ArrayList 继承体系结构分析

从源码中可以画出以下 ArrayList 的继承体系结构图,便于分析。
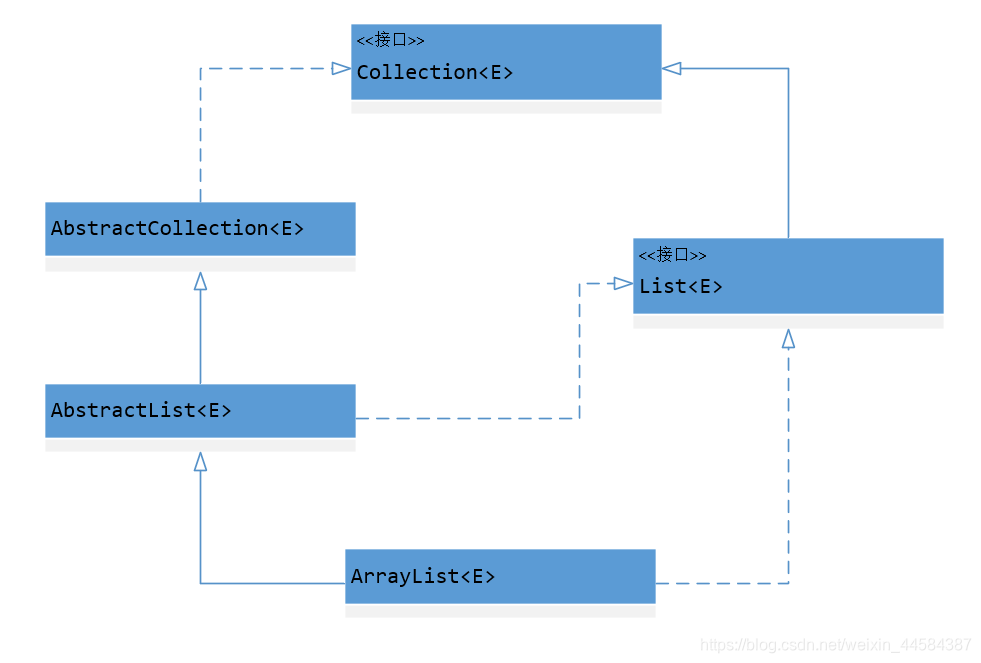
从这张结构图中可以看到抽象类 AbstractList<E> 实现了 List<E> 接口,而它的子类 ArrayList<E> 又实现了一遍,这样做难道不是多此一举吗 ??思考一下它为什么要这样设计 ??
这样设计是为了在使用动态代理时,被代理的类必须直接实现接口,不能由父类间接实现,否则在方法返回一个对象时无法向下转型为该接口的类型。
关于动态代理的具体介绍,可以参考:设计模式之代理模式 — 静态代理与动态代理
接口是对行为的规范,在 Collection 接口中规定了一些集合中通用的方法,如:add()、addAll()、remove()、removeAll()、size()、isEmpty()、containsAll() 等
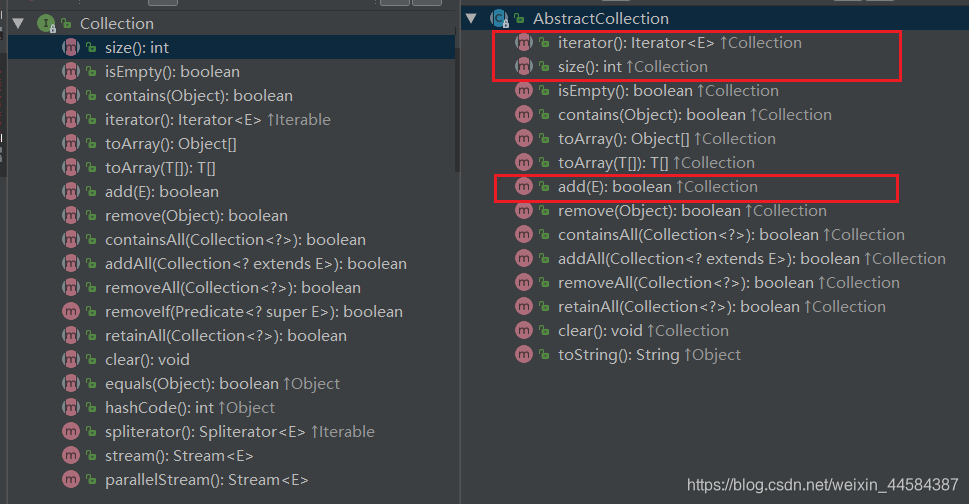
AbstractCollection<E> 部分源码
public abstract Iterator<E> iterator();
public abstract int size();
public boolean add(E e) {
throw new UnsupportedOperationException();
}
public boolean isEmpty() {
return size() == 0;
}
public boolean contains(Object o) {
Iterator<E> it = iterator();
