博客内容
1.索引数据结构红黑树, Hash, B+树详解
2.索引是怎样支撑千万级表的快速查找
3.如何基于索引B+树精准建立高性能索引
4.联合索引底层数据结构又是怎样的
5.MySQL索引优化最佳实践
看完之后,各位会明白数据库底层的原理与优化
索引底层原理
什么是索引?
索引是帮助MySQL高效获取数据的排好序的数据结构
索引数据结构有哪些
- 二叉树
- 红黑树
- Hash表
- B-Tree
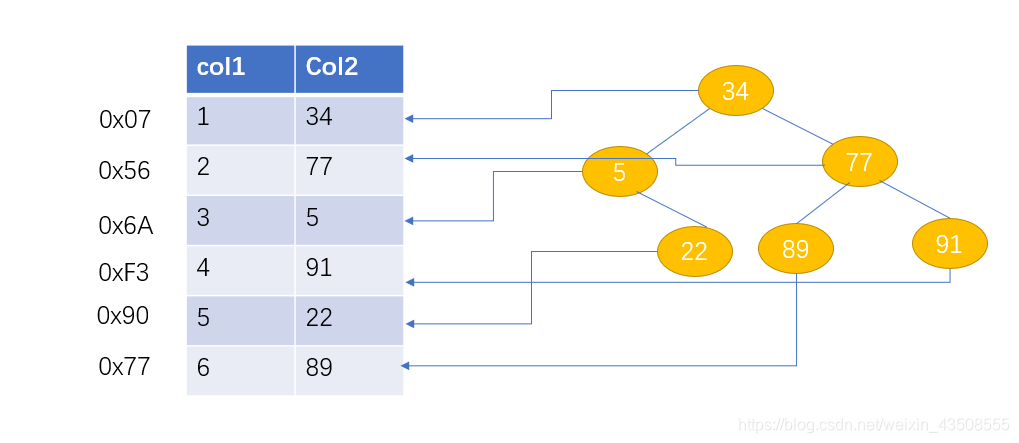
select * from t where t.col2 = 89;当没有索引时,需要在磁盘中
6次IO
当创建了索引时,如右侧二叉树,只需要2次IO
右侧的二叉树的每个节点中存储的时每个记录的地址
什么是
记录?
简单的说,就是插入的每一行数据元素
这么看来,二叉树读取元素的时间复杂度是O(log n),为什么索引内部实现是B+树,他有什么缺点
比如说,当创建的主键是col1,二叉树就会成为这样的
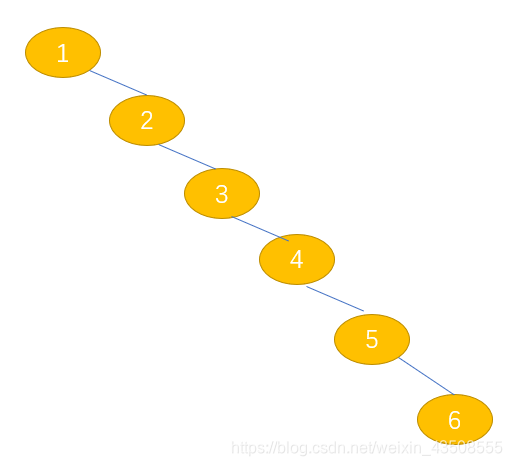
如果是有序的话,那么他就和没有索的时候向磁盘读取的次数是一样的
所以,没有采用这种数据结构
那
红黑树呢,他是可以自选的,不会使其单边增长,他的使用情况时怎样的
红黑树也叫完全平衡二叉树,如果放入的数据多了,那么树的高度会很高,查询的成本就会随树的高度增加而增加
如果进行一次千万级别的查询 那么就要向磁盘读取23次左右,差不多就10秒左右了
那么Hash表呢
只需要进行一次hash(key),就可以找到在磁盘上的内存地址只需要一次读取磁盘操作,就可以得到想要的记录,这是非常快的
既然Hash表查询操作那么快,为什么MySQL在99%的情况下使用的是B+树
这个很好理解,如果我们查找的是一个范围,Hash表就无能为力了,因为哈希表的特点就是可以快速的精确查询,但是不支持范围查询
如果是B-Tree呢?
