConcurrentHashMap的结构:


可以看出ConcurrentHashMap是把所有的HashEntity分组放在Segment里面,而Segment里面类似于HashMap的结构,即内部拥有一个Entry数组,数组中的每个元素又是一个链表。
同步机制通过segment继承ReentrantLock
ConcurrentHashMap使用分段锁技术,将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问,实现了并发访问。
调动Size方法时,如何实现一致性
统计ConcurrentHashMap的总元素数量,自然需要把各个Segment内部的元素数量汇总起来,但是用于CurrentHashMap不是对全局加锁,如果在统计Segment元素数量的过程中,已统计过的Segment瞬间可能插入新的元素,导致统计不准确。
ConcurrentHashMap在设计的实现思路大致如下:
1.遍历所有的Segment。
2.把Segment的元素数量累加起来。
3.把Segment的修改次数累加起来。
4.判断所有Segment的总修改次数是否大于上一次的总修改次数。如果大于,说明统计过程中有修改,重新统计,尝试次数+1;如果不是。说明没有修改,统计结束。
5.如果尝试次数超过阈值,则对每一个Segment加锁,再重新统计。
6.再次判断所有Segment的总修改次数是否大于上一次的总修改次数。由于已经加锁,次数一定和上次相等。
7.释放锁,统计结束。
这样设计为了尽量不锁住所有Segment,首先乐观地假设Size过程中不会有修改。当尝试一定次数,才无奈转为悲观锁,锁住所有Segment保证强一致性。
缺点
- 我们可以看出,由于ConcurrentHashMap在原有基础上加了Segment层,所以定义一个元素必须要进行两次Hash操作,第一次定位到Segment,第二次定位到元素所在链表的头部。相对HashMap定位元素的过程变长了。
jdk1.8中的实现
到jdk1.8HashMap结构由原来传统的数组+链表改为数组+链表+红黑树实现,JDK8中ConcurrentHashMap数据结构也是如此,取消了Segment分段锁的数据结构,取而代之的是数组+链表(红黑树)的结构。而对于锁的粒度,调整为对每个数组元素加锁(Node)。然后是定位节点的hash算法被简化了,这样带来的弊端是Hash冲突会加剧。因此在链表节点数量大于8时,会将链表转化为红黑树进行存储。这样一来,查询的时间复杂度就会由原先的O(n)变为O(logN)。
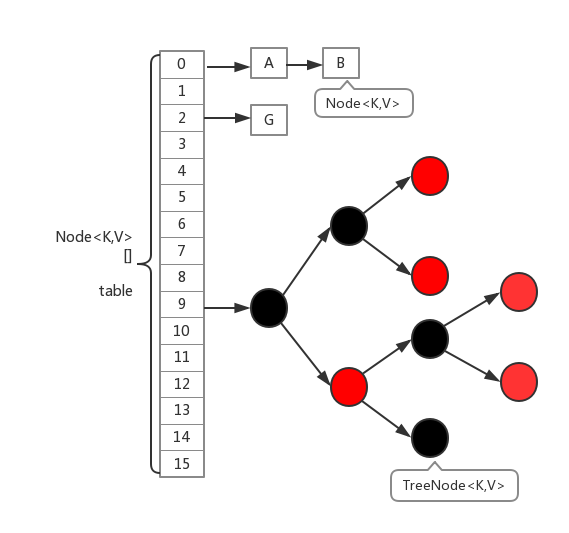
在保证线程安全策略上,CurrentHashMap采用的是Synchronized与CAS相结合的方法,对于Synchronized大家都不陌生,而且synchronized在新版本的JDK中优化的程度和ReentrantLock差不多了,我们来看CurrentHashMap的put方法源码
public V put(K key, V value) {
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)// 若table[]未创建,则初始化
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {// table[i]后面无节点时,直接创建Node(无锁操作)
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)// 如果当前正在扩容,则帮助扩容并返回最新table[]
tab = helpTransfer(tab, f);
else {// 在链表或者红黑树中追加节点
V oldVal = null;
synchronized (f) {// 这里并没有使用ReentrantLock,说明synchronized已经足够优化了
if (tabAt(tab, i) == f) {
if (fh >= 0) {// 如果为链表结构
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {// 找到key,替换value
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {// 在尾部插入Node
