Tensorflow:实战 Google 深度学习框架基于 Tensorflow + Vgg16 进行图像分类识别。
1.VGG-16介绍
vgg是在Very Deep Convolutional Networks for Large-Scale Image Recognition期刊上提出的。模型可以达到92.7%的测试准确度,在ImageNet的前5位。它的数据集包括1400万张图像,1000个类别。
vgg-16是一种深度卷积神经网络模型,16表示其深度,在图像分类等任务中取得了不错的效果。
vgg16 的宏观结构图如下。代码定义在tensorflow的vgg16.py文件 。注意,包括一个预处理层,使用RGB图像在0-255范围内的像素值减去平均值(在整个ImageNet图像训练集计算)。
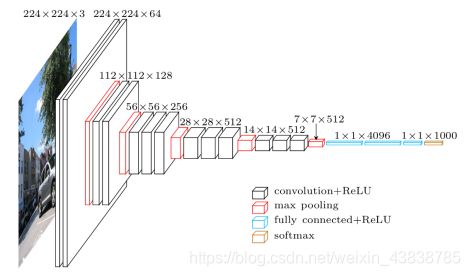
2. 文件组成
模型权重 - vgg16weights.npzTensorFlow模型- vgg16.py类名(输出模型到类名的映射) - imagenetclasses.py示例图片输入 - laska.png我们使用特定的工具转换了原作者在GitHub profile上公开可用的Caffe权重,并做了一些后续处理,以确保模型符合TensorFlow标准。最终实现可用的权重文件vgg16_weights.npz下载所有的文件到同一文件夹下,然后运行 python vgg16.py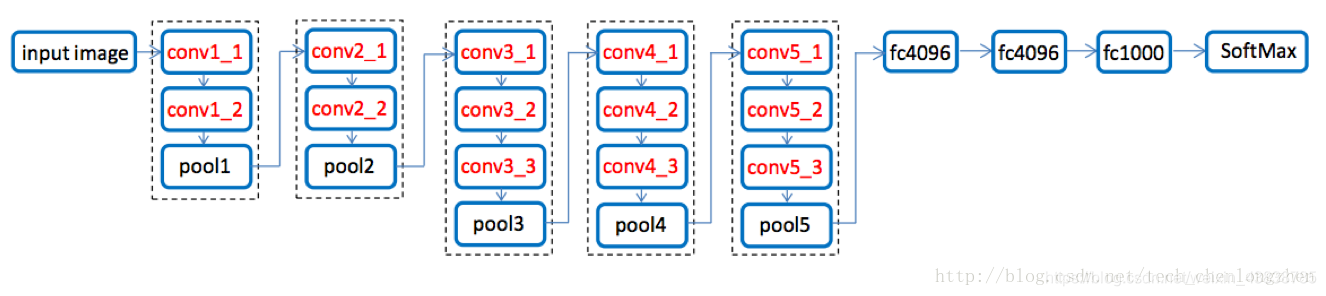
- vgg16.py文件代码
import tensorflow as tfimport numpy as npfrom scipy.misc import imread, imresizefrom imagenet_classes import class_namesclass vgg16: def __init__(self, imgs, weights=None, sess=None): self.imgs = imgs self.convlayers() self.fc_layers() self.probs = tf.nn.softmax(self.fc3l) if weights is not None and sess is not None: self.load_weights(weights, sess) def convlayers(self): self.parameters = [] # zero-mean input with tf.name_scope('preprocess') as scope: mean = tf.constant([123.68, 116.779, 103.939], dtype=tf.float32, shape=[1, 1, 1, 3], name='img_mean') images = self.imgs-mean # conv1_1 with tf.name_scope('conv1_1') as scope: kernel = tf.Variable(tf.truncated_normal([3, 3, 3, 64], dtype=tf.float32, stddev=1e-1), name='weights') conv = tf.nn.conv2d(images, kernel, [1, 1, 1, 1], padding='SAME') biases = tf.Variable(tf.constant(0.0, shape=[64], dtype=tf.float32), trainable=True, name='biases') out = tf.nn.bias_add(conv, biases) self.conv1_1 = tf.nn.relu(out, name=scope) self.parameters += [kernel, biases] # conv1_2 with tf.name_scope('conv1_2') as scope: kernel = tf.Variable(tf.truncated_normal([3, 3, 64, 64], dtype=tf.float32, stddev=1e-1), name='weights') conv = tf.nn.conv2d(self.conv1_1, kernel, [1, 1, 1, 1], padding='SAME') biases = tf.Variable(tf.constant(0.0, shape=[64], dtype=tf.float32), trainable=True, name='biases') out = tf.nn.bias_add(conv, biases) self.conv1_2 = tf.nn.relu(out, name=scope) self.parameters += [kernel, biases] # pool1 self.pool1 = tf.nn.max_pool(self.conv1_2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME', name='pool1') # conv2_1 with tf.name_scope('conv2_1') as scope: kernel = tf.Variable(tf.truncated_normal([3, 3, 64, 128], dtype=tf.float32, stddev=1e-1), name='weights') conv = tf.nn.conv2d(self.pool1, kernel, [1, 1, 1, 1], padding='SAME') biases = tf.Variable(tf.constant(0.0, shape=[128], dtype=tf.float32), trainable=True, name='biases') out = tf.nn.bias_add(conv, biases) self.conv2_1 = tf.nn.relu(out, name=scope) self.parameters += [kernel, biases] # conv2_2 with