Cassandra是一个开源的、分布式、无中心节点、弹性可扩展、高可用、容错、一致性协调、面向列的NoSQL数据库
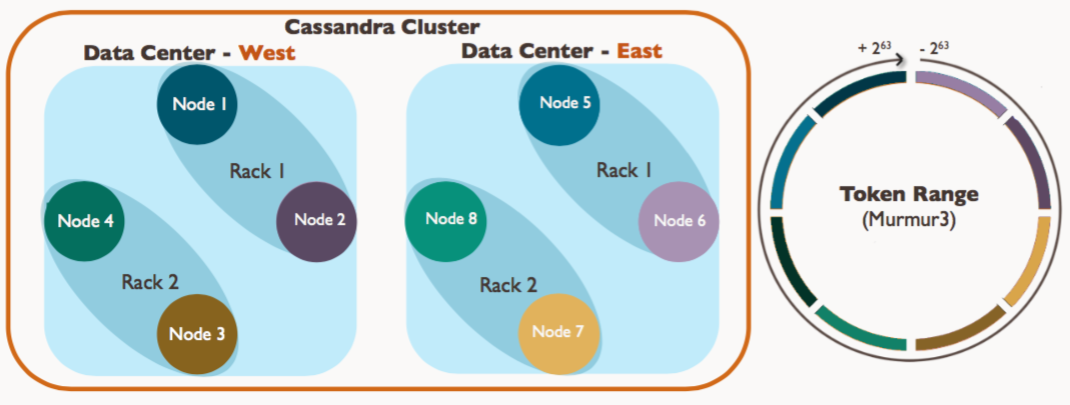
Cassandra集群的定义
- Cluster
- Data center(s)
- Rack(s)
- Server(s)
-
Node (more accurately, a vnode)
-
- Server(s)
- Rack(s)
- Data center(s)
- Node(节点):一个运行cassandra的实例
- Rack(机架):一组nodes的集合
- DataCenter(数据中心):一组racks的集合
- Cluster(集群):映射到拥有一个完整令牌圆环所有节点的集合
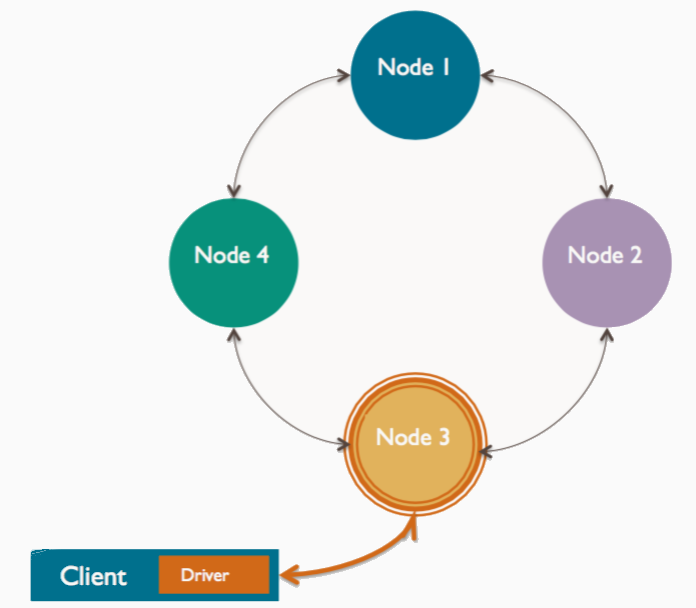
协调者(协调节点)
客户端连接到某一节点发起读写请求时,该节点充当客户端应用与集群中拥有相应数据节点间的桥梁,称为协调者,以根据集群配置确定环(ring)中的哪个节点应当获取这个请求。
使用CQL连接指定的-h节点就是协调节点
- 集群中任何一个节点都可能成为协调者
- 每个客户端请求都可能由不同的节点来协调
- 由协调者管理复制因子(复制因子:一条新数据应该被复制到多少个节点)
- 协调者申请一致性级别(一致性级别:集群中有多少节点必须相应读写的请求)
分区器
分区器决定了数据如何在集群内被分发。在Cassandra中,table的每行由唯一的primarykey标识,partitioner实际上为一hash函数用,以计算primary key的token。Cassandra依据这个token值在集群中放置对应的行。
Cassandra提供了三种不同的分区器
- Murmur3Partitioner(默认)- 基于MurmurHash hash值将数据均匀的分布在集群
- RandomPartitioner - 基于MD5 hash值将数据均匀的分布在集群中
- ByteOrderedPartitioner - 通过键的字节来保持数据词汇的有序分布
虚拟节点
每个虚拟节点对应一个token值,每个token决定了节点在环中的位置以及节点应当承担的一段连续的数据hash值的范围,因此每个节点都拥有一段连续的token,这一段连续的token,组成了一个封闭的圆环。
没有使用虚拟节点, Ring环的tokens数量=集群的机器数量. 比如一共有6个节点,所以token数=6.因为副本因子=3,一条记录要在集群中的三个节点存在. 简单地方式是计算rowkey的hash值,落在环中的哪个token上,第一份数据就在那个节点上,剩余两个副本落在这个节点在token环上的后两个节点.
