一、背景支撑
-
概念:MySQL索引的建立对于MySQL的高效运行是很重要的,索引可以大大提高MySQL的检索速度
-
常见的几种数据结构中,mysql为什么选择hash,B+Tree
2.1 二叉树

缺点:
如果是索引极端情况下会出现单边递增深度会越来越大,索引是存在磁盘中文件中,相应的IO 负载会很高
2.2 红黑树
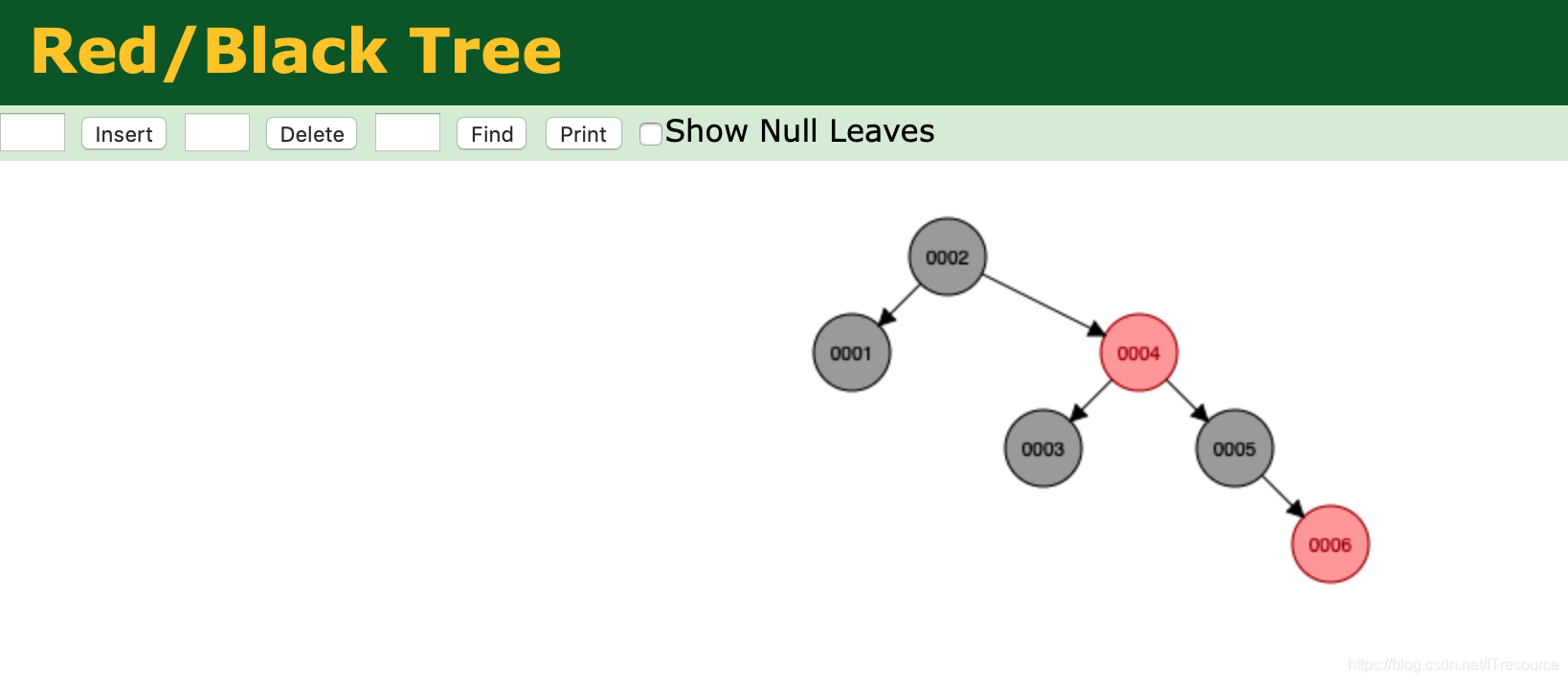
红黑树又叫做平衡二叉树,按二叉树方式插入后,会进行平衡处理
优缺点:
从上面我们发现,红黑树相比较于二叉树又进步了一些,但红黑树还是存在问题:数据量大的话,红黑树的深度会很深,仍然有很高的IO
2.3 hash

优缺点:
较二叉树(包括红黑树),hash 节点深度固定,直接映射到磁盘存储引用,无疑查询速度很快,然而范围查找时(Col1>6 )的不是很好的选择。
so 查询操作很少的话可以选择hash数据结构,查询速度快,这也是mysql的索引方法除了B+Tree还有hash的原因