if (o==null) {
while (it.hasNext())
if (it.next()==null)
return true;
} else {
while (it.hasNext())
if (o.equals(it.next()))
return true;
}
return false;
}
在抽象类 AbstractCollection<E> 中,实现了 Collection<E> 接口的大部分方法,部分方法如:iterator()、size() 方法没有实现,而是把它们交给子类去实现;add() 方法直接抛出异常,需要子类重写;同时在其它方法的实现中大都使用了这两个没有实现的方法,思考这里用到了什么设计模式???
这里用到了设计模式中的模版方法模式,在抽象类 AbstractCollection<E> 中那些已经实现的方法相当于模版方法,而那些没有实现的方法如:size()、iterator() 是抽象方法需要子类实现,add() 方法相当于钩子方法,需要子类重写。
AbstractList<E> 和 AbstractCollection<E> 一样,都是使用了模板方法,具体就不在这里赘述了。
下面正式分析 ArrayList<E> 源码
ArrayList<E> 源码分析
构造器和 add(E e) 方法
ArrayList 有 3 个构造器,一般以下两个用的比较多
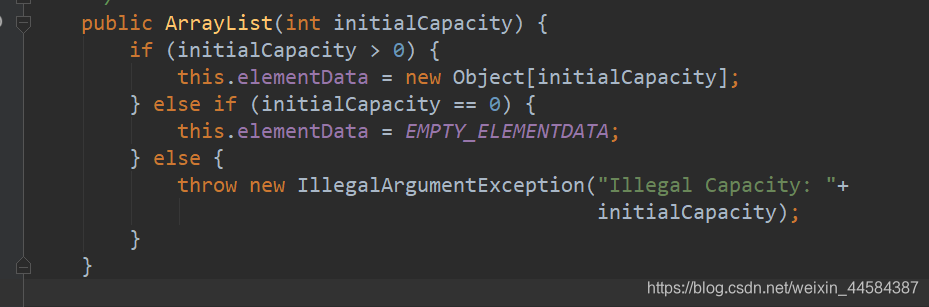
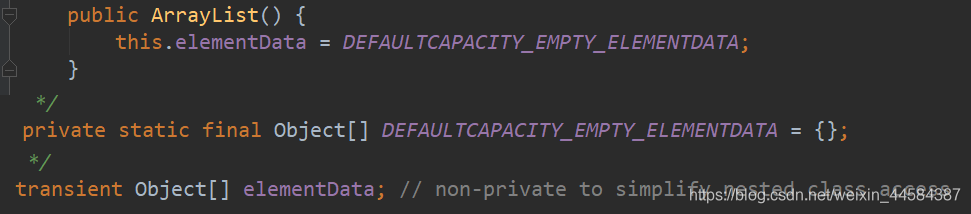
ArrayList 底层使用 Object[ ] 数组存储数据,当使用无参构造器时,默认是空数组。
