作为数据挖掘工程师,以后必不可免要用到并行计算,pyspark是python操作spark的API,本人因此入了坑。
1 pyspark的安装
见我另一篇博客:https://blog.csdn.net/qq_23860475/article/details/90476197
2 spark概述
Spark 允许用户读取、转换和 聚合数据,可以轻松地训练和部署复杂的统计模型。Spark 支持Java、Scala、Python、R和SQL通过相应API进行访问。Spark还提供有几个已经实现并调优过的算法、统计模型和框架,如用于机器学习的MLlib和ML,用于图形处理的GraphX和GraphFrames,用于处理实时流数据的Spark Streaming。
3 SparkSession入口
使用Spark核心API的应用以SparkContext对象作为程序主入口,而Spark SQL应用则以SparkSession对象作为程序主入口,在Spark2.0发布之前,Spark SQL应用使用的专用主入口是SQLContext和HiveContext。SparkSession把它们封装为一个简洁而统一的入口。
SparkSession和sparkContext初始化:
from pyspark.sql import SparkSession
spark=SparkSession.builder.master("local").appName("test").getOrCreate()
sc=spark.sparkContext4 RDD入门
RDD(Resilient Distributed Dataset)即弹性分布式数据集。RDD是Spark编程中最基本的数据对象,无论是最初加载的数据集,还是任何中间结果的数据集,或是最终的结果数据集,都是RDD。大多数Spark应用从外部加载数据到RDD,然后对已有的RDD进行操作来创建新的RDD,这些操作就是转化操作(返回指向新RDD的指针)。这个过程不断重复,直到需要进行输出操作为止,这种操作则是行动操作(在运行计算后向驱动程序返回值)。
RDD本质上是对象分布在各节点上的集合,用来表示Spark程序中的数据。在pyspark中,RDD是由分布在各节点上python对象组成的,这里的对象可以是列表、元组、字典等。如果使用Scala或Java的API,RDD则分别有Scala或Java对象组成。
对弹性分布式数据集这一术语进行拆解描述:
弹性:RDD是由弹性的,意思是说如果Spark中一个执行任务的节点丢失了,数据集依然可以被重建起来。这是因为Spark有每个RDD的谱系,也就是从头构建RDD的步骤。
分布式:RDD是分布式的,RDD中的数据被分到至少一个分区中,在集群上跨工作节点分布式地作为对象集合保存在内存中。
数据集:RDD是由记录组成的数据集。记录是数据集中可以唯一区分的数据的集合。一条记录可以是由几个字段组成的,这类似于关系型数据库里面表中的行,或是文件中的一行文本,或其他的一些格式中类似的结构。RDD的各分区包含不同的一部分记录,可以独立进行操作。
常见的RDD基础操作属性函数如下表所示:
| 操作类型 | 函数名 | 作用 |
| 转化操作 | map() | 参数是函数,函数应用于RDD每一个元素,返回值是新的RDD |
| flatMap() | 参数是函数,函数应用于RDD每一个元素,将元素数据进行拆分,变成迭代器,返回值是新的RDD | |
| filter() | 参数是函数,函数会过滤掉不符合条件的元素,返回值是新的RDD | |
| distinct() | 没有参数,将RDD里的元素进行去重操作 | |
| union() | 参数是RDD,生成包含两个RDD所有元素的新RDD | |
| intersection() | 参数是RDD,求出两个RDD的共同元素 | |
| subtract() | 参数是RDD,将原RDD里和参数RDD里相同的元素去掉 | |
| cartesian() | 参数是RDD,求两个RDD的笛卡儿积 | |
| 行动操作 | collect() | 返回RDD所有元素 |
| count() | RDD里元素个数 | |
| countByValue() | 各元素在RDD中出现次数 | |
| reduce() | 并行整合所有RDD数据,例如求和操作 | |
| fold(0)(func) | 和reduce功能一样,不过fold带有初始值 | |
| aggregate(0)(seqOp,combop) | 和reduce功能一样,但是返回的RDD数据类型和原RDD不一样 | |
| foreach(func) | 对RDD每个元素都是使用特定函数 |
4.1 创建RDD
文件系统协议与URL结构
| 文件系统 | URL结构 |
| 本地文件系统 | file:///path |
| HDFS* | hdfs:///hdfs_path |
| Amazon S3* | s3://bucket/path |
| OpenStack Swift | swift://container.PROVIDER/path |
4.1.1 通过读取文本文件
from pyspark.sql import SparkSession
spark=SparkSession.builder.master("local").appName("test").getOrCreate()
sc=spark.sparkContext
#读取整个目录下的内容
logs=sc.textFile("hdfs:///demo/data/website-Logs/")
#读取单个文件
logs=sc.textFile("hdfs:///demo/data/website-Logs/IB_websitelogLog_001.txt")
#使用通配符读取文件
logs=sc.textFile("hdfs:///demo/data/website-Logs/*_001.txt"")
#把整个目录的内容加载为键值对
logs=sc.wholeTextFiles("hdfs:///demo/data/website-Logs/")
spark.stop()注意:使用textFile()方法读入一个目录下的所有文件时,每个文件的每一行都成为了一条单独的记录,而该行数据属于哪个文件的信息没有保留。用wholeTextFile()方法来读取包含多文件的整个目录,每个文件会作为一条记录,其中文件名是记录的键,而文件的内容是记录的值。
4.1.2 通过parallelize和range