tf.name_scope('conv2_2') as scope: kernel = tf.Variable(tf.truncated_normal([3, 3, 128, 128], dtype=tf.float32, stddev=1e-1), name='weights') conv = tf.nn.conv2d(self.conv2_1, kernel, [1, 1, 1, 1], padding='SAME') biases = tf.Variable(tf.constant(0.0, shape=[128], dtype=tf.float32), trainable=True, name='biases') out = tf.nn.bias_add(conv, biases) self.conv2_2 = tf.nn.relu(out, name=scope) self.parameters += [kernel, biases] # pool2 self.pool2 = tf.nn.max_pool(self.conv2_2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME', name='pool2') # conv3_1 with tf.name_scope('conv3_1') as scope: kernel = tf.Variable(tf.truncated_normal([3, 3, 128, 256], dtype=tf.float32, stddev=1e-1), name='weights') conv = tf.nn.conv2d(self.pool2, kernel, [1, 1, 1, 1], padding='SAME') biases = tf.Variable(tf.constant(0.0, shape=[256], dtype=tf.float32), trainable=True, name='biases') out = tf.nn.bias_add(conv, biases) self.conv3_1 = tf.nn.relu(out, name=scope) self.parameters += [kernel, biases] # conv3_2 with tf.name_scope('conv3_2') as scope: kernel = tf.Variable(tf.truncated_normal([3, 3, 256, 256], dtype=tf.float32, stddev=1e-1), name='weights') conv = tf.nn.conv2d(self.conv3_1, kernel, [1, 1, 1, 1], padding='SAME') biases = tf.Variable(tf.constant(0.0, shape=[256], dtype=tf.float32), trainable=True, name='biases') out = tf.nn.bias_add(conv, biases) self.conv3_2 = tf.nn.relu(out, name=scope) self.parameters += [kernel, biases] # conv3_3 with tf.name_scope('conv3_3') as scope: kernel = tf.Variable(tf.truncated_normal([3, 3, 256, 256], dtype=tf.float32, stddev=1e-1), name='weights') conv = tf.nn.conv2d(self.conv3_2, kernel, [1, 1, 1, 1], padding='SAME') biases = tf.Variable(tf.constant(0.0, shape=[256], dtype=tf.float32), trainable=True, name='biases') out = tf.nn.bias_add(conv, biases) self.conv3_3 = tf.nn.relu(out, name=scope) self.parameters += [kernel, biases] # pool3 self.pool3 = tf.nn.max_pool(self.conv3_3, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME', name='pool3') # conv4_1 with tf.name_scope('conv4_1') as scope: kernel = tf.Variable(tf.truncated_normal([3, 3, 256, 512], dtype=tf.float32, stddev=1e-1), name='weights') conv = tf.nn.conv2d(self.pool3, kernel, [1, 1, 1, 1], padding='SAME') biases = tf.Variable(tf.constant(0.0, shape=[512], dtype=tf.float32), trainable=True, name='biases') out = tf.nn.bias_add(conv, biases) self.conv4_1 = tf.nn.relu(out, name=scope) self.parameters += [kernel, biases] # conv4_2 with tf.name_scope('conv4_2') as scope: kernel = tf.Variable(tf.truncated_normal([3, 3, 512, 512], dtype=tf.float32, stddev=1e-1), name='weights') conv = tf.nn.conv2d(self.conv4_1, kernel, [1, 1, 1, 1], padding='SAME') biases = tf.Variable(tf.constant(0.0, shape=[512], dtype=tf.float32), trainable=True, name='biases') out = tf.nn.bias_add(conv, biases) self.conv4_2 = tf.nn.relu(out, name=scope) self.parameters += [kernel, biases] # conv4_3 with tf.name_scope('conv4_3') as scope: kernel = tf.Variable(tf.truncated_normal([3, 3, 512, 512], dtype=tf.float32, stddev=1e-1), name='weights') conv = tf.nn.conv2d(self.conv4_2, kernel, [1, 1, 1, 1], padding='SAME') biases = tf.Variable(tf.constant(0.0, shape=[512], dtype=tf.float32), trainable=True, name='biases') out = tf.nn.bias_add(conv, biases) self.conv4_3 = tf.nn.relu(out, name=scope) self.parameters += [kernel, biases] # pool4 self.pool4 = tf.nn.max_pool(self.conv4_3, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME', name='pool4') # conv5_1 with tf.name_scope('conv5_1') as scope: kernel = tf.Variable(tf.truncated_normal([3, 3, 512, 512], dtype=tf.float32, stddev=1e-1), name='weights') conv = tf.nn.conv2d(self.pool4, kernel, [1, 1, 1, 1], padding='SAME') biases = tf.Variable(tf.constant(0.0, shape=[512], dtype=tf.float32), trainable=True, name='biases') out = tf.nn.bias_add(conv, biases) self.conv5_1 = tf.nn.relu(out, name=scope) self.parameters += [kernel, biases] # conv5_2 with tf.name_scope('conv5_2') as scope: kernel = tf.Variable(tf.truncated_normal([3, 3, 512, 512], dtype=tf.float32, stddev=1e-1), name='weights') conv = tf.nn.conv2d(self.conv5_1, kernel, [1, 1, 1, 1], padding='SAME') biases = tf.Variable(tf.constant(0.0, shape=[512], dtype=tf.float32), trainable=True, name='biases') out = tf.nn.bias_add(conv, biases) self.conv5_2 = tf.nn.relu(out, name=scope) self.parameters += [kernel, biases] # conv5_3 with tf.name_scope('conv5_3') as scope: kernel = tf.Variable(tf.truncated_normal([3, 3, 512, 512], dtype=tf.float32, stddev=1e-1), name='weights') conv = tf.nn.conv2d(self.conv5_2, kernel, [1, 1, 1, 1], padding='SAME') biases = tf.Variable(tf.constant(0.0, shape=[512], dtype=tf.float32), trainable=True, name='biases') out = tf.nn.bias_add(conv, biases) self.conv5_3 = tf.nn.relu(out, name=scope) self.parameters += [kernel, biases] # pool5 self.pool5 = tf.nn.max_pool(self.conv5_3, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME', name='pool4') def fc_layers(self): # fc1 with tf.name_scope('fc1') as scope: shape = int(np.prod(self.pool5.get_shape()[1:])) fc1w = tf.Variable(tf.truncated_normal([shape, 4096], dtype=tf.float32, stddev=1e-1), name='weights') fc1b = tf.Variable(tf.constant(1.0, shape=[4096], dtype=tf.float32), trainable=True, name='biases') pool5_flat = tf.reshape(self.pool5, [-1, shape]) fc1l = tf.nn.bias_add(tf.matmul(pool5_flat, fc1w), fc1b) self.fc1 = tf.nn.relu(fc1l) self.parameters += [fc1w, fc1b] # fc2 with tf.name_scope('fc2') as scope: fc2w = tf.Variable(tf.truncated_normal([4096, 