2.4 B-Tree
查看数据库默认页大小
show global status like 'Innodb_page_size' ;
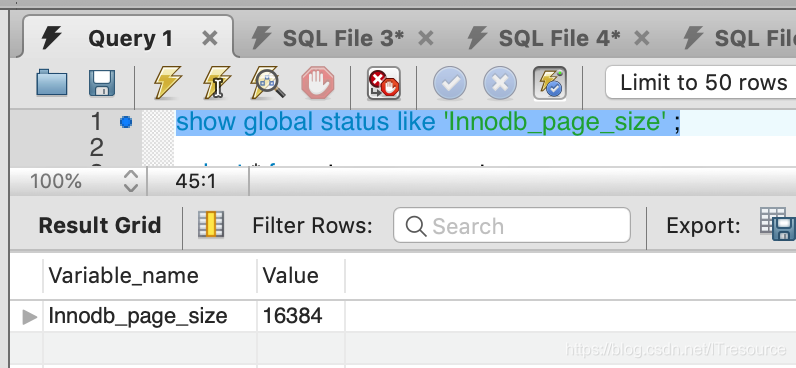
深度自己指定,但也不是越少越好
1) 为在java取数据一般是:java程序–>CPU—>内存---->硬盘,而内存与硬盘的交互是有大小限制的
2)在mysql. 中一页大小默认是16 k ,整型索引(8byte),指针(6byte)
一页可以存储。 16K / (8byte+6byte) = 1170 个索引即节点
以上情况 Degree 为 3 时 ,如果叶子结点存储的数据(data)为1K ,因为每个节点默认可以存储 16k,即可以存储 16条数据, 3层最终存储数据为 1170 * 1170 * 16 =21902400 (2kw), 深度和存储的数据量成正比,会越大
特点:
1)叶子结点具有相同的深度