from pyspark.sql import SparkSession
spark=SparkSession.builder.master("local").appName("test").getOrCreate()
sc=spark.sparkContext
#通过parallelize
rdd= sc.parallelize([1,2,3,4,5,6,7])
#通过range
rdd=sc.range(1,8,1,2)#sc.range(start,end=None,step=1,numslices=None),numslices指定所需分区数量
spark.stop()4.2 操作RDD
4.2.1 collect()
将RDD里的元素以列表形式返回
from pyspark.sql import SparkSession
spark=SparkSession.builder.master("local").appName("test").getOrCreate()
sc=spark.sparkContext
rdd= sc.parallelize([1,2,3,4,5,6,7])
print(rdd.collect())
spark.stop()
运行结果:
![]()
4.2.2 map()
map()类似于Python中的map,针对RDD对应的列表的每一个元素,进行map()函数里面的lambda函数(这个函数是map函数的一个参数)对应的操作,返回的仍然是一个RDD对象。
from pyspark.sql import SparkSession
spark=SparkSession.builder.master("local").appName("test").getOrCreate()
sc=spark.sparkContext
rdd1= sc.parallelize([1,2,3,4,5,6,7])
rdd2=rdd1.map(lambda x:x**2)
print(rdd2.collect())
spark.stop()运行结果:
![]()
4.2.3 reduce()
reduce()是针对RDD对应的列表中的元素,递归地选择第一个和第二个元素进行操作,操作的结果作为一个元素用来替换这两个元素,注意,reduce返回的是一个Python可以识别的对象,非RDD对象。
from pyspark.sql import SparkSession
spark=SparkSession.builder.master("local").appName("test").getOrCreate()
sc=spark.sparkContext
rdd1= sc.parallelize([1,2,3,4,5,6,7])
rdd2=rdd1.reduce(lambda x,y:x+y)
print(rdd2)
spark.stop()运行结果:
![]()
4.2.4 reduceByKey()和reduceByKeyLocally()
reduce()最终只返回一个值,reduceByKey()和reduceByKeyLocally()均是将Key相同的元素合并。
区别在于,reduce()和reduceByKeyLocally()函数均是将RDD转化为非RDD对象,而reduceByKey()将RDD对象转化为另一个RDD对象,需要collect()函数才能输出。
from pyspark.sql import SparkSession
spark=SparkSession.builder.master("local").appName("test").getOrCreate()
sc=spark.sparkContext
rdd1= sc.parallelize([[1,10],[1,1],[2,100],[2,1]])
rdd2=rdd1.reduceByKey(lambda x,y:x+y)
rdd3=rdd1.reduceByKeyLocally(lambda x,y:x+y)
print(rdd2.collect())
print(rdd3)
spark.stop()运行结果:

4.2.5 flatMap()
from pyspark.sql import SparkSession
spark=SparkSession.builder.master("local").appName("test").getOrCreate()
sc=spark.sparkContext
rdd1= sc.parallelize([1,2,3,4,5,6,7])
rdd2=rdd1.flatMap(lambda x:(x,x**2))
print(rdd2.collect())
spark.stop()运行结果:
![]()
可以看出map和flatMap的区别,前者是用单个元素替换原来的单个元素,后者直接用多个元素替换单个元素。
4.2.6 filter()
filter()用于删除/过滤,即删除不满足条件的元素,这个条件一lambda函数的形式作为参数传入filter()函数中,返回rdd对象。
from pyspark.sql import SparkSession
spark=SparkSession.builder.master("local").appName("test").getOrCreate()
sc=spark.sparkContext
rdd1= sc.parallelize([1,2,3,4,5,6,7])
rdd2=rdd1.filter(lambda x:x%2==0)#过滤掉奇数,保留偶数
print(rdd2.collect())
spark.stop()运行结果:

4.2.7 distinct()
distinct()用于去重,没有参数,返回RDD。
from pyspark.sql import SparkSession
spark=SparkSession.builder.master("local").appName("test").getOrCreate()
sc=spark.sparkContext
rdd1= sc.parallelize([1,1,3,3,4,4,5])
rdd2=rdd1.distinct()
print(rdd2.collect())
spark.stop()
运行结果:
![]()
4.2.8 join()
用于匹配元素,类似sql中的leftjoin。
from pyspark.sql import SparkSession
