项目说明:
如何在网络中确定一个机子: ip + 端口号
ip : 表示网络中唯一标识
端口号: 计算机程序的唯一标识
协议: tcp /udp
项目难点:
在开始打算学习这个项目的时候,最开始的目的是学习Scala这门语言,我自身感觉这门语言比Python还要简单,但这也是自身感觉,首先去官网下载Scala配置文件(https://www.scala-lang.org/),安装之后就可以cmd命令行去执行代码,在做分布式计算项目中,在IDEA中配置Scala环境浪费啦大量时间,因为IDEA必须要与Scala插件版本相去对应才可以在IDEA打代码,还有就是导入maven中依赖信息配置不上,最后就是Scala的学习,总体项目划算简单,就是总是出现小毛病(小毛病才最烦人)
IDEA配置Scala插件:
Scala是一个多范式的编程语言(支持多种方式的编程)
*** 使用面向对象编程:封装、继承、多态<.li>

*** 使用函数式编程:最大的特定(优点:代码非常简洁;缺点:可读性太差)
1、 首先要配置Java环境变量,设置好JDK
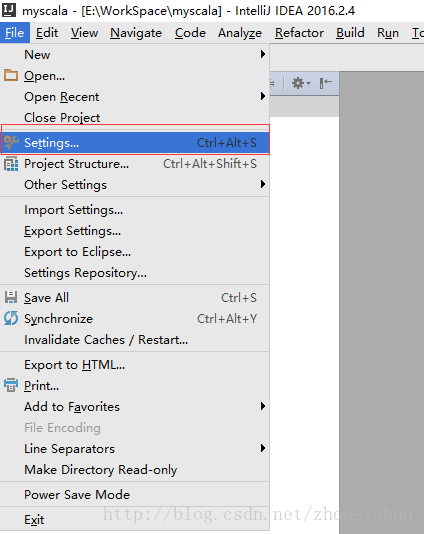