2)叶节点的指针为空
3)叶节点数据Key 从左到右递增排序
优缺点:
较以上其他优点显而易见了
2.5 B+Tree
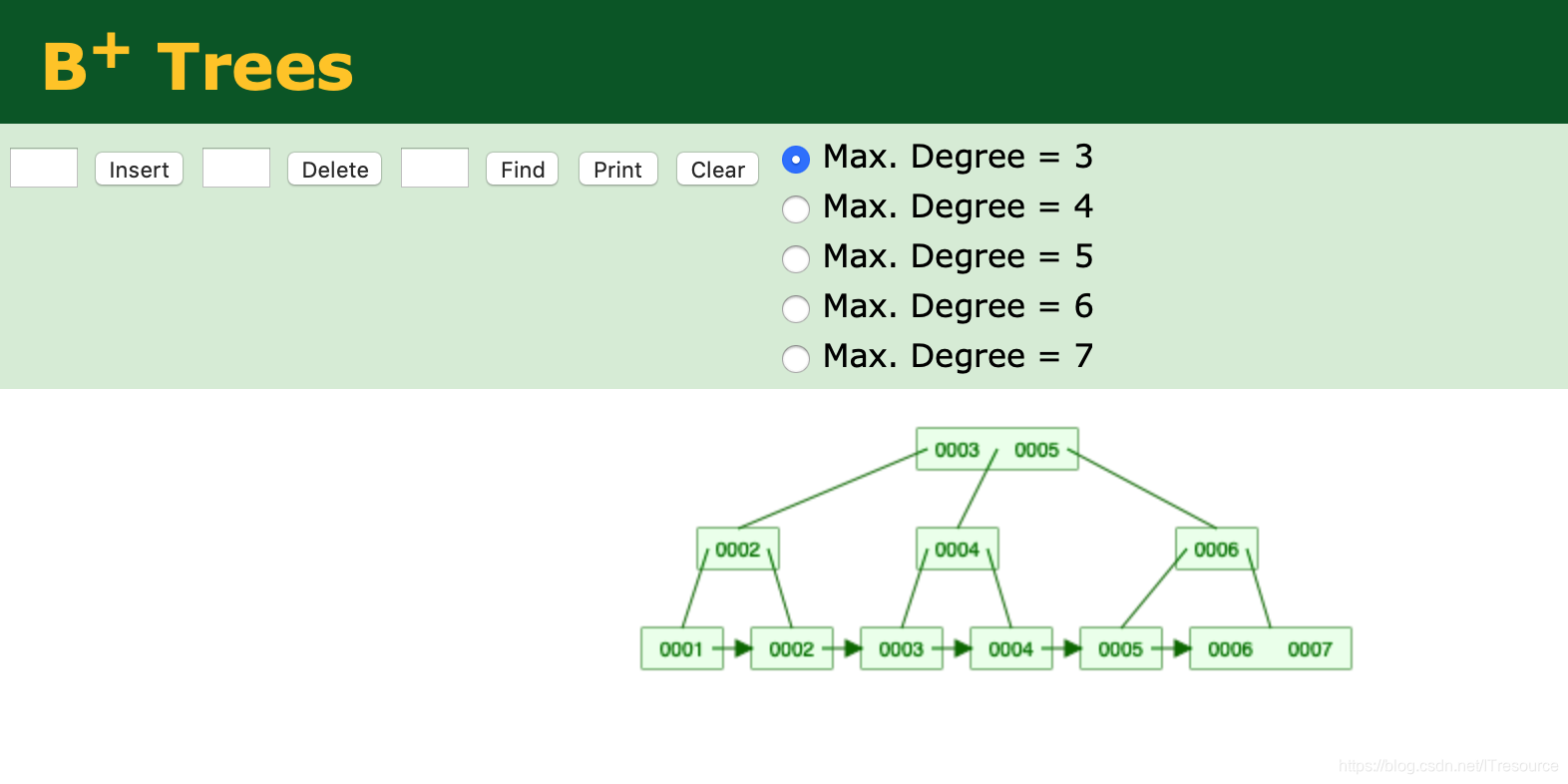
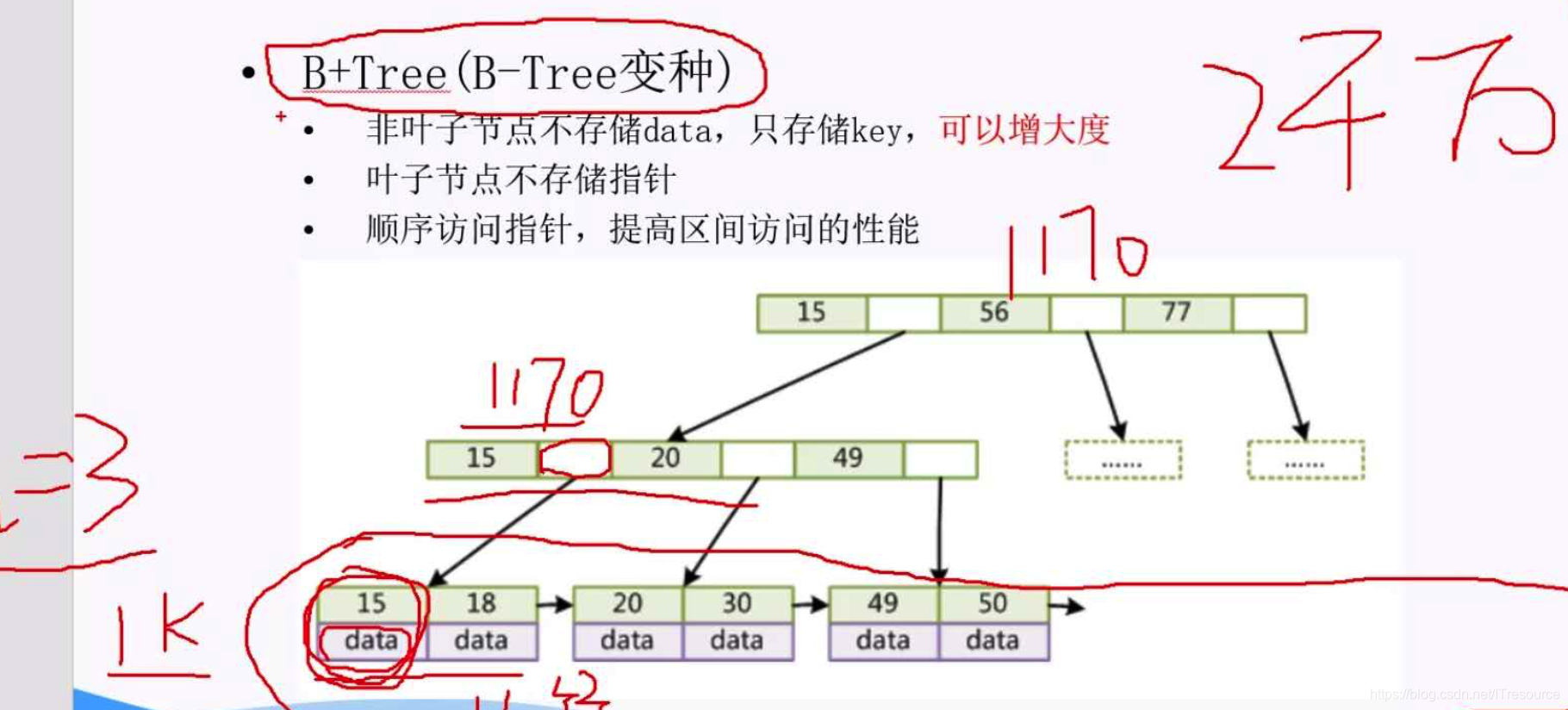
B+Tree 实际为 B-Tree 的变种
特点:
1)非叶子结点不存储data,只存储key ,可以增大度
2)叶子结点不存储指针
3)顺序访问指针,提高区间访问的性能
因为叶子结点数据都是顺序访问,像where col > 6 这种,更加方便,效率更高
二、mysql 两种数据库存储引擎 myisam & Innodb
-
myisam 索引实现(非聚集)
B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址,如图(主键索引):
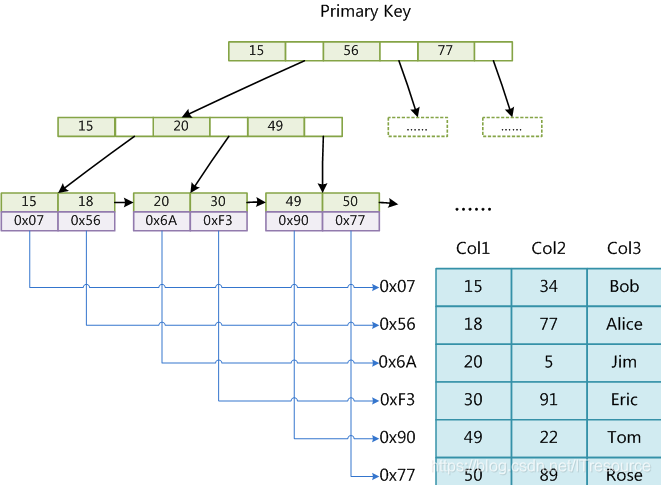