当第一次调用 add() 方法时,size 是成员变量,记录数组中元素个数,初始为 0;这里将 size+1 然后调用 ensureCapacityInternal() 方法。并将 1 传进去。
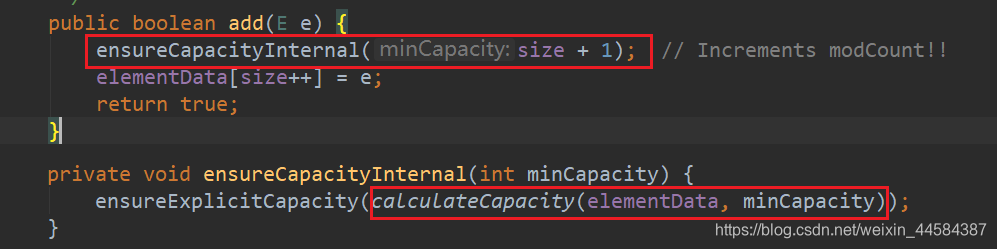
calculateCapacity() 方法作用:当容器数组为默认的空数组时,返回默认容量大小与 minCapacity 的最大值,否则直接返回 minCapacity。此时返回默认容量大小 10

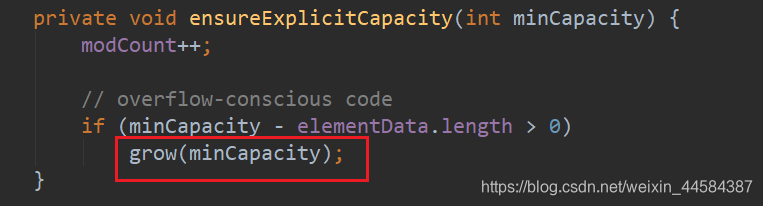
然后调用 ensureExplicitCapacity() 方法,并将 10 作为参数传进去,此时当前数组长度为 0,所以调用 grow() 方法,并将 10 传进去
grow() 方法是数组扩容的核心方法!!!
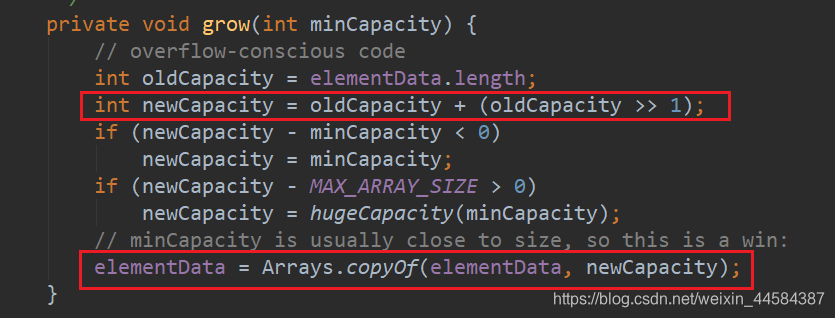

从 grow() 方法中我们可以得知:
-
newCapacity = oldCapacity + oldCapacity / 2,数组增长因子为 0.5
-
当 minCapacity 值在 oldCapacity 与 newCapacity 之间时,数组的最终扩容大小为 newCapacity;
-
当 minCapacity 值在 newCapacity 与 MAX_ARRAY_SIZE 之间时,数组的最终扩容大小为 minCapacity;
-
当 minCapacity 值大于 MAX_ARRAY_SIZE 时,数组最终大小为 Integer.MAX_VALUE