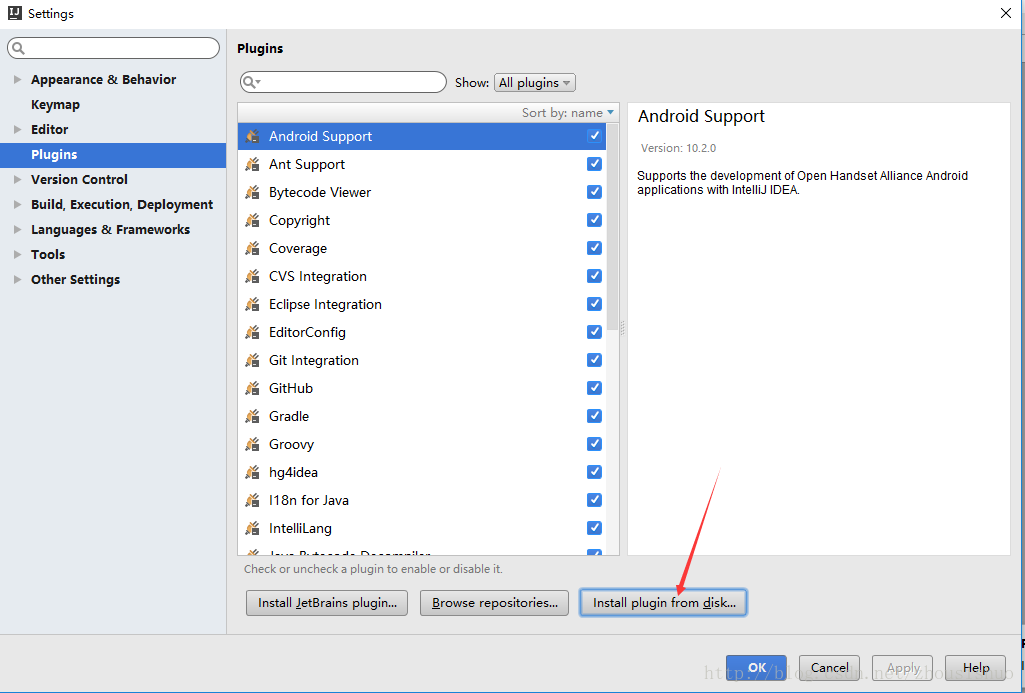
2、IDEA版本低: 按照如图所示配置插件


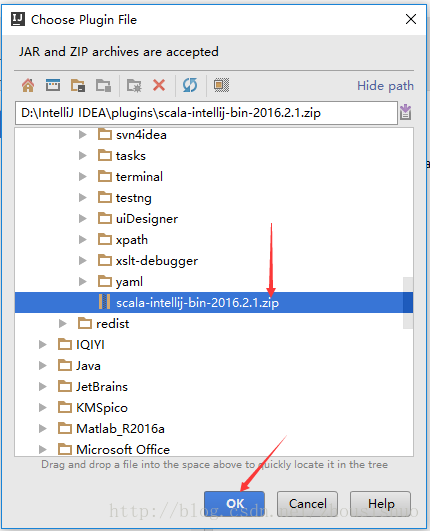
3、IDEA版本高:跟上图操作一样,去官网选择对应的Scala版本。
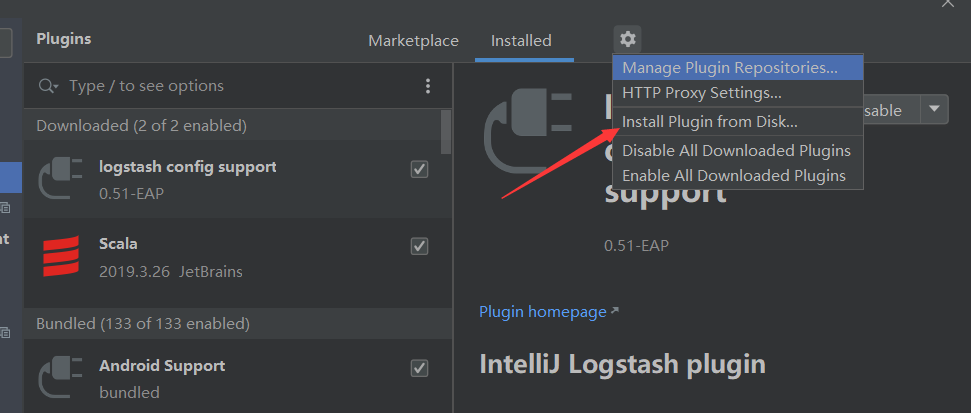
mavan依赖导入:
1、自动导包打开
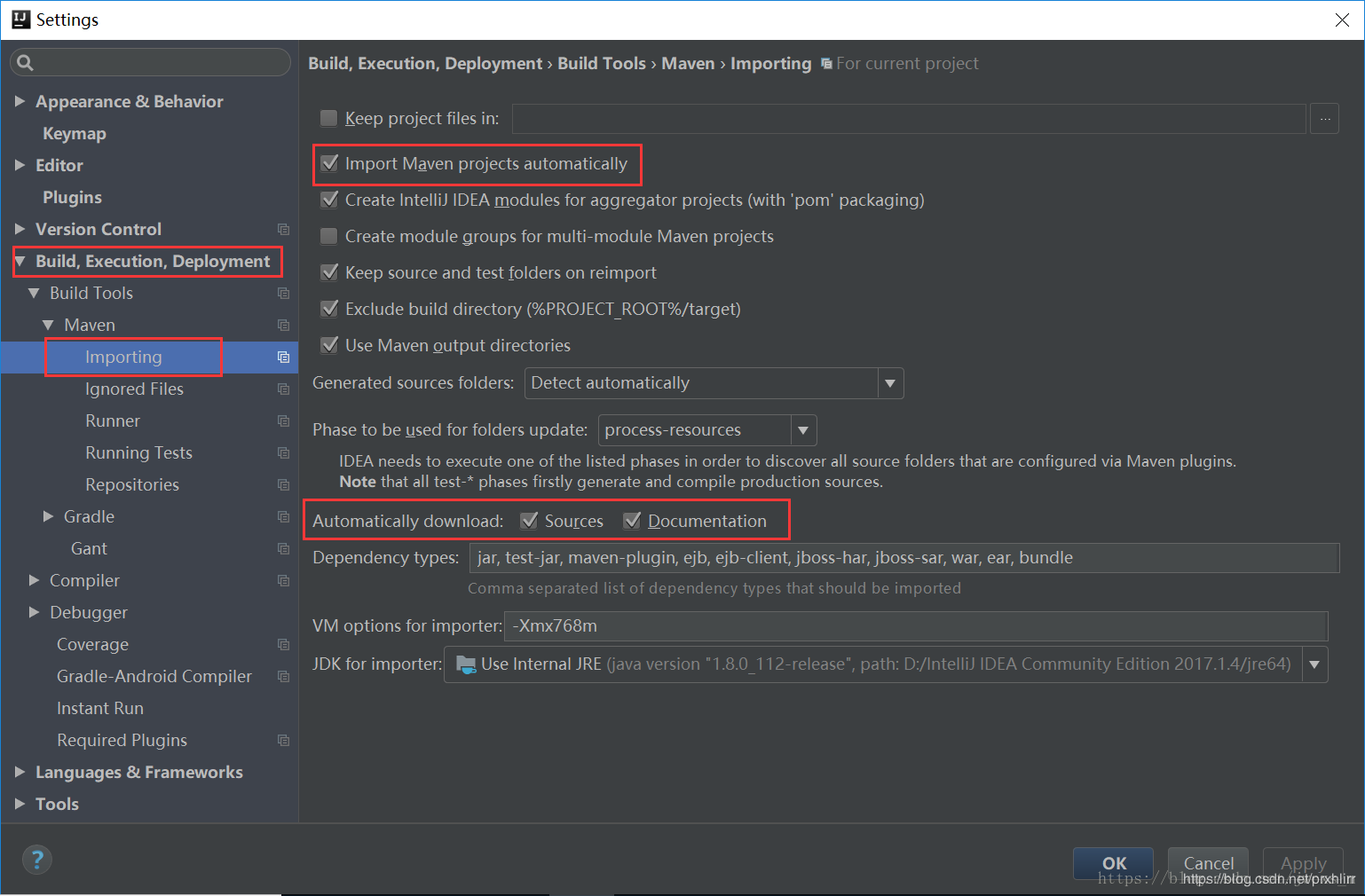
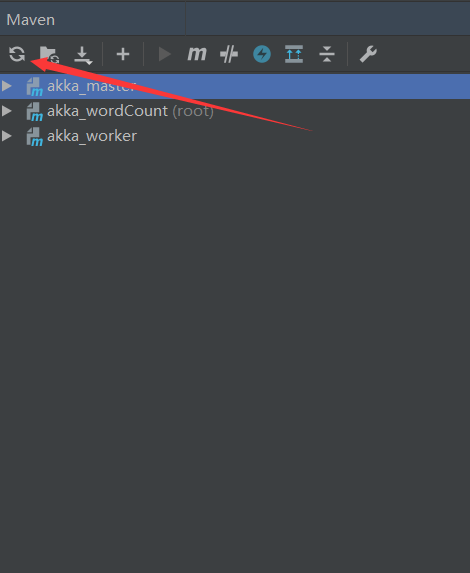
