Jsoup:jsoup 是一款Java 的HTML解析器,可直接解析某个 URL 地址、HTML 文本内容。它提供了一套非常省力的 API,可通过 DOM,CSS 以及类似于 jQuery 的操作方法来取出和操作数据
(1)导入jar包
(2)获取Document对象
(3)获取对应的标签Element对象
(4)获取数据
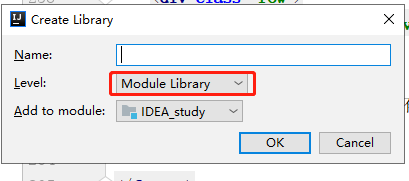
- 导入 jar 包,并将 建立的 libs 设置为 Module Library

- 具体使用
package jsoup;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.File;
public class JsoupDemo {
public static void main(String[] args) throws Exception{
//2.1获取student.xml的path
String path = JsoupDemo.class.getClassLoader().getResource("student.xml").getPath();
//2.2解析xml文档,加载文档进内存,获取dom树--->Document
Document document = Jsoup.parse(new File(path),"utf-8");
//3.获取元素对象 Element
Elements elements = document.getElementsByTag("name");
System.out.println(elements.size());
//3.1获取第一个name的Element对象
Element element = elements.get(0);
//3.2获取数据
String name = element.text();
System.out.println(name);
}
}
