我这边是利用pandas和pymysql来实现将csv文件导入到MySQL数据库的
首先说一下实现逻辑,就是将csv读取到dataframe中,然后把按行读取数据,将每行的数据添加到列表中,在利用pymysql这个包将数据添加到数据库。
代码如下:
import pandas as pd
import pymysql
#读取数据
test = pd.read_csv(r'Antai_AE_round1_item_attr_20190626/Antai_AE_round1_item_attr_20190626.csv')
test.head()
#连接数据库
db = pymysql.connect(host="IP地址",user="数据库用户名", passwd="密码",db="要连接的数据库",charset='utf8')
#定义操作函数
def insert_deta():
list1 = []
num = 0
cursor = db.cursor()
for i in range(0,test.shape[0]): # 利用shape的第一个元素来获取数据的数量
row_data = test.iloc[i] # 获取第每行数据
value = (str(row_data[0]),str(row_data[1]),str(row_data[2]),str(row_data[3])) #读取第每行中每列数据,由于数据库添加使用的都是字符串形式添加故都取str
list1.append(value)
num +=1
if num==10000:
sql = "INSERT INTO item(item_id,cate_id,store_id,item_price)VALUES(%s,%s,%s,%s)"
cursor.executemany(sql, list1) # 执行sql语句
db.commit()
num = 0 # 计数归零
list1.clear() # 清空list
cursor.close() # 关闭连接
db.close()
#执行函数
insert_deta()
其中需要说明的是,要实现上述操作,需要先在数据库建好你要导入的那张表。其次我对代码进行了一定的优化,因为添加到数据库是一个耗时操作,所以我利用executemany方法将数据以每10000条来添加到数据库,提高效率。
其中我的数据库类型是:
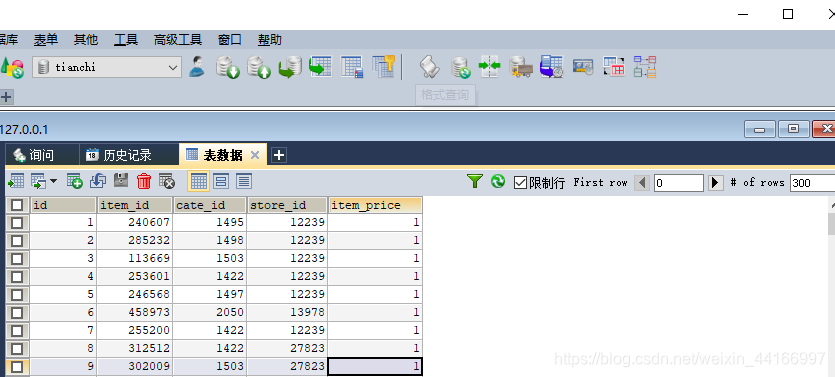
最后存入数据后:
方法二,利用第三方包直接存入
from sqlalchemy import create_engine
#读取数据
data = pd.read_csv('RFM_TRAD_FLOW.csv',encoding = 'gbk')
#创建连接数据库对象
engine = create_engine('mysql+pymysql://用户名:密码@localhost/数据库名?charset=utf8')
#存入数据库
data.to_sql('数据库表名字',engine)