2、把pom.xml中对应的依赖先删除,然后刷新右侧,之后再把依赖粘贴到pom.xml中,再次刷新右侧就好了并且从本地仓库将对应的包删除掉,然后让maven重新下载
3、不断刷新,或者退出从新进入
Akka并发编程框架
Akka介绍
Akka是一个用于构建高并发、分布式和可扩展的基于事件(消息)驱动的应用的工具包。Akka是使用scala开发的库,同时可以使用scala和Java语言来开发基于Akka的应用程序。
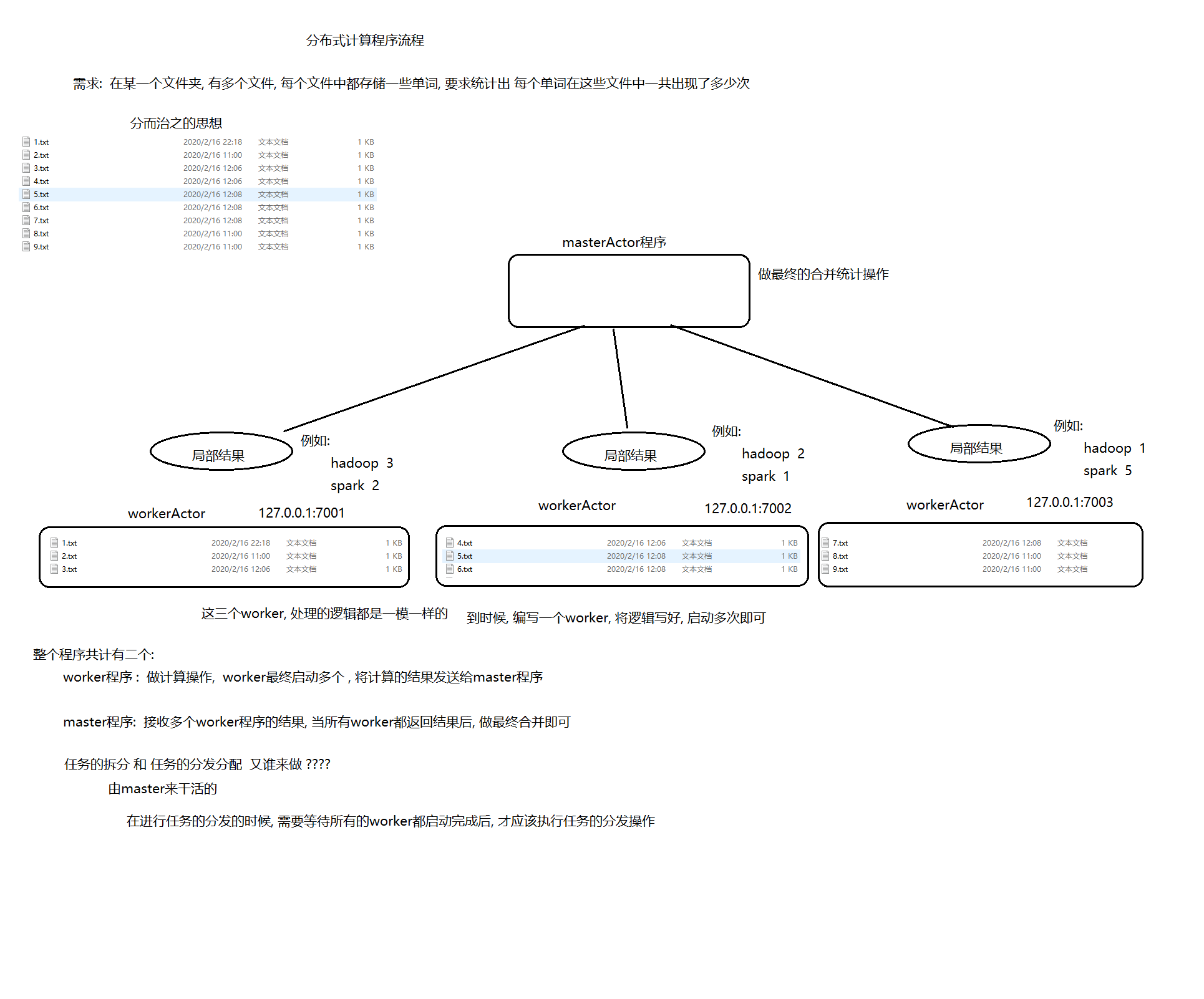
什么是分布式?
