前言、原子性的阐述
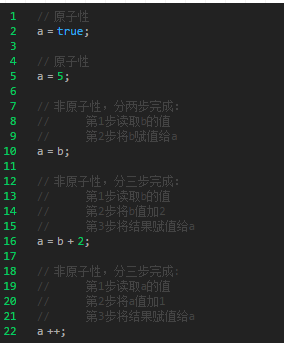
一个或者多个操作在 CPU 执行的过程中不被中断的特性称为原子性。
我理解是一个操作不可再分,即为原子性。而在并发编程的环境中,原子性的含义就是只要该线程开始执行这一系列操作,要么全部执行,要么全部未执行,不允许存在执行一半的情况。
我们试着从数据库事务和并发编程两个方面来进行对比:
1、在数据库中
原子性概念是这样子的:事务被当做一个不可分割的整体,包含在其中的操作要么全部执行,要么全部不执行。且事务在执行过程中如果发生错误,会被回滚到事务开始前的状态,就像这个事务没有执行一样。(也就是说:事务要么被执行,要么一个都没被执行)
2、在并发编程中
原子性概念是这样子的:
-
第一种理解:一个线程或进程在执行过程中,没有发生上下文切换。
-
上下文切换:指 CPU 从一个进程/线程切换到另外一个进程/线程(切换的前提就是获取 CPU 的使用权)。
-
第二种理解:我们把一个线程中的一个或多个操作(不可分割的整体),在 CPU 执行过程中不被中断的特性,称为原子性。(执行过程中,一旦发生中断,就会发生上下文切换)
从上文中对原子性的描述可以看出,并发编程和数据库两者之间的原子性概念有些相似:都是强调,一个原子操作不能被打断!!
而非原子操作用图片表示就是这样子的:
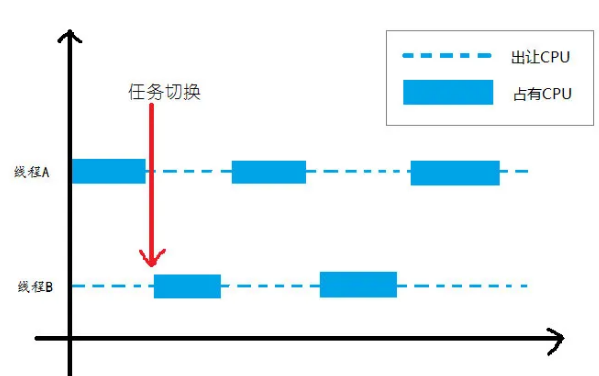
线程 A 在执行一会儿(还没有执行完成),就出 让 CPU 让线程 B 执行。这样的操作在操作系统中有很多,牺牲切换线程的极短耗时,来提高 CPU 的利用率,从而在整体上提高系统性能;操作系统的这种操作就被称为『时间片』切换。
一、出现原子性问题的原因
通过序中描述的原子性的概念,我们总结出了:导致共享变量在线程之间出现原子性问题的原因是上下文切换。
那么接下来,我们通过一个例子来重现原子性问题。
首先定义一个银行账户实体类


@Data @AllArgsConstructor public class BankAccount { private long balance; public long deposit(long amount){ balance = balance + amount; return balance; } }
然后开启多个线程对这个共享的银行账户进行存款操作,每次存款1元:
public class AtomicDemo { public static final int THREAD_COUNT = 1000; static BankAccount depositAccount = new BankAccount(0); public static void main(String[] args) throws Exception { ArrayList<Thread> threads = new ArrayList<>(); for (int i = 0; i < THREAD_COUNT; i++) { Thread thread = new DepositThread(); thread.start(); threads.add(thread); } for (Thread thread : threads) { thread.join(); } System.out.println("Now the balance is " + depositAccount.getBalance() + "元"); } static class DepositThread extends Thread { @Override public void run() { for (int j = 0; j < THREAD_COUNT; j++) { depositAccount.deposit(1); // 每次存款1元 } } } }
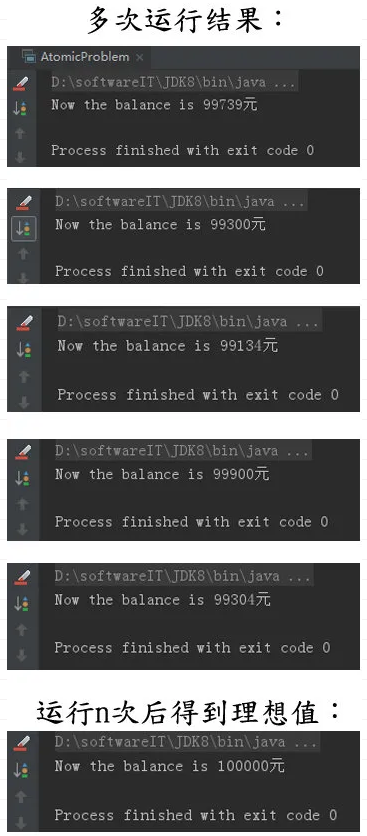