图中的A,B,C,D,E,F是key的范围,真实的值是hash环空间,比如0~2^32区间分成10份.每一段是2^32的1/10.节点1包含A,F,E表示key范围在A,F,E的数据会存储到节点1上.以此类推.
若不使用虚拟节点则需手工为集群中每个节点计算和分配一个token。每个token决定了节点在环中的位置以及节点应当承担的一段连续的数据hash值的范围。如图上半部分,每个节点分配了一个单独的token代表环中的一个位置,每个节点存储将row key映射为hash值之后落在该节点应当承担的唯一的一段连续的hash值范围内的数据。每个节点也包含来自其他节点的row的副本。
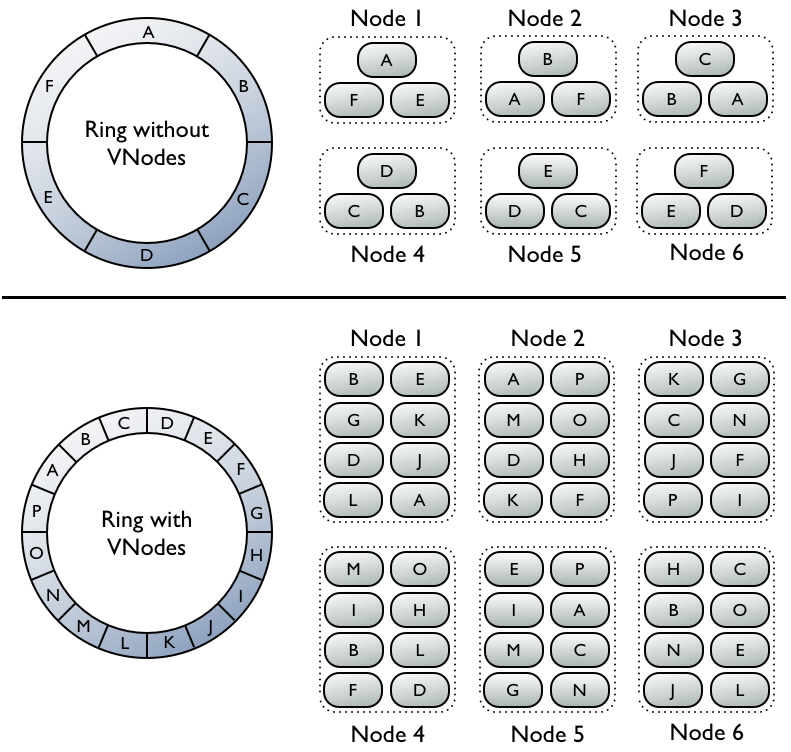
而使用虚拟节点允许每个节点拥有多个较小的不连续的hash值范围。如图中下半部分,集群中的节点使用了虚拟节点,虚拟节点随机选择且不连续。数据的存放位置也由row key映射而得的hash值确定,但是是落在更小的分区范围内。
使用virtual nodes的好处
- 无需为每个节点计算、分配token
- 添加移除节点后无需重新平衡集群负载
- 重建异常的节点更快