4096], dtype=tf.float32, stddev=1e-1), name='weights') fc2b = tf.Variable(tf.constant(1.0, shape=[4096], dtype=tf.float32), trainable=True, name='biases') fc2l = tf.nn.bias_add(tf.matmul(self.fc1, fc2w), fc2b) self.fc2 = tf.nn.relu(fc2l) self.parameters += [fc2w, fc2b] # fc3 with tf.name_scope('fc3') as scope: fc3w = tf.Variable(tf.truncated_normal([4096, 1000], dtype=tf.float32, stddev=1e-1), name='weights') fc3b = tf.Variable(tf.constant(1.0, shape=[1000], dtype=tf.float32), trainable=True, name='biases') self.fc3l = tf.nn.bias_add(tf.matmul(self.fc2, fc3w), fc3b) self.parameters += [fc3w, fc3b] def load_weights(self, weight_file, sess): weights = np.load(weight_file) keys = sorted(weights.keys()) for i, k in enumerate(keys): print i, k, np.shape(weights[k]) sess.run(self.parameters[i].assign(weights[k]))if __name__ == '__main__': sess = tf.Session() imgs = tf.placeholder(tf.float32, [None, 224, 224, 3]) vgg = vgg16(imgs, 'vgg16_weights.npz', sess) img1 = imread('laska.png', mode='RGB') img1 = imresize(img1, (224, 224)) prob = sess.run(vgg.probs, feed_dict={vgg.imgs: [img1]})[0] preds = (np.argsort(prob)[::-1])[0:5] for p in preds: #print class_names[p], prob[p] print("class_name {}: step {}".format(class_names[p], prob[p]))运行,测试
测试1:
输入图片为laska.png 运行结果:
运行结果:
2018-03-23 11:04:38.311802: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use AVX2 instructions, but these are available on your machine and could speed up CPU computations.2018-03-23 11:04:38.311873: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use FMA instructions, but these are available on your machine and could speed up CPU computations.0 conv1_1_W (3, 3, 3, 64)1 conv1_1_b (64,)2 conv1_2_W (3, 3, 64, 64)3 conv1_2_b (64,)4 conv2_1_W (3, 3, 64, 128)5 conv2_1_b (128,)6 conv2_2_W (3, 3, 128, 128)7 conv2_2_b (128,)8 conv3_1_W (3, 3, 128, 256)9 conv3_1_b (256,)10 conv3_2_W (3, 3, 256, 256)11 conv3_2_b (256,)12 conv3_3_W (3, 3, 256, 256)13 conv3_3_b (256,)14 conv4_1_W (3, 3, 256, 512)15 conv4_1_b (512,)16 conv4_2_W (3, 3, 512, 512)17 conv4_2_b (512,)18 conv4_3_W (3, 3, 512, 512)19 conv4_3_b (512,)20 conv5_1_W (3, 3, 512, 512)21 conv5_1_b (512,)22 conv5_2_W (3, 3, 512, 512)23 conv5_2_b (512,)24 conv5_3_W (3, 3, 512, 512)25 conv5_3_b (512,)26 fc6_W (25088, 4096)27 fc6_b (4096,)28 fc7_W (4096, 4096)29 fc7_b (4096,)30 fc8_W (4096, 1000)31 fc8_b (1000,)class_name **weasel**: step 0.693385839462class_name polecat, fitch, foulmart, foumart, Mustela putorius: step 0.175387635827class_name mink: step 0.12208583951class_name black-footed ferret, ferret, Mustela nigripes: step 0.00887066219002class_name otter: step 0.000121083263366分类结果为weasel
测试2:输入图片为多场景
运行结果为:
2018-03-23 11:15:22.718228: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use AVX2 instructions, but these are available on your machine and could speed up CPU computations.2018-03-23 11:15:22.718297: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use FMA instructions, but these are available on your machine and could speed up CPU computations.0 conv1_1_W (3, 3, 3, 64)1 conv1_1_b (64,)2 conv1_2_W (3, 3, 64, 64)3 conv1_2_b (64,)4 conv2_1_W (3, 3, 64, 128)5 conv2_1_b (128,)6 conv2_2_W (3, 3, 128, 128)7 conv2_2_b (128,)8 conv3_1_W (3, 3, 128, 256)9 conv3_1_b (256,)10 conv3_2_W (3, 3, 256, 256)11 conv3_2_b (256,)12 conv3_3_W (3, 3, 256, 256)13 conv3_3_b (256,)14 conv4_1_W (3, 3, 256, 512)15 conv4_1_b (512,)16 conv4_2_W (3, 3, 512, 512)17 conv4_2_b (512,)18 conv4_3_W (3, 3, 512, 512)19 conv4_3_b (512,)20 conv5_1_W (3, 3, 512, 512)21 conv5_1_b (512,)22 conv5_2_W (3, 3, 512, 512)23 conv5_2_b (512,)24 conv5_3_W (3, 3, 512, 512)25 conv5_3_b (512,)26 fc6_W (25088, 4096)27 fc6_b (4096,)28 fc7_W (4096, 4096)29 fc7_b (4096,)30 fc8_W (4096, 1000)31 fc8_b (1000,)class_name alp: step 0.830908000469class_name church, church building: step 0.0817768126726class_name castle: step 0.024959910661class_name valley, vale: step 0.0158758834004class_name monastery: step 0.0100631769747分类结果把高山,教堂,城堡,山谷,修道院都识别出来了,效果非常不错,虽然各种精度不高,但是类别是齐全的。
测试3:
输入图片为 运行结果为
运行结果为
2018-03-23 11:34:50.490069: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use AVX2 instructions, but these are available on your machine and could speed up CPU computations.2018-03-23 11:34:50.490137: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use FMA instructions, but these are available on your machine and could speed up CPU computations.0 conv1_1_W (3, 3, 3, 64)1 conv1_1_b (64,)2 conv1_2_W (3, 3, 64, 64)3 conv1_2_b (64,)4 conv2_1_W (3, 3, 64, 128)5 conv2_1_b (128,)6 conv2_2_W (3, 3, 128, 128)7 conv2_2_b (128,)8 conv3_1_W (3, 3, 128, 256)9 conv3_1_b (256,)10 conv3_2_W (3, 3, 256, 256)11 conv3_2_b (256,)12 conv3_3_W (3, 3, 256, 256)13 conv3_3_b (256,)14 conv4_1_W (3, 3, 256, 512)15 conv4_1_b (512,)16 conv4_2_W (3, 3, 512, 512)17 conv4_2_b (512,)18 conv4_3_W (3, 3, 512, 512)19 conv4_3_b (512,)20 conv5_1_W (3, 3, 512, 512)21 conv5_1_b (512,)22 conv5_2_W (3, 3, 512, 512)23 conv5_2_b (512,)24 conv5_3_W (3, 3, 512, 512)25 conv5_3_b (512,)26 fc6_W (25088, 4096)27 fc6_b (4096,)28 fc7_W (4096, 4096)29 fc7_b (4096,)30 fc8_W (4096, 1000)31 fc8_b (1000,)class_name cup: step 0.543631911278class_name coffee mug: step 0.364796578884class_name pitcher, ewer: step 0.0259610358626class_name eggnog: step 0.0117611540481class_name water jug: step 0.00806392729282分类结果为cup测试4:输入图片为 运行结果为
运行结果为