因此,当使用无参构造器创建 ArrayList 对象时,数组容量默认大小为 10
总结:
-
在创建 ArrayList 对象时,最好使用带参构造器指定初始化容量,避免在 add() 操作时消耗 CPU,因为在数组进行复制时消耗是非常巨大的
-
数组默认大小容量为 10
-
数组的增长因子为 0.5
remove(int index) 方法
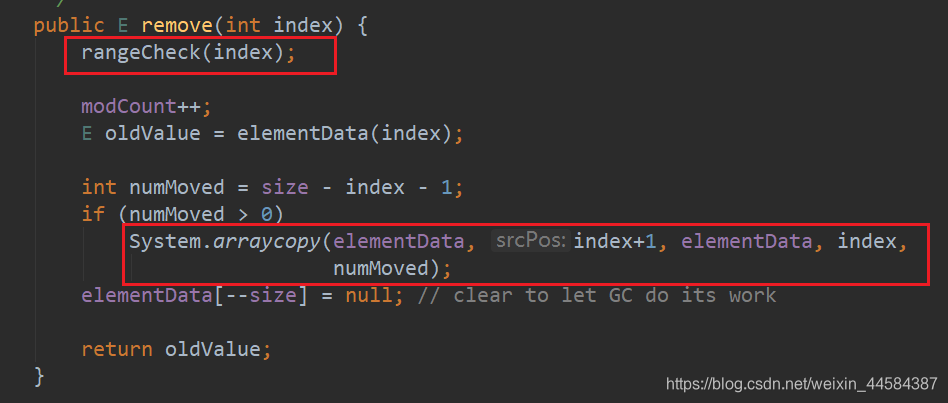

在 remove() 方法中,我们主要关注两个方法,一是 rangeCheck() 检查下标越界问题,这没啥好说的,还有一个是 System.arraycopy() 调用的是本地方法。
当移除的是数组中最后一个元素是,直接将最后一个元素设为 null,否则进行数组拷贝,将数组中的元素往前挪一位
add(int index, E element)
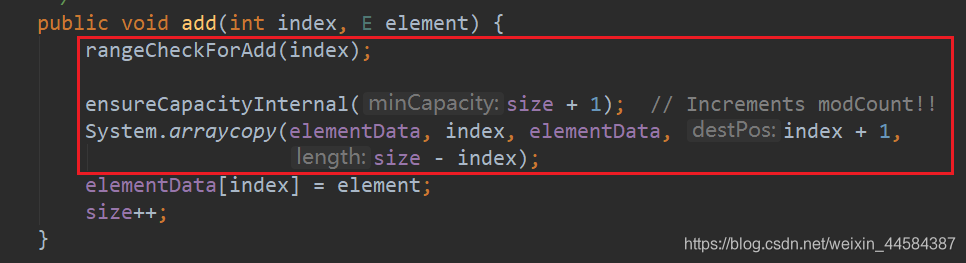
和前面类似,这里就不重复赘述了!!!
批量删除 batchRemove(Collection<?> c, boolean complement)
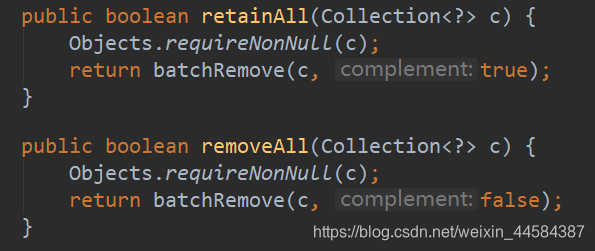
不管是 retainAll 还是 removeAll 都会调用 batchRemove 方法
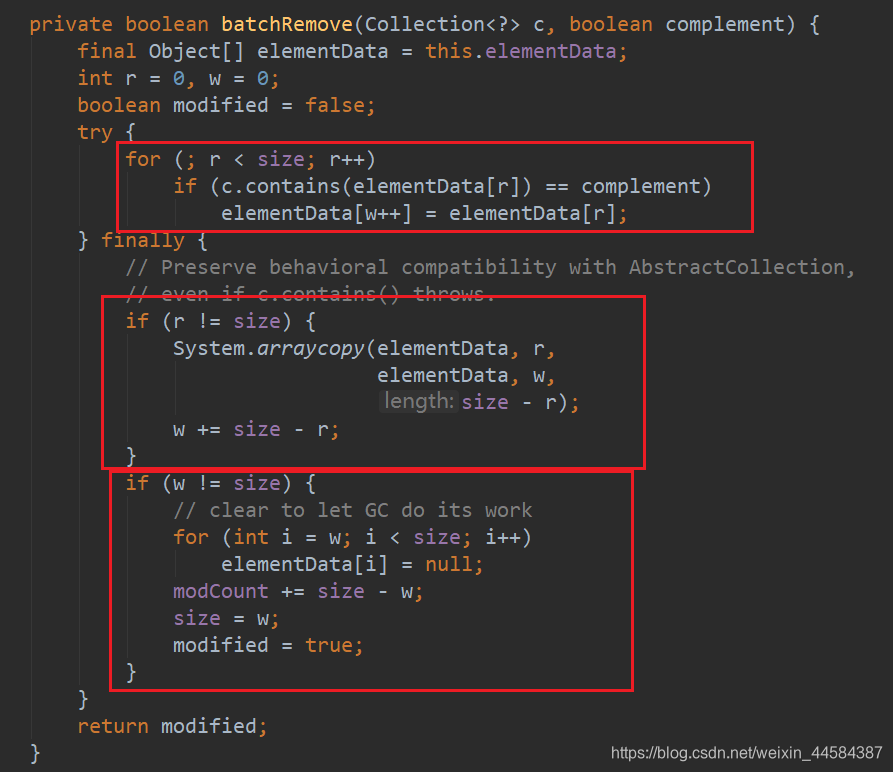
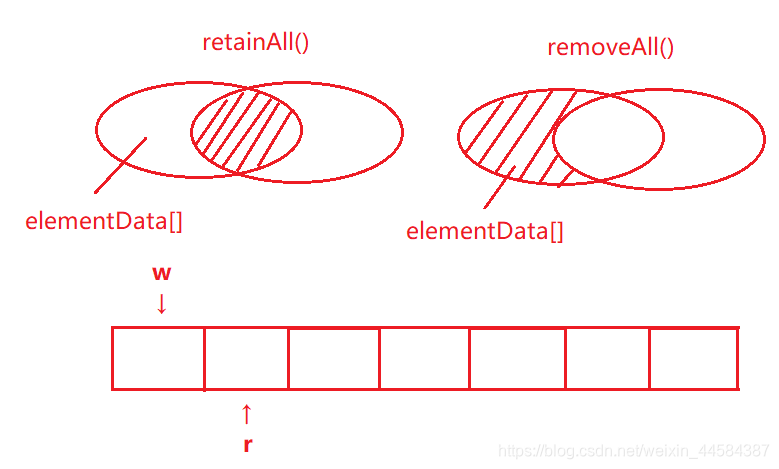
以 removeAll() 为例:removeAll 中参数 complement 为 false