B-Tree:
- 叶节点具有相同的深度
- 叶结点的指针为空
- 节点中的数据索引从左到右递增排列
- 一个节点是16K
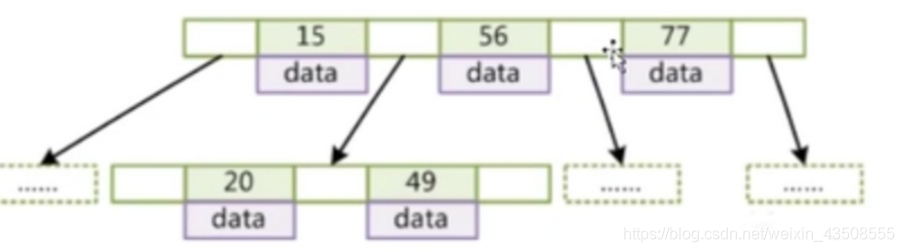
可以发现同样的元素,B树的表示要比完全平衡二叉树要“矮”,原因在于B树中的一个节点可以存储多个元素。
B树其实就已经是一个不错的数据结构,用来做索引效果还是不错的。
那为啥没用B树,而用了B+树?
如果查询的是一个范围,也是相当麻烦的,需要拿出后面的每个节点,没有解决查询范围的查询
那么来看看B+树 :
- 非叶子节点不存储data,只存储suoyin,可以放更多的索引
- 叶子节点不存储指针
顺序访问指针,提高区间访问的性能
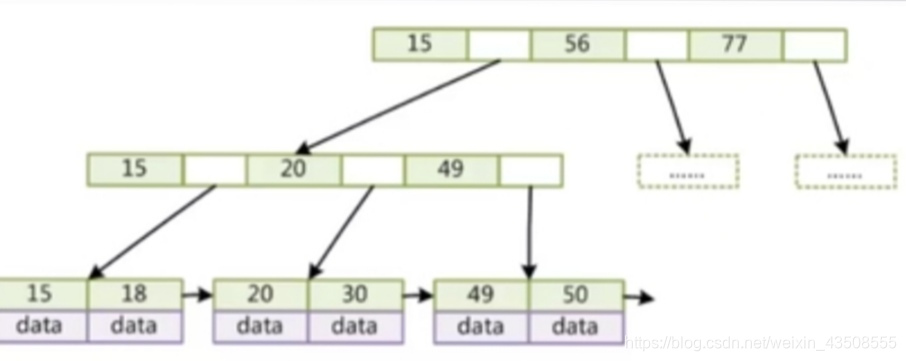
可以看出开,所有的数据在叶子节点上有一份完整的数据,叶子节点上有一份非叶子节点的冗余.
我们看一下上面的数据结构,最开始的Hash不支持范围查询,二叉树树高很高,只有B树跟B+有的一比。
B树一个节点可以存储多个元素,相对于完全平衡二叉树整体的树高降低了,磁盘IO效率提高了。
而B+树是B树的升级版,只是把非叶子节点冗余一下,这么做的好处是为了提高范围查找的效率。
提高了的原因也无非是会有指针指向下一个节点的叶子节点。
小结:到这里可以总结出来,Mysql选用B+树这种数据结构作为索引,可以提高查询索引时的磁盘IO效率,并且可以提高范围查询的效率,并且B+树里的元素也是有序的。
那么,一个B+树的节点中到底存多少个元素最合适你有了解过么?
大概三行B+树就可以存储2000多万个索引元素,一个节点16k,非叶子节点大概可存储1170个索引,叶子节点大概16个索引
一般2~4层,如果数据更多的话,那就分库分表
数据库的存储引擎了解吗
存储引擎:
- 非聚集索引:MyISAM
- 聚集索引 : Innodb
哦? 说说MyISAM