2018-03-23 11:37:23.573090: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use AVX2 instructions, but these are available on your machine and could speed up CPU computations.2018-03-23 11:37:23.573159: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use FMA instructions, but these are available on your machine and could speed up CPU computations.0 conv1_1_W (3, 3, 3, 64)1 conv1_1_b (64,)2 conv1_2_W (3, 3, 64, 64)3 conv1_2_b (64,)4 conv2_1_W (3, 3, 64, 128)5 conv2_1_b (128,)6 conv2_2_W (3, 3, 128, 128)7 conv2_2_b (128,)8 conv3_1_W (3, 3, 128, 256)9 conv3_1_b (256,)10 conv3_2_W (3, 3, 256, 256)11 conv3_2_b (256,)12 conv3_3_W (3, 3, 256, 256)13 conv3_3_b (256,)14 conv4_1_W (3, 3, 256, 512)15 conv4_1_b (512,)16 conv4_2_W (3, 3, 512, 512)17 conv4_2_b (512,)18 conv4_3_W (3, 3, 512, 512)19 conv4_3_b (512,)20 conv5_1_W (3, 3, 512, 512)21 conv5_1_b (512,)22 conv5_2_W (3, 3, 512, 512)23 conv5_2_b (512,)24 conv5_3_W (3, 3, 512, 512)25 conv5_3_b (512,)26 fc6_W (25088, 4096)27 fc6_b (4096,)28 fc7_W (4096, 4096)29 fc7_b (4096,)30 fc8_W (4096, 1000)31 fc8_b (1000,)class_name cellular telephone, cellular phone, cellphone, cell, mobile phone: step 0.465327292681class_name iPod: step 0.10543012619class_name radio, wireless: step 0.0810257941484class_name hard disc, hard disk, fixed disk: step 0.0789099931717class_name modem: step 0.0603163056076分类结果为 cellular telephone测试5:输入图片为 运行结果为
运行结果为
2018-03-23 11:40:40.956946: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use AVX2 instructions, but these are available on your machine and could speed up CPU computations.2018-03-23 11:40:40.957016: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use FMA instructions, but these are available on your machine and could speed up CPU computations.0 conv1_1_W (3, 3, 3, 64)1 conv1_1_b (64,)2 conv1_2_W (3, 3, 64, 64)3 conv1_2_b (64,)4 conv2_1_W (3, 3, 64, 128)5 conv2_1_b (128,)6 conv2_2_W (3, 3, 128, 128)7 conv2_2_b (128,)8 conv3_1_W (3, 3, 128, 256)9 conv3_1_b (256,)10 conv3_2_W (3, 3, 256, 256)11 conv3_2_b (256,)12 conv3_3_W (3, 3, 256, 256)13 conv3_3_b (256,)14 conv4_1_W (3, 3, 256, 512)15 conv4_1_b (512,)16 conv4_2_W (3, 3, 512, 512)17 conv4_2_b (512,)18 conv4_3_W (3, 3, 512, 512)19 conv4_3_b (512,)20 conv5_1_W (3, 3, 512, 512)21 conv5_1_b (512,)22 conv5_2_W (3, 3, 512, 512)23 conv5_2_b (512,)24 conv5_3_W (3, 3, 512, 512)25 conv5_3_b (512,)26 fc6_W (25088, 4096)27 fc6_b (4096,)28 fc7_W (4096, 4096)29 fc7_b (4096,)30 fc8_W (4096, 1000)31 fc8_b (1000,)class_name water bottle: step 0.75726544857class_name pop bottle, soda bottle: step 0.0976340323687class_name nipple: step 0.0622750669718class_name water jug: step 0.0233819428831class_name soap dispenser: step 0.0179366543889分类结果为 water bottle
参考
阅读全文: http://gitbook.cn/gitchat/activity/5e5fb34aa2898b2cd7a66bdf
您还可以下载 CSDN 旗下精品原创内容社区 GitChat App ,阅读更多 GitChat 专享技术内容哦。