多次运行上面的程序,每次的结果几乎都不一样,偶尔能得到我们期望的结果100*1*1000=100000元,如下是我列举的几次运行结果:
原来罪魁祸首就出自下面的代码:
1balance = balance + amount;
这段代码并不是原子操作,其中的 balance 是一个共享变量。在多线程环境下可能会被打断。就这样原子性问题就赤裸裸的出现了。如图所示:
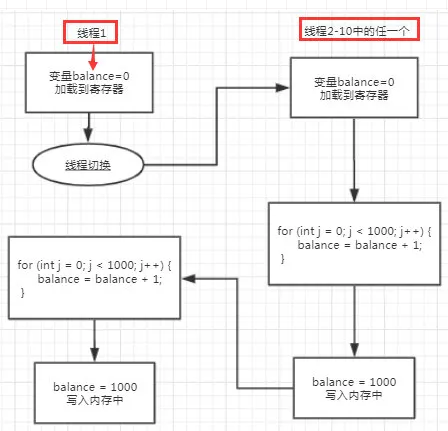
当然,如果 balance 是一个局部变量的话,即使在多线程的情况也不会出现问题(但是这个共享银行账户不适用局部变量啊,否则就不是共享变量了,哈哈,相当于废话),因为局部变量是当前线程私有的。就像图中 for 循环里的 j 变量。
但是呢,即使是共享变量,也绝不允许这样的问题出现,所以我们需要勇敢的面对它,解决它,然后更加深刻的理解并发编程中的原子性问题。
二、解决上下文切换带来的原子性问题
2.1、使用局部变量
局部变量的作用域是方法内部,也就是说当方法执行完,局部变量就被抛弃了,局部变量和方法同生共死。而调用栈的栈帧也是和方法同生共死的,所以局部变量放到调用栈里那儿是相当的合理。而事实上,局部变量的确是放到了调用栈里。
正是因为每个线程都有自己的调用栈,局部变量保存在线程各自的调用栈里面,不会共享,所以自然也就没有并发问题。总结起来就是:没有共享,就不会出错。
但此处如果用局部变量的话,100 个线程各自存 1000 元,最后都是从 0 开始存,不会累计,也就失去了原本想要展现的结果。故此方法不可行。
正如此处使用单线程也能保证原子性一样,因为不适合当前场景,因此并不能解决问题。
2.2、自带原子性保证
在 Java 中,对基本数据类型的变量的读取和赋值操作是原子性操作。
2.3、synchronized
把所有 java 代码都弄成原子性那肯定是不可能的,计算机一个时间内能处理的东西永远是有限的。所以当没法达到原子性时,我们就必须使用一种策略去让这个过程看上去是符合原子性的。因此就有了 synchronized。
synchronized 既可以保证操作的可见性,也可以保证操作结果的原子性。
某个对象实例内,synchronized aMethod(){}可以防止多个线程同时访问这个对象的synchronized 方法。
如果一个对象有多个 synchronized 方法,只要一个线程访问了其中的一个synchronized 方法,其它线程不能同时访问这个对象中任何一个 synchronized 方法。
所以,此处我们只需要将存款的方法设置成 synchronized 的就能保证原子性了。
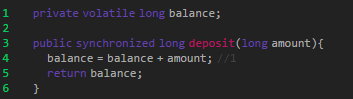
加了 synchronized 后,当一个线程没执行完加了synchronized 的 deposit 这个方法前,其他线程是不能执行这段被 synchronized 修饰的代码的。因此,即使在执行代码行 1 的时候被中断了,其它线程也不能访问变量 balance。
所以从宏观上来看的话,最终的结果是保证了正确性。但中间的操作是否被中断,我们并不知道。如需了解详情,可以看看CAS操作。
PS:对于上面的变量
balance大家可能会有点疑惑:变量balance为什么还要加上volatile关键字?其实这边加上volatile关键字的目的是为了保证balance变量的可见性,保证进入synchronized代码块每次都会去从主内存中读取最新值。
故此,此处的
private volatile long balance;
也可以换成synchronized修饰
private synchronized long balance;
2.4、Lock 锁