removeAll() 求差集,在该方法中 r 代表读指针,w 代表写指针。r 和 w 初始都为 0,w 总是小于等于 r
在第一个 for 循环中,r 遍历数组中所有元素个数(注意:元素个数 size ≤ 数组长度 length)
if (c.contains(elementData[r]) == complement)
elementData[w++] = elementData[r];
每当 c.contains(elementData[r]) == false 时,if 为 true,便将读指针 r 指向的元素赋值给写指针 w 指向的位置。
当读指针 r 循环到 size 时便跳出循环,此时写指针 w 指向的位置之后的数组中的元素最终在 finally 语句块中都将被赋值为 null,modCount 值也会被修改。
if (w != size) {
// clear to let GC do its work
for (int i = w; i < size; i++)
elementData[i] = null;
modCount += size - w;
size = w;
modified = true;
}
从源码中我们可以发现批量删除不会改变数组大小,但 modCount 值仍会被修改。
modCount

modCount 是 AbstractList<E> 中的成员变量,记录这个列表在结构上被修改的次数。
从源码中可以发现每当进行 add 或 remove 操作时 modCount 值都会随着改变
关于在 foreach 中增加或删除元素
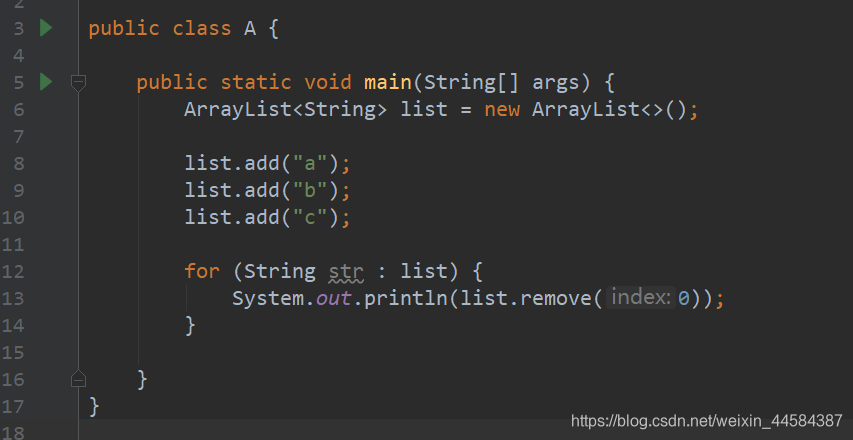
