一、统计基础
1.总体和样本:总体的分布一般来说是未知的,统计学的主要任务正是要对总体的未知分布,进行判断。
由样本判断总体过程:数据资料的收集---->数据的整理、分析---->统计推断
设总体的概率分布为p(x)=P{X=x},则样本的概率分布为:P(x1,x2,x3…,xn)=P{X1=x1,X2=x2…Xn=xn}。
2.统计量:设X1,X2,…Xn是总体X的一个样本,则称此样本的任一不含总体的未知参数的函数g(X1,X2,…Xn)为该样本的统计量。
样本均值:X=1/n(X1+X2…+Xn)
未修正的样本方差:S²=(1/n)×(X1-X)²+(X2-X)²。。。+(Xn-X)²)
修正的样本方差:S²=(1/(n-1))×((X1-X)²+(X2-X)²。。。+(Xn-X)²)
样本越大得到的结果越准确
3.抽样分布
(1.分位数

那么可以得到:P{X>Fα}=α,则称Fα为随机变量X的α水平的上侧分位数,简称α上侧分位数。
(2.卡方分布的定义:设X1,X2.。。Xn是来自标准正态分布的样本,则X1²+X2²。。。++Xn²是卡方分布

(3.t分布:设随机变量X服从标准正态分布N(0,1),Y服从卡方分布,且X与Y相互独立
记:
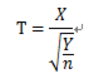
则,随机变量T服从自由度为n的t分布,T~t(n).

(4.F 分布:设X是自由度为m的卡方分布,Y是自由度为n的卡方分布,X和Y相互独立。
记Z=nX/mY
则Z的密度函数为f(x;m,n),因此Z~F(m,n)

特别当σ1²=σ2²时,统计量”两个样本方差之比“服从F分布,即:
F=S1²/S2~F(n1-1,n2-1)
(5公式总结:
公式1:(1)X=1/n(X1+X2…+Xn)~N(μ,σ²/n)
公式2: (2) U=X-μ/(σ/平方根n)~N(0,1)
公式3: (3)(n-1/σ²)×S²~卡方(n-1) #实在不会打了。。。
公式4:(4)T=(X-μ)/(S/平方根n)~t(n-1)
具体情况具体分析,下面再给大家讲什么情况下用哪个。
4.点估计:使用来自通体X的样本值构造一个统计量来估计总体分布的某参数的真实值,这个统计量称为某参数的估计量。
用样本均值X来估计通体的期望E(X),因为X是E(X)的无偏估计量也是其相合估计量,而且在E(X)的一切无偏估计量中X的方差最小,即最有效。
设(X1,X2,…Xn)为来自总体X的样本,其方差存在为:S²=(1/(n-1))×((X1-X)²+(X2-X)²。。。+(Xn-X)²)是方差D(X)的无偏估计量。
参数的最大估计似然:应寻找使实验结果出现的可能性最大的哪个θ作为θ真知的估计值。
L(θ1,θ2.。。θm)=P{X1=x1,X2=x2,…Xn=xn}=∏(上面是n,下面是i=1)p(xi;θ1,θ2.。。θm)
即L(θ1,θ2.。。θm)=max L(θ1,θ2.。。θm)
则称θ1,θ2.。。θm分别为θ1,θ2.。。θm的极大似然估计
解题过程:设总体X~N(μ,σ²),σ²和μ未知,(X1,X2,…Xn)为来自总体X的样本,(x1,x2/…,xn为样本值,求μ,σ²的最大似然估计。
(1)写出似然函数 L(θ1,θ2.。。θm)
似然方程组:
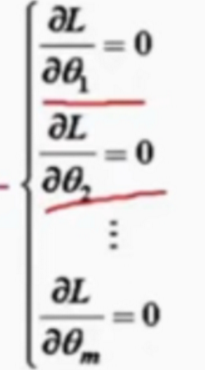
(2)取对数ln(L(θ1,θ2.。。θm))
过程(私藏了好久的图片):