public long deposit(long amount) { readWriteLock.writeLock().lock(); try { balance = balance + amount; return balance; } finally { readWriteLock.writeLock().unlock(); } }
Lock 锁保证原子性的原理和 synchronized 类似,这边不进行赘述了。
可能有的读者会好奇,Lock 锁这里有释放锁的操作,而 synchronized 好像没有。其实,Java 编译器会在 synchronized 修饰的方法或代码块前后自动加上加锁lock() 和解锁 unlock(),这样做的好处就是加锁 lock() 和解锁 unlock() 一定是成对出现的,毕竟忘记解锁 unlock() 可是个致命的 Bug(意味着其他线程只能死等下去了)。
各位,这个知识点一定要记住,不然,生产随时爆炸。,哎不提了不提了。
2.5、原子操作类型
如果要用原子类定义属性来保证结果的正确性,则需要对实体类作如下修改:
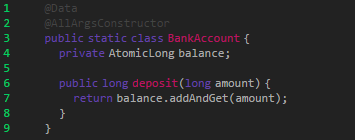
JDK 提供了很多原子操作类来保证操作的原子性。比如最常见的基本类型:
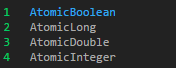
这些原子操作类的底层是使用 CAS 机制的,这个机制保证了整个赋值操作是原子的不能被打断的,从而保证了最终结果的正确性。
和 synchronized 相比,原子操作类型相当于是从微观上保证原子性,而 synchronized 是从宏观上保证原子性。
上面的 2.5 解决方案中,每个小操作都是原子性的,比如 AtomicLong 这些原子类的修改操作,它们本身的 crud 操作是原子的。
那么,仅仅是将每个小操作都符合原子性是不是代表了这整个构成是符合原子性了呢?
显然不是。
它仍然会产生线程安全问题,比如一个方法的整个过程是读取 A- 读取 B- 修改 A- 修改 B- 写入 A- 写入 B;那么,如果在修改 A 完成以后,失去操作原子性,此时线程 B 却开始执行读取 B 操作,此时就会出现原子性问题。
总之不要以为使用了线程安全类,你的所有代码就都是线程安全的!这总归都要从审查你代码的整体原子性出发。就比如下面的例子:
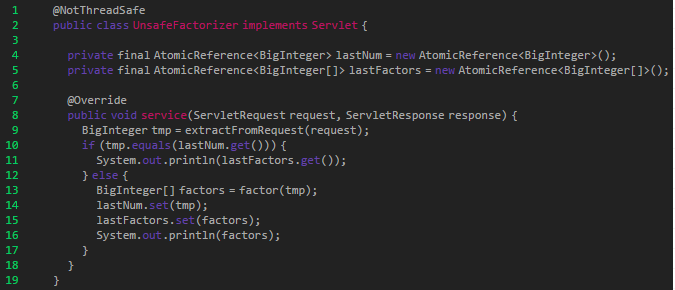
虽然它全部用了原子类来进行操作,但是各个操作之间不是原子性的。也就是说:比如线程 A 在执行 else 语句里的lastNumber.set(tmp)完后,也许其他线程执行了 if语句里的lastFactorys.get()方法,随后线程 A 才继续执行lastFactors.set(factors)方法更新factors!
从这个逻辑过程中,线程安全问题就已经发生了。
它破坏了方法的读取 A- 读取 B- 修改 A- 修改 B- 写入 A- 写入 B这一整体过程,在写入 A 完成以后其他线程去执行了读取 B,就导致了读取到的 B 值不是写入后的 B 值。就这样原子性就出现了。
好了,以上内容就是我对并发中的原子性的一点理解与总结了,通过这两篇文章我们也就大致掌握了并发中常见的可见性、原子性问题以及它们常见的解决方案。
三大恶人,我们已经处理完俩,还剩下个有序性还未解决,这篇文章将在本周内发出,各位同学敬请期待!
最后
贴一段经常看到的原子性实例问题。
问:常听人说,在32位的机器上对long型变量进行加减操作存在并发隐患,到底是不是这样呢?
答:在32位的机器上对long型变量进行加减操作存在并发隐患的说法是正确的。
原因就是:线程切换带来的原子性问题。
非 volatile 类型的 long 和 double 型变量是 8 字节 64 位的,32 位机器读或写这个变量时得把人家咔嚓分成两个 32 位操作,可能一个线程读了某个值的高 32 位,低 32 位已经被另一个线程改了。所以官方推荐最好把 long\double 变量声明为volatile 或是同步加锁 synchronize 以避免并发问题。