分布式指的是将一个业务或者一个程序也或者说一个模块, 拆分成多个子业务, 子程序或者子模块的过程, 各个子业务, 子程序或者子模块分别运行在不同的节点或者进程中, 数据在不同的进程间进行传递,共同实现某一个目标的过程, 我们将这样的方式成为分布式
Akka的特性
- 提供基于异步非阻塞、高性能的事件(消息)驱动**编程模型**
- 内置容错机制,允许Actor在出错时进行恢复或者重置操作
- 超级轻量级的事件处理(每GB堆内存几百万Actor)
- 使用Akka可以在单机上构建高并发程序,也可以在网络中构建分布式程序。
Akka通信过程
Akka Actor的并发编程模型的基本流程:
1. 学生创建一个ActorSystem
2. 通过ActorSystem来创建一个ActorRef(老师的引用),并将消息发送给ActorRef
3. ActorRef将消息发送给Message Dispatcher(消息分发器)
4. Message Dispatcher将消息按照顺序保存到目标Actor的MailBox中
5. Message Dispatcher将MailBox放到一个线程中
6. MailBox按照顺序取出消息,最终将它递给TeacherActor接受的方法中
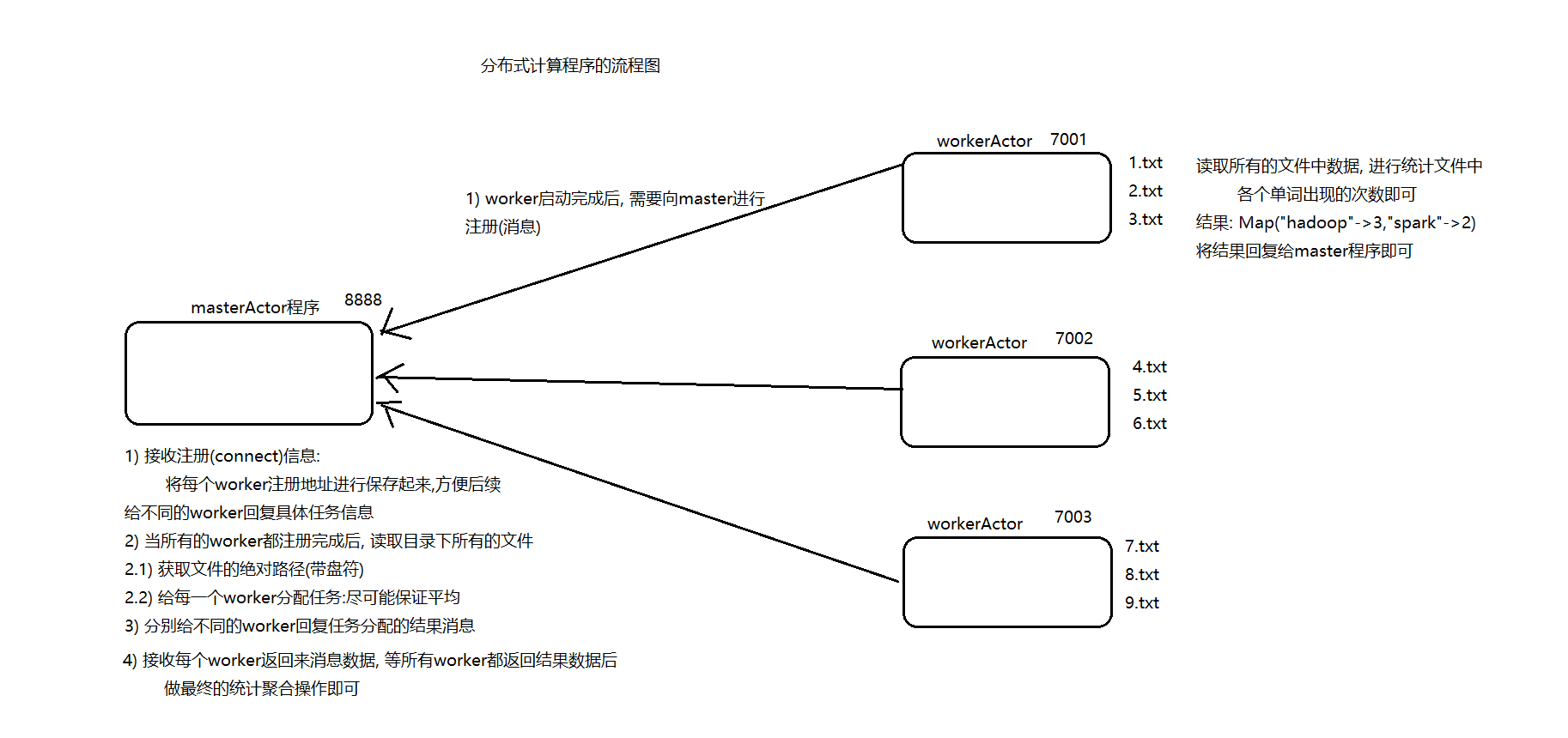
akka的通信地址
**Actor Path**
每一个Actor都有一个Path,这个路径可以被外部引用。路径的格式如下:
| Actor类型 | 路径 | 示例 |
| 本地Actor | akka://actorSystem名称/user/Actor名称 | akka://SimpleAkkaDemo/user/senderActor |
| 远程Actor | akka.tcp://my-sys@ip地址:port/**user**/Actor名称 | akka.tcp://192.168.10.17:5678/user/service-b |
Scala学习笔记就不赘述啦,有java的基础,总的来说Scala是算入门啦!!!
代码:
package cn.itcast.akka import akka.actor.Actor import scala.io.Source object WorkerActor extends Actor{ override def receive: Receive = { // 当接收到setup消息后, 想master进行注册即可 case "setup" => { println("接收到setup消息, 当前actor已经启动了,准备开始注册....") // 获取到master的地址: val masterActor = context.actorSelection("akka.tcp://[email protected]:8888/user/masterActor") // 发送注册消息 masterActor ! "connect" } // 接收master发送过来的任务 case filePaths:String =>{ // 类型匹配操作 println("接收到任务:" + filePaths) val filePathArr: Array[String] = filePaths.split(" ") // Source.fromFile(filePath).getLines().toList : 根据传递进去的文件的绝对路径, 一行一行读取, 将每一行都 //放置在一个List集合中 /* allFileLineList放置的内容是所有的文件的每一行内容 hadoop spark hadoop spark hadoop spark spark spark spark */ val allFileLineList: Array[String] = filePathArr.flatMap(filePath => Source.fromFile(filePath).getLines().toList ) // 对每一行的数据进行切割操作: /* allWords结果: hadoop spark hadoop spark hadoop spark spark spark spark */ val allWords: Array[String] = allFileLineList.flatMap(line => line.split(" ")) // 进行统计操作: 先分组, 将相同的单词放置在一起 然后个数 val allWordsgRroups: Map[String, Array[String]] = allWords.groupBy(item => item) val res: Map[String, Int] = allWordsgRroups.map(group =>(group._1,group._2.size)) // 得到一个局部的结果了 println(res) sender() ! res } } }