MyISAM索引文件和数据文件是分离的(非聚集)
创建一个表时,会创建三个文件:
- XXX.firm : 存储的是标的数据定义相关的信息,
表结构 - XXX.MYD : 存储的是表中
所有的数据行 - XXX.MYI : 存储的是表的索引,底层是
B+树
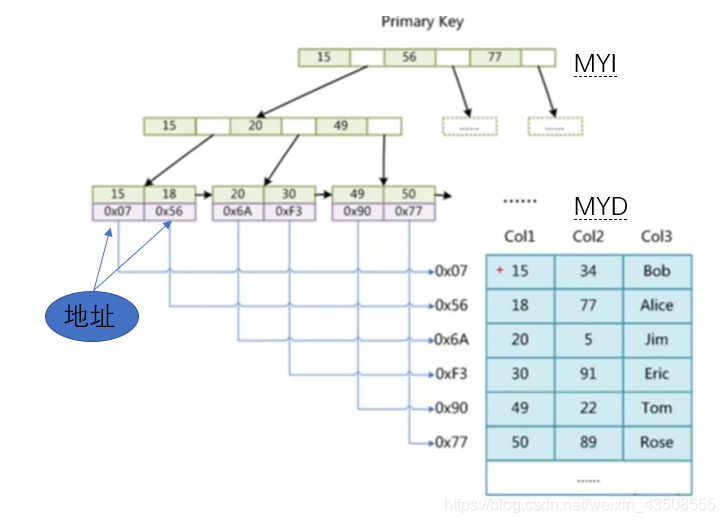
select * from t where col1 = 49;那么就通过三次IO就取到地址0x90,在MYD中查找记录
说说InnoDB
InnoDB索引实现(聚集):
- 表数据文件 本身就是按B+树组织的一个索引结构文件
- 聚集索引-------叶节点包含了完整的数据记录
创建一个表时,会创建两个文件:
- XXX.firm : 存储的是标的数据定义相关的信息,表结构
- XXX.idb : 按B+树组织的一个索引结构文件,数据在索引的叶子节点中
对比两张B+树的叶子节点,你就能明白聚集与非聚集的含义
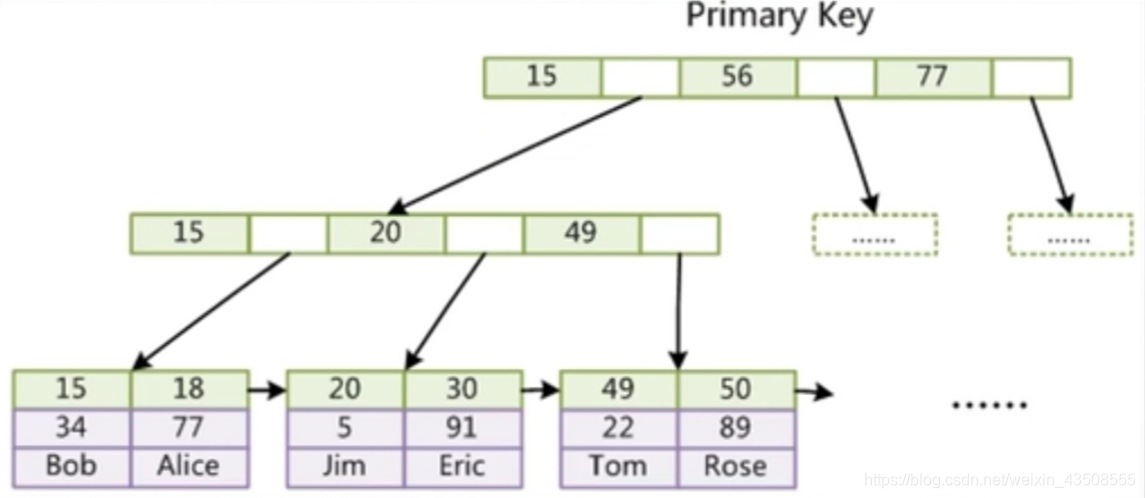
那你说说什么是聚集索引?
主键索引和数据是聚集在叶子节点上,搜索效率是高于非聚集索引的
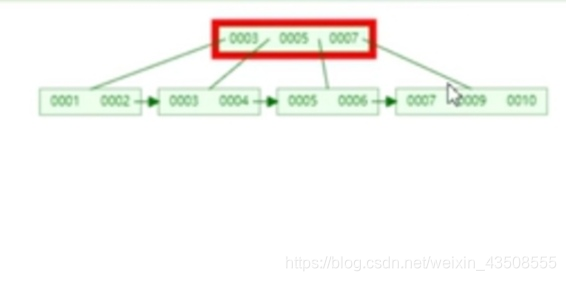
为什么InnoDB表必须有主键,并且推荐使用整型的自增型的自增主键?
- 如果没有创建主键索引,MySQL内部会选取一个可标识的列作为主键,如果找不到,他会自动生成一个默认的隐藏列,InnoDB的数据元素必须依靠主键索引创建
- 如果使用字符串(UUID)比较,先得转换成ASCII比较,比较慢,使用整型会快很多,如果是自增型,可以直接往后插,效率较快,举个例子,如果一个叶子节点已经满了,想再往进插入的时候,
会影响整个表结构,表会分裂
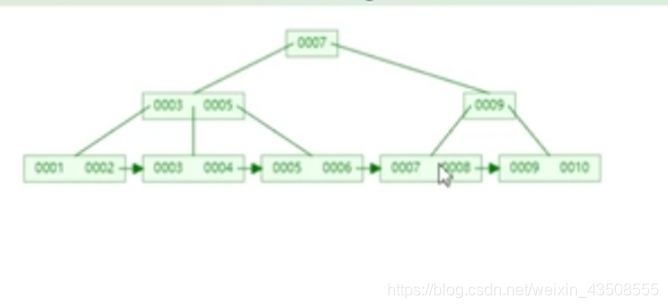
为什么
非主键索引结构叶子节点存储的是主键值?