磁盘中生成三个文件 .frm(表schame).MYD(数据文件) .MYI(索引文件)
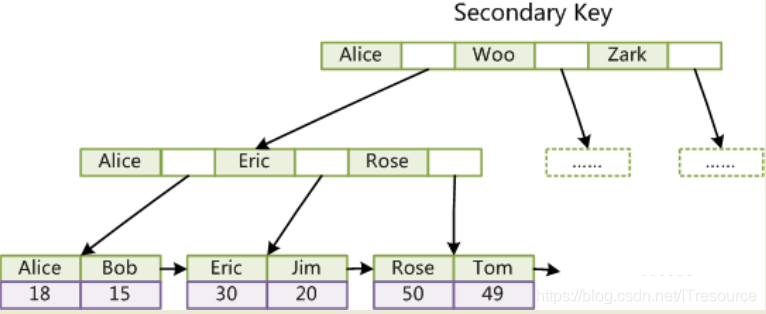
以上为主键索引图,其他辅助索引结构类似,唯一区别是主键索引是唯一的,辅助索引可以重复,辅助索引图如下:
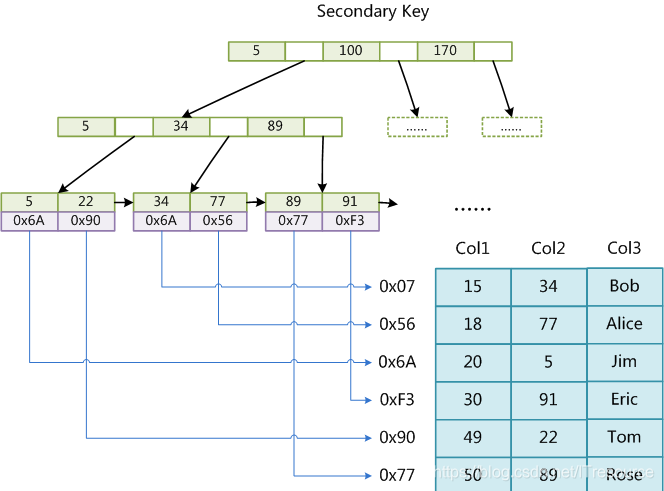
同样也是B+Tree结构,data域保存数据记录的地址。因此,MyISAM中索引检索的算法为首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录。
MyISAM的索引方式也叫做“非聚集”的,之所以这么称呼是为了与InnoDB的聚集索引区分
- innodb 索引实现(聚集)
InnoDB也使用B+Tree作为索引结构,但是与MyISAM体现截然不同
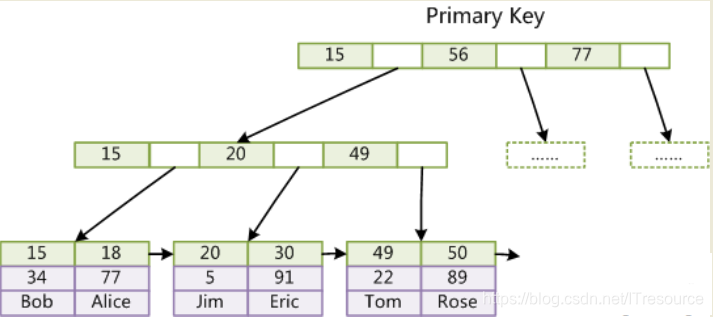
磁盘生成文件 .ibd (表空间文件)
Innodb VS Myisam
第一个重大区别是InnoDB的数据文件本身就是索引文件。从上文知道,MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。
以上可以看出 叶节点包含了完整的数据记录因此这中索引叫做聚集索引
question:
1、 为什么innodb 表必须有主键,并且推荐使用整型的自增主键?
1)answer:因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有)
2)索引结构 key 存在比较,int 型更加方便(相比类似UUID),再者int 型key 比 varchar 型数据占用的空间小,一个节点上存储的索引更多(如果是varchar 型mysql 会底层会转换为ASCII 码进行比较)
2、为什么非主键索引结构叶子结点存储的是主键值?
answer:一致性和节省存储空间
参考文档