package cn.itcast.akka import akka.actor.{ActorSystem, Props} import com.typesafe.config.ConfigFactory // worker端地址: akka.tcp://[email protected]:7001/user/workerActor object WorkerMain { def main(args: Array[String]): Unit = { //1. 创建actorSystem对象 val actorSystem = ActorSystem("actorSystem",ConfigFactory.load()) //2. 加载程序类, 启动 val workerActor = actorSystem.actorOf(Props(WorkerActor),"workerActor") //3. 发送 setup 消息, 让其进行向master实现注册操作 workerActor ! "setup" } }
package cn.itcast.akka import java.io.File import akka.actor.{Actor, ActorRef} import scala.collection.mutable import scala.collection.mutable.ListBuffer object MasterActor extends Actor{ // 定义一个存储worker端注册地址的列表 val regAddressList = ListBuffer[ActorRef]() // 可变的list var taskPart = mutable.Map[ActorRef,String]() // 可变的map // 定义一个用来接收局部结果的操作 val aggResList = ListBuffer[Map[String,Int]]() // 可变的list override def receive: Receive = { // 接收所有worker的注册消息 case "connect" => { // 将注册地址存储到regAddressList中, 方便后续进行回复消息 regAddressList += sender() println("当前是第" + regAddressList.size +"个 注册成功了, 注册地址为:"+ sender().toString()) //2. 当所有的worker全部都注册完成后, 进行文件的读取操作 if(regAddressList.size ==3){ // 表示所有的worker全部注册完成 //2.1 读取文件夹中所有文件 : File对象 val fileDir = new File("E:\\传智工作\\上课\\4天使用scala实现分布式计算程序\\scala分布式案例_day04\\资料\\data") //2.2 读取这个目录下所有的文件 val allFileArr: Array[File] = fileDir.listFiles() //2.3 将数组中每一个file对象 都转换为 文件绝对路径 file.getAbsolutePath val allFilePath: Array[String] = allFileArr.map(file => file.getAbsolutePath ) // array数组中存储类似于: E:\传智工作\上课\4天使用scala实现分布式计算程序\scala分布式案例_day04\资料\data\1.txt //allFilePath.foreach(filePath => println(filePath)) //3. 