- 介绍
fork()系统调用用于创建一个新进程,称为子进程,他与进程(成为系统调用fork的进程)同时运行,此进程称为父进程。创建新的子进程后,两个进程将执行fork()系统调用之后的下一条指令。子进程使用相同得pc(程序计数器),相同的CPU寄存器,在父进程中使用的相同打开文件。其返回值如下:
1. 负值:创建子进程失败。
2. 零:返回到新创建的子进程。
3. 正值:返回父进程,该值包含新创建的子进程的进乘ID。
- 包含其头文件
#include<unistd.h>
#include<sys/types.h>
Linux下有两个系统调用的创建子进程的函数分别是fork()和vfork(),后面会介绍两个函数的区别和用法。fork()函数被称为分叉函数,一般的函数一次调用只会有一次返回,fork()函数会有两次返回,上面提到返回给父进程的是子进程的PID(进程号),返回给子进程的是0,返回负值则说明创建失败,可能有如下两个原因:
1. 系统中有太多进程。
2. 当前用户ID的进程数超过系统限制。
通常我们也通过返回值判定是哪个进程在运行。
在Linux内核启动过程中最后会创建一个init进程(初始化进程),执行程序/sbin/init,该进程是Linux系统运行的第一个进程因此其进程号为1,它不会被“杀死”,接下来他会创建其他子进程启动相应的系统服务,每个服务可以创建不同子进程执行不同程序,通过ps aux命令可查看此时系统维护正在运行的进程的进程表:
panghu@Ubuntu-14:~/socket$ ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.2 33920 4468 ? Ss 2月16 0:04 /sbin/init //1号进程 init进程
root 2 0.0 0.0 0 0 ? S 2月16 0:00 [kthreadd]
root 3 0.0 0.0 0 0 ? S 2月16 0:01 [ksoftirqd/0]
root 5 0.0 0.0 0 0 ? S< 2月16 0:00 [kworker/0:0H]
root 7 0.0 0.0 0 0 ? S 2月16 1:24 [rcu_sched]
root 8 0.0 0.0 0 0 ? S 2月16 0:00 [rcu_bh]
root 9 0.0 0.0 0 0 ? S 2月16 0:00 [migration/0]
root 10 0.0 0.0 0 0 ? S 2月16 0:05 [watchdog/0]
root 11 0.0 0.0 0 0 ? S 2月16 0:00 [kdevtmpfs]
root 12 0.0 0.0 0 0 ? S< 2月16 0:00 [netns]
root 13 0.0 0.0 0 0 ? S< 2月16 0:00 [perf]
··········
通过对相应进程的PID(进程号)操作,可对其进行开启、关闭等管理。
通过其名字可知,每个父进程都有无数个子进程,一个子进程只能有一个父进程,进程通过getpid()函数可获取自己的PID(进程号),通过getppid()获取其父进程的PID(进程号),通过下列了解下fork()创建进程的过程:
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <errno.h>
int main(int argc, char **argv)
{
pid_t pid;
printf("Parent process PID[%d] start running...\n", getpid() );
pid = fork();
if(pid < 0)
{
printf("fork() create child process failure: %s\n", strerror(errno));
return -1;
}
else if( pid == 0 )
{
printf("child process Pid[%d] start running ···,its parent PID is [%d]\n", getpid(), getppid());
return 0;
}
else if( pid > 0 )
{
sleep(1); \\ 这里让父进程sleep 1s是因为他们哪个父进程和子进程哪个先执行不一定如果父进程先退出了,子进程会变成孤儿进程被init进程收养,其`getppid()`返回值会为1
printf("Parent process Pid[%d] start running ···,its child PID is [%d]\n", getpid(), pid);
return 0;
}
}
- 父进程和子进程是并行运行的,先运行哪个是不确定的,在小红帽系统中,先运行的是子进程,在Ubuntu系统中,父进程先运行。确保让父进程先执行,则需要在代码中通过进程间通信机制完成,例子中用sleep(1)并不可确保解决让子进程先退出。
上面的程序输出如下:
panghu@Ubuntu-14:~$ ./fork
Parent process Pid[13545] start running ···
child process Pid[13546] start running ···,its parent PID is [13545]
Parent process Pid[13545] start running ···,its child PID is [13546]
- 对于子进程来说继承了父进程的哪些资源?