例子:设考的分数X~N(μ,σ²),其中μ,σ²未知只知道样本值为,60,70,80,90,50,40,30,20,10,0.s试着估计μ,σ²的值。(你们照着过程试一下,我写字拍照,字不好看,不好在电脑上打过程,大家需要的话评论区说一下,或者大家讨论一下)
所谓参数θ的点估计,是指用一个估计量θ(X1,X2…Xn)的值去估计θ的真值,但是估计的好坏就没有指出,没有可靠性。所以我们需要引入区间估计。
5.区间估计:设θ是总体X的分布的位置参数,X1,X2…Xn为来自X的样本。对给定的α(大于0小于1),若存在两个统计量θ=θ(X1,X2…Xn)和θ1=θ1(X1,X2…Xn),使得:P{θ1<θ<θ}=1-α。则随机区间(θ1,θ)称为参数θ的1-α置信区间;1-α为置信水平(置信度);θ1与θ为置信下限和置信上限。
(1)正态分布的μ的区间估计:σ已经知道,μ未知,X1,X2…Xn来自X的一个样本,x1,x2…xn为样本值,α=0.05,求μ的置信区间。
可以知道我们用公式2。

(2)总结:



二、numpy补充(之前只是讲了一些数据分析数据可视化有关的现在再深入学习一下,可以复习一下之前的):
import numpy
numpy.array()
#生成矩阵的常规方法
numpy.zeros([10,10])
#[[0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
# [0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
# [0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
# [0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
# [0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
# [0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
# [0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
# [0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
# [0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
# [0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]]
#生成10×10的矩阵
numpy.ones([5,5])
得到[[1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1.]]
5×5的向量
numpy.eye(1)
[[1.]]
生成单位矩阵
a=numpy.array([[1,0,0,0,0],[1,0,0,0,0]])
print(a.dtype)
#int32,得到的是数据的格式
print(a.shape)
#(2, 5)得到的是行列
a.copy()
#复制
产生数组:
x=numpy.linspace(0,10,20)
#从0开始到10二十个数
[ 0. 0.52631579 1.05263158 1.57894737 2.10526316 2.63157895
3.15789474 3.68421053 4.21052632 4.73684211 5.26315789 5.78947368
6.31578947 6.84210526 7.36842105 7.89473684 8.42105263 8.94736842
9.47368421 10. ]
x,y=numpy.meshgrid(numpy.arange(10),numpy.arange(10))
x是[[0 1 2 3 4 5 6 7 8 9]
[0 1 2 3 4 5 6 7 8 9]
[0 1 2 3 4 5 6 7 8 9]
[0 1 2 3 4 5 6 7 8 9]
[0 1 2 3 4 5 6 7 8 9]
[0 1 2 3 4 5 6 7 8 9]
[0 1 2 3 4 5 6 7 8 9]
[0 1 2 3 4 5 6 7 8 9]
[0 1 2 3 4 5 6 7 8 9]
[0 1 2 3 4 5 6 7 8 9]]
y是[[0 0 0 0 0 0 0 0 0 0]
[1 1 1 1 1 1 1 1 1 1]
[2 2 2 2 2 2 2 2 2 2]
[3 3 3 3 3 3 3 3 3 3]
[4 4 4 4 4 4 4 4 4 4]
[5 5 5 5 5 5 5 5 5 5]
[6 6 6 6 6 6 6 6 6 6]
[7 7 7 7 7 7 7 7 7 7]
[8 8 8 8 8 8 8 8 8 8]
[9 9 9 9 9 9 9 9 9 9]]
x和y是转置的,这样可以形成二维数组。
逻辑操作:
numpy.where(x>y,x,y)
#如果x大于y则返回x,否则返回y
排序相关:
sort(axis)
unique()
numpy计算常用函数:
-abs,fabs
-sqrt,square.exp.log,log^,loglp
_sign,ceiling,floor,modf
-isnan,isfinite,isinf
-cos,sin,tan,arccos,arcsin,arctan
-add,substract,multiply,divide,power
-maximum,minimum,mod,copysign
-greater,greater_equal,less.less_equal
这是一些随机数据的获取和排列的方法:
import numpy.random
随机数据
rand(d0,d1,...,dn)
randn(d0,d1...,dn) +sigma*np.random.randn(...)+mu#mu是μ,sigma是σ
randint(low[,high,size])
random_integers(low[,high,size])
choice(a[,size,replace,p])
排列
shuffle(x)
permutation(x)
下面是一些科学的方法:

例子:一只股票每日预期收益为0.1%,每日波动率为0.5%。估计100日后的预期收益。
import numpy
mu=0.1
sigma=0.5
x=numpy.random.randn(100)#随机100个数据
y=sigma*x+mu#这是每天的变化
print(y.sum(0))
#得到的预期的数据6.882836364654396
不明白的咱们可以讨论一下。