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {// 如果为红黑树
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)// 到达阀值,变为红黑树结构
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}从上面代码可以看出,put的步骤大致如下:
- 参数校验。
- 若table[]未创建,则初始化。
- 当table[i]后面无节点时,直接创建Node(无锁操作)。
- 如果当前正在扩容,则帮助扩容并返回最新table[]。
- 然后在链表或者红黑树中追加节点。
- 最后还回去判断是否到达阀值,如到达变为红黑树结构。
再看get操作,并没有加锁。所以在多线程操作的过程中,并不能完全的保证一致性。这里和1.7当中类似,是弱一致性的体现。
而size操作与jdk1.7的实现完全不同了,没有任何判断size是否准确以及兜底的加锁统计,而是做了求和之后就返回了。从而可以看出,size()和mappingCount()返回的都是一个估计值。
// 1.2时加入
public int size() {
long n = sumCount();
return ((n < 0L) ? 0 :
(n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE :
(int)n);
}
// 1.8加入的API
public long mappingCount() {
long n = sumCount();
return (n < 0L) ? 0L : n; // ignore transient negative values
}
final long sumCount() {
CounterCell[] as = counterCells; CounterCell a;
long sum = baseCount;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
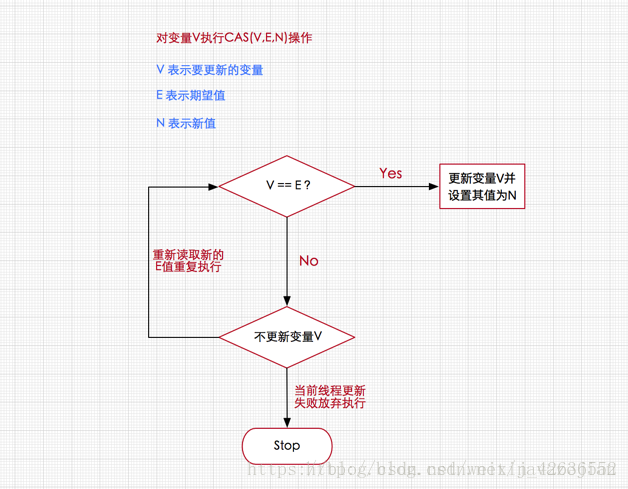
}对于CAS(Compare And Swap)即比较交换(乐观锁思想的一种实现方式),这里不详细说明了,大概流程如下:
CAS操作需要我们提供一个期望值,当期望值与当前线程的变量值相同时,说明还没线程修改该值,当前线程可以进行修改,也就是执行CAS操作,但如果期望值与当前线程不符,则说明该值已被其他线程修改,此时不执行更新操作,但可以选择重新读取该变量再尝试再次修改该变量,也可以放弃操作。
总结
ConcurrentHashMap大量的利用了volatile,final,CAS等lock-free技术来减少锁竞争对于性能的影响
并发环境下不能使用HashMap,若想在HashTable和ConcurrentHashMap之间做选择,那么就要在性能与数据一致性之间做权衡,HashTable虽然性能上不如ConcurrentHashMap,但并不能完全被取代,两者的迭代器的一致性不同的,hashtable的迭代器是强一致性的,而concurrenthashmap是弱一致的。ConcurrentHashMap的get,clear,iterator都是弱一致性的。所以ConcurrentHashMap适用于追求性能的场景,大多数线程都只做insert/delete操作,对读取数据的一致性要求较低。
参考:https://www.jianshu.com/p/749d1b8db066 https://juejin.im/post/5b00160151882565bd2582e0
https://segmentfault.com/a/1190000016124883 https://segmentfault.com/a/1190000016096542 https://segmentfault.com/a/1190000015865714 https://bugs.java.com/bugdatabase/view_bug.do?bug_id=JDK-8214427
https://tech.meituan.com/2016/06/24/java-hashmap.html