spark=SparkSession.builder.master("local").appName("test").getOrCreate()
sc=spark.sparkContext
rdd1= sc.parallelize([[1,10],[1,1],[2,100],[2,1]])
rdd2= sc.parallelize([[1,11],[1,12],[2,101],[2,102]])
rdd3=rdd1.join(rdd2)
print(rdd3.collect())
spark.stop()运行结果:
![]()
4.2.9 union()
union()求两个RDD对象的所有元素的并,不去掉重复元素。
from pyspark.sql import SparkSession
spark=SparkSession.builder.master("local").appName("test").getOrCreate()
sc=spark.sparkContext
rdd1= sc.parallelize([1,2,3,4])
rdd2= sc.parallelize([3,4,5,6])
rdd3=rdd1.union(rdd2)
print(rdd3.collect())
spark.stop()运行结果:
![]()
4.2.10 intersection()
intersection()求交集
from pyspark.sql import SparkSession
spark=SparkSession.builder.master("local").appName("test").getOrCreate()
sc=spark.sparkContext
rdd1= sc.parallelize([1,2,3,4])
rdd2= sc.parallelize([3,4,5,6])
rdd3=rdd1.intersection(rdd2)
print(rdd3.collect())
spark.stop()
运行结果:
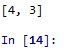
4.2.11 sortByKey()
sortByKey()按键值进行排序
from pyspark.sql import SparkSession
spark=SparkSession.builder.master("local").appName("test").getOrCreate()
sc=spark.sparkContext
rdd1= sc.parallelize([('B',2),('A',1),('C',3)])
rdd2= rdd1.sortByKey()
print(rdd2.collect())
spark.stop()运行结果:
![]()
4.2.12 sortBy()
根据函数进行排序。
from pyspark.sql import SparkSession
spark=SparkSession.builder.master("local").appName("test").getOrCreate()
sc=spark.sparkContext
rdd1= sc.parallelize(['mouse','cat','dog'])
def f(x):return x[0]
rdd2= rdd1.sortBy(f)
print(rdd2.collect())
spark.stop()
运行结果:
![]()
4.2.13 glom()
glom() 显示分区结果。
from pyspark.sql import SparkSession
spark=SparkSession.builder.master("local").appName("test").getOrCreate()
sc=spark.sparkContext
rdd1= sc.parallelize([1,2,3,4,5,6,7],3)
rdd2= rdd1.glom()
print(rdd2.collect())
spark.stop()
运行结果:

4.2.14 cartesian()
cartesian()组合元素。
from pyspark.sql import SparkSession
spark=SparkSession.builder.master("local").appName("test").getOrCreate()
sc=spark.sparkContext
rdd1= sc.parallelize(['A','B'])
rdd2= sc.parallelize(['C','D'])
rdd3= rdd1.cartesian(rdd2)
print(rdd3.collect())
spark.stop()运行结果:
![]()
4.2.15 groupBy()
groupBy()对元素按给定条件(函数)进行分组。
from pyspark.sql import SparkSession
spark=SparkSession.builder.master("local").appName("test").getOrCreate()
sc=spark.sparkContext
rdd1= sc.parallelize([1,2,3,4,5,6,7])
rdd2= rdd1.groupBy(lambda x:x%2).collect()
result=[(x,sorted(y)) for x,y in rdd2]
print(result)
spark.stop()运行结果:
![]()
4.2.16 foreach()
foreach()对应所有元素应用给定函数,不返回值
from pyspark.sql import SparkSession
spark=SparkSession.builder.master("local").appName("test").getOrCreate()
sc=spark.sparkContext
rdd1= sc.parallelize([1,2,3,4,5,6,7])
def f(x):return print(x)
rdd1.foreach(f)
spark.stop()4.2.17 foreachPartition()
foreachPartition()对RDD每个分区应用给定函数
from pyspark.sql import SparkSession
spark=SparkSession.builder.master("local").appName("test").getOrCreate()
