这节课讲述了数组相关的内容。
首先是如何定义数组。
数组是一种引用数据类型,它是一组有序的相同类型的数据,这些数据紧挨在一起有序排在内存中,就是数组。
定义一个普通的变量例如 int a;那么定义一个由int类型组成的数组只需加上[]。例如int [] a。经过试验,int a []这种定义方法也可以。
当一个数组被定义完成后需要定义它的储存数据的数量。可以通过int [] a = new int[10],来定义一个储存十个整型变量的一维数组。也可以直接int [] a = {10,10123,124,15315,64},定义这个数组储存5个整形变量,并且给每个空间都附上了自定义的值。之前new的方法同样给空间附上了初值,但并非是自定义的值,而是默认值0。如果数组类型是float,则是0.0,是布尔类型则为false。
有时方便理解的一维数组不能满足程序设计的需要,那么就需要定义二维数组。定义方法同一维数组差不多,只是多加了一个[],例如int [][] a;。经过试验,第一个中括号可以解释为一个一维数组,第二个中括号解释为之前的一维数组中又储存的一个一维数组,而它的定义方法也很好的体现了这一点。int [][] a = {{123,123,123},{321,321,321}};。观察可得这是在一个每个成员都为一维数组的一维数组,即为二维数组。
二维数组的理解可发展为高维数组,但高维数组一般在项目中的使用频率不高,二维数组能应付绝大多数的情况。例如四维数组int [][][][]a = new int [2][2][2][2];可以通过一幅图理解。
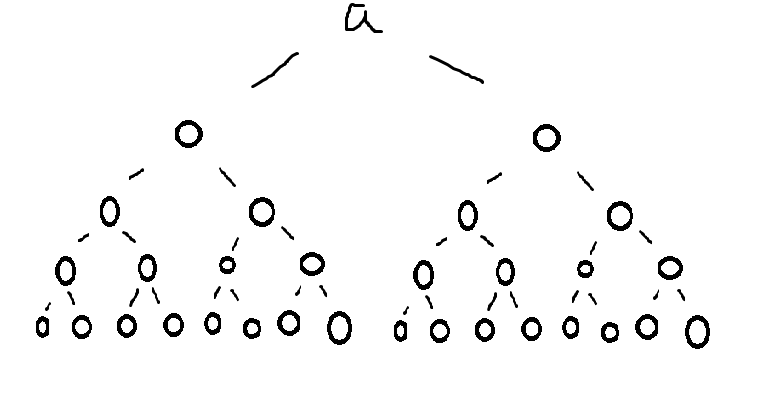
每一次的分叉都是向右侧进入下一个[],最下方的一排圆圈就是变量,其余为数组。
特别的,使用穷举法定义数组时不能
int [] a;
a={10,10};
这在语法上是不允许的。
int [] a;
a = new int[]{10,10};
则可以。
二维与高维数组有对称与非对称的差异。
int a[][] = new int[3][]; a[0] = new int[1]; a[1] = new int[2]; a[2] = new int[3];
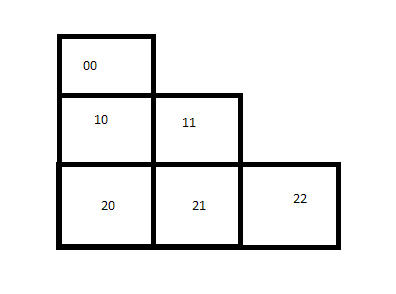
以上方法定义的二维数组并非像普通的int a[][] = new a[2][2];一样是个方形,它不对称。
在for循环中有一种特殊的循环方式
for(int b : array)
这是遍历数组的循环方式,它可以遍历数组,取出数组中的每一个元素。
对于一维数组,很明显一层循环就能够取出所有的元素。而对于二维数组,则需要两层循环,三维则需要三层。
二维数组的遍历:
for(int b[] : array)
for(int c : b)
这样做的原因是因为第一层遍历数组时取出的元素是一个一维数组,需要再对它进行遍历才能取出其中的元素。
传值与引用
观察如下代码
public class Main{
public static void change(int a){
a = 10;
}
public static void main(String arg[]){
int a = 5;
change(a);
System.out.println(a);
}
}
输出为5
表面上看方法是将a赋值为10,但是为什么输出为5?这就涉及到了函数的传值。
传值是将变量的值传递至函数中进行计算,而变量本身的值不会发生变换。也就是说实参a将自己的值5传递到了change()方法中的形参a。change()方法给形参a赋值为10。很明显形参a和实参a没有过多交集,仅仅是实参a将值传递给了形参a。
再看如下代码
public class Main{
public static void change(int a[]){
a[0] = 10;
}
public static void main(String arg[]){
int a[] = {1,2,3};
change(a);
System.out.println(a[0]);
}
}
输出结果为10
那么这与之前的代码有何不同?重点在于此次的参数传递为引用传递。
这次将数组a的地址传递到了change()方法中,方法内部通过下标获取了数组a的第一个元素,并将其赋值为10。引用传递与传值最大的区别是一个传递变量的地址,一个传递变量的值。
将变量的地址传递到方法中可以使方法直接对变量进行操作,而不必像传值一样需要将值传递到形参中,再对形参进行操作。直接对变量进行操作的结果就是可以改变变量的值。
排序
原本ppt上是有两个排序,冒泡排序和插入排序,但可能是因为时间原因,只讲了冒泡排序,第二天讲了插入排序。
对于升序排序,冒泡排序的原理就是比较相邻两个元素的值,将较小的一方向左移动,直到左边不再比这个元素小。这可能是最简单的一种排序,不做过多介绍。
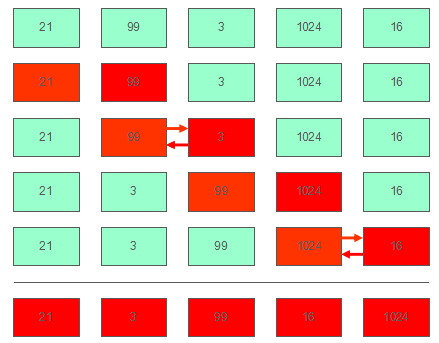
示意图一
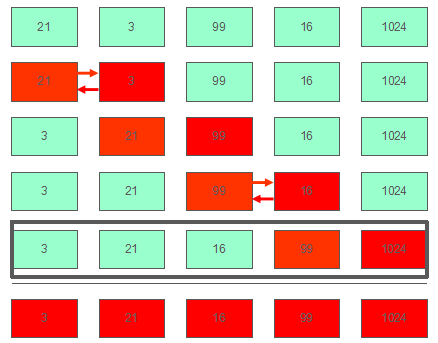
示意图二
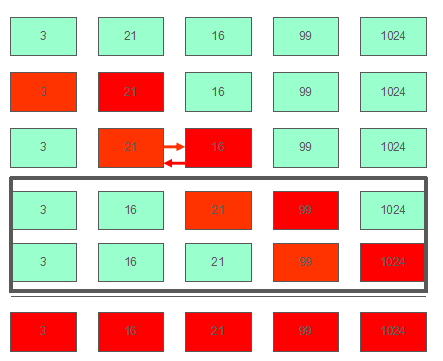
示意图三