一致性和节省存储空间
优化
联合索引的底层存储结构是什么样子
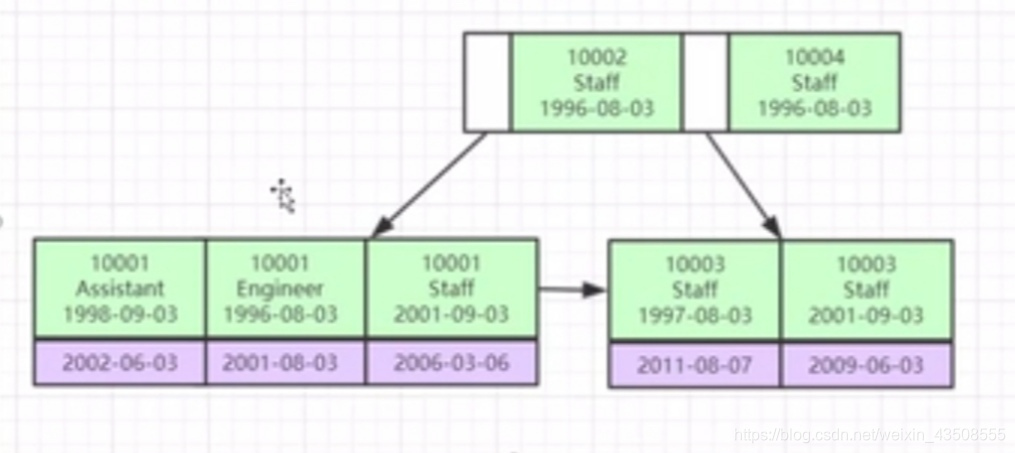
满足最左前缀匹配原则(a,b,c)先匹配a,如果a相等,匹配b,以此类推。
其实联合索引的查找就跟查字典是一样的,先根据第一个字母查,然后再根据第二个字母查,或者只根据第一个字母查,但是不能跳过第一个字母从第二个字母开始查。这就是所谓的最左前缀原理。
详细说说最左匹配原则
比如联合索引索引的例子(a,b,c).下面的索引都可以用到:
select * from t where a=1;//(a)
select * from t where a=1 and b=2;//(a,b)
select * from t where a=1 and b=2 and c=3; // (a,b,c)
再比如说:
select * from t where a=1 and c=3;// 只会用到索引aselect * from t where b=1 and c=2;// 没有用到索引,会查询到索引,辅助索引查主键索引如果是这样
select * from table where b=2 and a=1;
select * from table where b=2 and a=1 and c=3;mysql查询优化器会判断纠正这条sql语句该以什么样的顺序执行效率最高,最后才生成真正的执行计划。但我们还是最好按照索引顺序来查询,这样查询优化器就不用重新编译了。
听说过前缀索引吗?
- 就是列的前缀作为索引,比如
like 'XXX%',但是像like '%xx%不会用到前缀索引 - MySQL 前缀索引能有效减小索引文件的大小,提高索引的速度。
- 但是前缀索引也有它的坏处:MySQL 不能在
ORDER BY或GROUP BY中使用前缀索引,也不能把它们用作覆盖索引(Covering Index)。
简单说说你知道的索引优化策略
-
最左前缀匹配原则
-
一定要建主键索引
-
对
where,on,group by,order by中出现的列使用索引 -
尽量选择
区分度高的列作为索引,区分度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是1,而一些状态、性别字段可能在大数据面前区分度就是0 -
对较小的数据列使用索引,这样会使索引文件更小,同时内存中也可以装载更多的索引键
-
索引列不能参与计算,保持列“干净”,比如
from_unixtime(create_time) = ’2014-05-29’就不能使用到索引,原因很简单,b+树中存的都是数据表中的字段值,但这个进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。所以语句应该写成create_time = unix_timestamp(’2014-05-29’) -
为较长的字符串使用前缀索引
-
尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可
-
不要过多创建索引, 权衡索引个数与DML之间关系,DML也就是插入、删除数据操作。这里需要权衡一个问题,建立索引的目的是为了提高查询效率的,但建立的
索引过多,会影响插入、删除数据的速度,因为我们修改的表数据,索引也需要进行调整重建 -
对于like查询,"%"不要放在前面
SELECT * FROM t WHERE uname LIKE'后盾%' -- 走索引
SELECT * FROM t WHERE uname LIKE "%后盾%" -- 不走索引·
-- 查询where条件数据类型不匹配也无法使用索引 - 字符串与数字比较不使用索引
CREATE TABLE a (a char(10));
EXPLAIN SELECT * FROM a WHERE a="1" – 走索引
EXPLAIN SELECT * FROM a WHERE a=1 – 不走索引
- 正则表达式不使用索引,这很好理解,类似前缀索引,所以为什么在SQL中很难看到regexp关键字的原因