进行任务的分配工作 : 保证每个worker分配的任务都是平均 (基于轮询方案) var num = 0 while(num < allFilePath.size){ if(taskPart.isEmpty){ // 如果这个map中是空的, 直接分配即可 for(regAddress <- regAddressList){ // 循环一个个worker, 给每一个worker分配任务 if(num < allFilePath.size){ taskPart = taskPart + (regAddress -> allFilePath(num) ) num = num+1 } } }else{ for(regAddress <- regAddressList){ // 循环一个个worker, 给每一个worker分配任务 if(num < allFilePath.size){ taskPart = taskPart + (regAddress -> (taskPart(regAddress) +" " + allFilePath(num) ) ) num = num+1 } } } } taskPart.foreach(item => println(item._1 +"分配任务为:" + item._2)) //4. 任务的分发: 将分配好的任务, 发送给对应worker即可 taskPart.foreach(item => { item._1 ! item._2 }) } } case aggRes:Map[String, Int] => { println(aggRes) //等待所有的局部结果全部返回后, 才应该聚合操作 aggResList += aggRes if(aggResList.size ==3){ // 扁平化处理: val aggRes: Seq[(String, Int)] = aggResList.toList.flatten val aggResGroups: Map[String, Seq[(String, Int)]] = aggRes.groupBy(item =>item._1 ) val res = aggResGroups.map(item => { item._2.reduce((agg,curr) => (agg._1,agg._2+curr._2)) } ) println(res) } } } }
package cn.itcast.akka import akka.actor.{ActorSystem, Props} import com.typesafe.config.ConfigFactory // master的地址: akka.tcp://[email protected]:8888/user/masterActor object MasterMain { def main(args: Array[String]): Unit = { //1. 创建actorSystem对象 val actorSystem = ActorSystem("actorSystem",ConfigFactory.load()) //2. 加载程序类, 启动 : 导包: alt +回车 选择 import val masterActor = actorSystem.actorOf(Props(MasterActor),"masterActor") } }
pom.xml配置信息
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<encoding>UTF-8</encoding>
<scala.version>2.11.8</scala.version>
<scala.compat.version>2.11</scala.compat.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>com.typesafe.akka</groupId>
<artifactId>akka-actor_2.11</artifactId>
<version>2.3.14</version>
</dependency>
<dependency>
<groupId>com.typesafe.akka</groupId>
<artifactId>akka-remote_2.11</artifactId>
<version>2.3.14</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer">
<resource>reference.conf</resource>
</transformer>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass></mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>