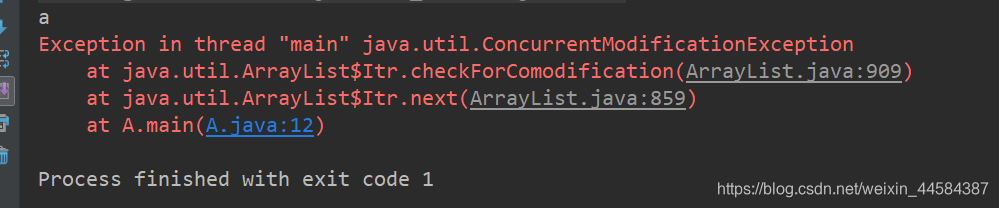
从调试中我们可以发现 foreach 的本质是使用了 iterator 迭代器
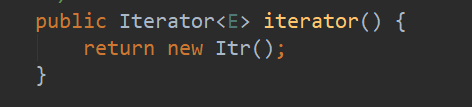
在 ArrayList 内部有一个内部类实现了 Iterator<E> 接口,每当使用 foreach 时都会返回该迭代器对象
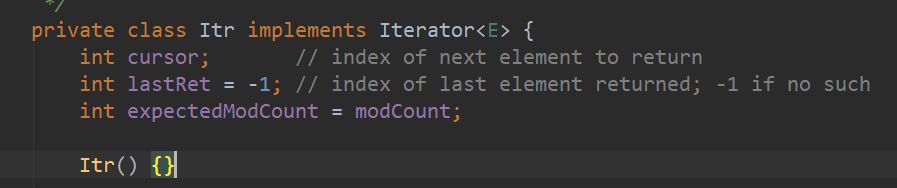
当返回该对象时,游标 cursor 初始值为 0,expectedModCount = modCount,当调用 hasNext() 方法时,判断 cursor 值是否与数组中元素个数相等,不等则返回 true
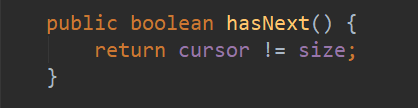
调用 next() 方法时,首先检查数组元素个数是否被修改过
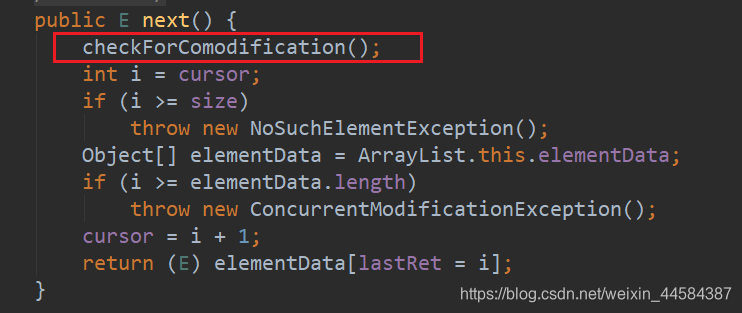
因此当 foreach 中内部第一次增加或删除元素时,modCount 会改变,而 expectedModCount 的值没变,当下一次进入 foreach 时,就会抛出并发修改异常。

get 和 set 方法非常简单
三、总结
-
ArrayList 底层使用数组实现,默认初始容量为 10,增长因子为 0.5,最好自己指定初始化容量。
-
适合随机查找和遍历,不适合插入和删除。因为当从 ArrayList 的中间位置插入或者删除元素时,需要对数组进行复制、移动、代价比较高。
-
当数组大小不满足需要增加存储能力时,可以自动扩容。