子进程继承父进程:
用户号UIDs和用户组号GIDs
环境Environment
堆栈
共享资源
打开文件描述符
执行关闭(Close-on-exec)标志
信号(Signal)控制设定
进程组号
当前工作目录
根目录
文件方式创建屏蔽字
资源限制
控制终端
子进程独有:
进程号PID
不同的父进程号
自己的文件描述符和目录流的拷贝
子进程不继承父进程的进程正文(text),数据和其他锁定内容(memory locks)
不继承异步输入和输出
经过fork()系统调用后创建的子进程是父进程的一个副本,意味着创建成功后,父进程和子进程会拥有相同内容的文本段,数据段,堆栈。不过在子进程没有进行写操作之前,父进程只会复制自己的PCB块给子进程,当子进程进行写操作时,会产生中断为子进程分配内存空间。
通过上面的例子不难看出fork()父子进程分别执行自己的代码块:
通过下面例子深入了解父进程创建子进程的过程:
#include <stdio.h>
#include <errno.h>
#include <unistd.h>
#include <string.h>
int g_var = 6;
char g_buf[]="A string write to stdout.\n";
int main (int argc, char **argv)
{
int var = 66;
pid_t pid;
if( write(STDOUT_FILENO, g_buf, sizeof(g_buf)-1) < 0)
{
printf("Write string to stdout error: %s\n", strerror(errno));
return -1;
}
printf("Befor fork\n");
pid = fork();
if( pid < 0)
{
printf("fork() error: %s\n", strerror(errno));
return -2;
}
else if( 0 == pid)
{
printf("Child process PID[%d] running...\n", getpid());
g_var ++;
var ++;
}
else
{
printf("Parent process PID[%d] waiting...\n", getpid());
sleep(1);
}
printf("PID=%ld, g_var=%d, var=%d\n", (long) getpid(), g_var, var);
return 0;
}
运行结果如下
panghu@Ubuntu-14:~$ ./for
A string write to stdout.
Befor fork
Parent process PID[13584] waiting...
Child process PID[13585] running...
PID=13585, g_var=7, var=67
PID=13584, g_var=6, var=66
- 分析我们可知在
fork()之前的输出只打印了一次,而在子进程中对局部变量g_var和var进行了操作,丛输出来看并没有影响到父进程的数据,同样父进程中的sleep(1)是为了延时父进程退出的时间,让子进程先退出。 - 例子中的
writr()和printf()虽然都为输出函数,但我们执行将其输出重定向到文件中就会发现问题:
panghu@Ubuntu-14:~$ ./for > text.log
panghu@Ubuntu-14:~$ cat text.log
A string write to stdout.
Befor fork
Child process PID[13606] running...
PID=13606, g_var=7, var=67
Befor fork
Parent process PID[13605] waiting...
PID=13605, g_var=6, var=66
我们会发现write()所输出的内容只打印了一次而printf()输出了两次,那是因为write()是系统调用,会直接输出到标准输出里,而printf()是库函数,其标准输出是终端时默认是行缓冲,重定向后该函数为全缓冲,printf()的内容打印在了缓冲区里,在fork()后父进程将自己的缓冲区拷贝给了子进程一份,因为是全缓冲所以只会在函数return后刷新缓冲区才会有输出。
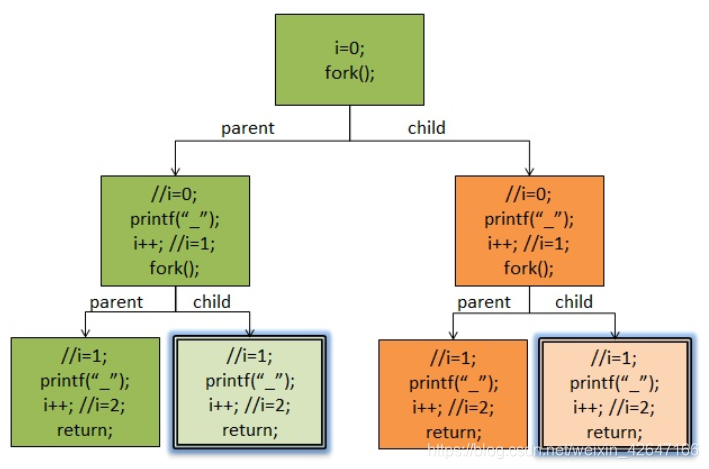
例如有这样一道c语言的笔试题:
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main(void)
{
int i;
for(i=0; i<2; i++){
fork();
printf("-");
}
return 0;
}
问会输出多少“-”。如果这道题的printf有\n刷新缓冲区的话那么答案就是六个,上面所提到的父进程会把自己的缓冲区的内容拷贝给子进程,因此这道题的答案使8个。
借用其他博主的图来更好地理解一下:
相同颜色的是同一个进程,我们就可以很清楚的知道,哪个子进程复制了父进程标准输出缓中区里的的内容,而导致了多次输出了。(如下图所示,就是我阴影并双边框了那两个子进程)

因为fork()在使用时会搭配exec系列函数让子进程去执行另外一个程序,esec系列函数就会抛弃父进程的文本段数据段和代码段,上面也有提到写时拷贝技术(CopyOnWrite),父子进程共享内存空间,内核将父子进程的权限改为只读,当其需要修改数据时才会分配内存空间使其修改。
vfork()函数与fork()函数用法和原型一样,只不过考虑到fork()函数会让子进程执行exec()系列函数,可能会导致数据域的修改,会影响到父进程运行异常,因此vfork()函数可以保证让子进程先运行后在运行父进程,保证程序正常结束。
继承部分参考博客:https://blog.csdn.net/qq_33573235/article/details/77645967