sc=spark.sparkContext
rdd1= sc.parallelize([1,2,3,4,5,6,7])
def f(iterator):
for x in iterator:
print(x)
rdd1.foreachPartition(f)
spark.stop()5 DataFrame入门
DataFrame是Spark RDD的抽象。然而,DataFrame有别于原生RDD,区别在于DataFrame维护表结构,并且对许多常见的SQL函数和关系型操作符提供了原生支持。而DataFrame和RDD的相似之处包括它们都是作为DAG求值,都使用惰性求值,并且都提供了谱系和容错性。
5.1 创建DataFrame
5.1.1 通过RDD
from pyspark.sql import SparkSession
spark=SparkSession.builder.master("local").appName("test").getOrCreate()
sc=spark.sparkContext
rdd= sc.parallelize([('John',30),('Mary',78)])
dataframe=spark.createDataFrame(rdd,['name','age'])
print(dataframe.collect())
spark.stop()运行结果:
![]()
5.1.2 通过pyhton对象
from pyspark.sql import SparkSession
spark=SparkSession.builder.master("local").appName("test").getOrCreate()
data=[('John',30),('Mary',78)]
dataframe=spark.createDataFrame(data,['name','age'])
print(dataframe.collect())
spark.stop()运行结果:
![]()
5.1.3 通过读取JSON文件
from pyspark.sql import SparkSession
spark=SparkSession.builder.master("local").appName("test").getOrCreate()
data=spark.read.json(".../data.json")
spark.stop()5.1.4 通过读取csv文件
from pyspark.sql import SparkSession
spark=SparkSession.builder.master("local").appName("test").getOrCreate()
data=spark.read.csv(path="file:///.../data.csv",schema=None,sep=",",header=True)
spark.stop()5.1.5 通过读取文本文件
from pyspark.sql import SparkSession
spark=SparkSession.builder.master("local").appName("test").getOrCreate()
#读取整个目录下的内容
df=spark.read.text("hdfs:///demo/data/website-Logs/")
#读取单个文件
df=spark.read.text("hdfs:///demo/data/website-Logs/IB_websitelogLog_001.txt")
spark.stop()5.2 操作DataFrame
5.2.1 columns()
获取字段名。
from pyspark.sql import SparkSession
spark=SparkSession.builder.master("local").appName("test").getOrCreate()
data=[('John',30),('Mary',78),('Jones',20),('Mike',10)]
dataframe=spark.createDataFrame(data,['name','age'])
print(dataframe.columns)
spark.stop()运行结果:
![]()
5.2.2 dtypes()
返回字段名跟数据类型。
from pyspark.sql import SparkSession
spark=SparkSession.builder.master("local").appName("test").getOrCreate()
data=[('John',30),('Mary',78),('Jones',20),('Mike',10)]
dataframe=spark.createDataFrame(data,['name','age'])
print(dataframe.dtypes)
spark.stop()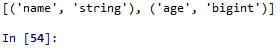
5.2.3 take()
take(n)返回前n行数据。
from pyspark.sql import SparkSession
spark=SparkSession.builder.master("local").appName("test").getOrCreate()
data=[('John',30),('Mary',78),('Jones',20),('Mike',10)]
dataframe=spark.createDataFrame(data,['name','age'])
dataSub=dataframe.take(2)
print(dataSub)
spark.stop()运行结果:
![]()
5.2.4 show()
show(n)将前n行打印到控制台上,与collect()和take(n)不同,show()并不把结果返回到变量。show()命令输出格式比较好看,它会以表格形式呈现结果,并且包含表头,可读性很高。
from pyspark.sql import SparkSession
spark=SparkSession.builder.master("local").appName("test").getOrCreate()
data=[('John',30),('Mary',78),('Jones',20),('Mike',10)]
dataframe=spark.createDataFrame(data,['name','age'])
dataSub=dataframe.show(2)
spark.stop()运行结果:

5.2.5 select()
from pyspark.sql import SparkSession
spark=SparkSession.builder.master("local").appName("test").getOrCreate()
data=[('John',30),('Mary',78),('Jones',20),('Mike',10)]
dataframe=spark.createDataFrame(data,['name','age'])
newData=dataframe.select("name","age").filter("age>20")
newData.show()
spark.stop()运行结果:

5.2.6 drop()
删除列
from pyspark.sql import SparkSession
spark=SparkSession.builder.master("local").appName("test").getOrCreate()
data=[('John',30),('Mary',78),('Jones',20),('Mike',10)]
dataframe=spark.createDataFrame(data,['name','age'])
newData=dataframe.drop('name')
newData.show()
spark.stop()运行结果:
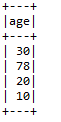
5.2.7 distinct()
删除重复行,当一行数据的所有列的值都与另一行相同,我们就把它看作重复的行。
from pyspark.sql import SparkSession
spark=SparkSession.builder.master("local").appName("test").getOrCreate()
data=[('John',30),('Mary',78),('Jones',20),('Mike',10),('Mike',10)]
dataframe=spark.createDataFrame(data,['name','age'])
newData=dataframe.distinct()
newData.show()
spark.stop()运行结果:
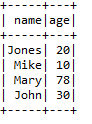
5.2.8 registerTempTable()
registerTempTable()创建临时表
from pyspark.sql import SparkSession
spark=SparkSession.builder.master("local").appName("test").getOrCreate()
data=[('John',30),('Mary',78),('Jones',20),('Mike',10)]
dataframe=spark.createDataFrame(data,['name','age'])
dataframe.registerTempTable('stuInfo')#创建并登陆临时表
spark.sql("select * from stuInfo where age>20").show()#使用sql语句查询
spark.stop()运行结果:

5.2.9 join()
join()将当前DataFrame与其他DataFrame做连接操作,on参数指定一个列、一组列、或者一个表达式,用于连接操作的求值。how参数指定要执行的连接类型。有效的值包括inner(默认值)、outer、left_outer、right_outer和leftsemi。
from pyspark.sql import SparkSession
spark=SparkSession.builder.master("local").appName("test").getOrCreate()
data1=[('John',30),('Mary',78),('Jones',20),('Mike',10)]
data2=[('John',1),('Mary',0),('Jones',0),('Mike',1)]
df1=spark.createDataFrame(data1,['name','age'])
df2=spark.createDataFrame(data2,['name','sex'])
df3=df1.join(df2,on='name',how='left_outer')#按name字段匹配
df3.show()
spark.stop()运行结果:
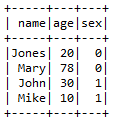
5.2.10 orderBy()
orderBy()根据指定列进行排序。
from pyspark.sql import SparkSession
spark=SparkSession.builder.master("local").appName("test").getOrCreate()
data=[('John',30),('Mary',78),('Jones',20),('Mike',10)]
df1=spark.createDataFrame(data,['name','age'])
df2=df1.orderBy(['age'],ascending=True)
df2.show()
spark.stop()运行结果:
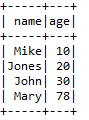
5.2.11 groupBy()
groupBy() 按照指定列进行分组。
from pyspark.sql import SparkSession
spark=SparkSession.builder.master("local").appName("test").getOrCreate()
data=[('John',30),('John',78),('Mike',20),('Mike',10)]
df1=spark.createDataFrame(data,['name','age'])
df2=df1.groupBy(['name']).sum('age')
df2.show()
spark.stop()运行结果:

