原论文地址:http://cn.arxiv.org/pdf/1703.06870v3
Mask R-CNN是在Faster R-CNN的物体检测基础上,增加了物体分割部分,并做了一些优化,下面会作具体描述。
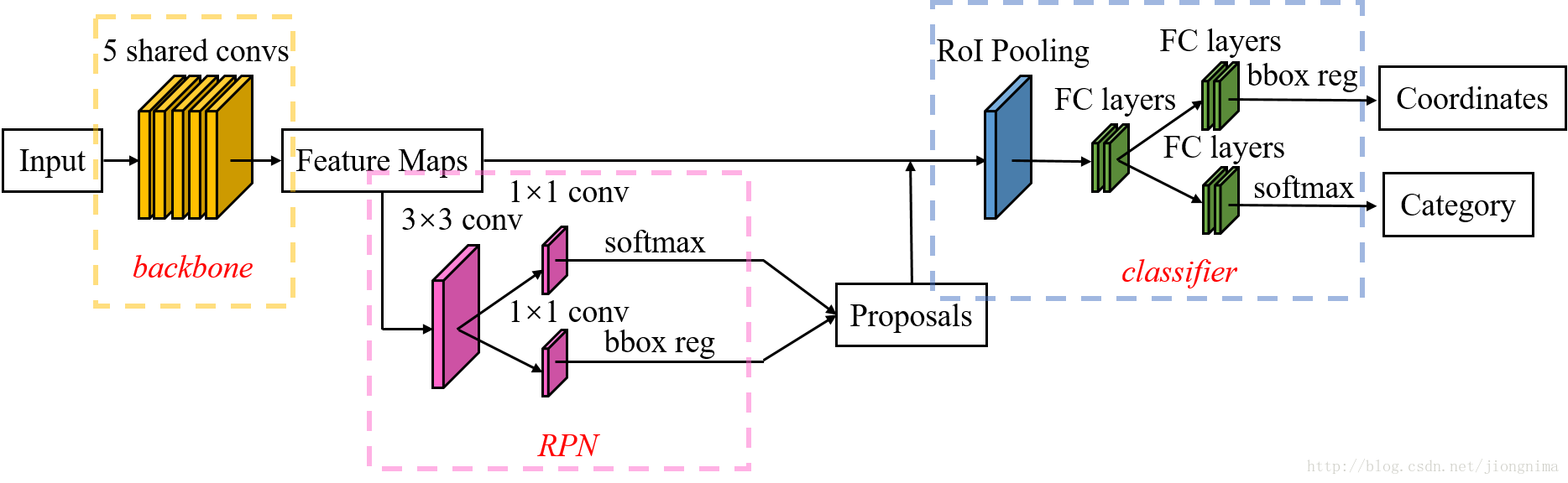
下面为Faster R-CNN的网络结构图:
下面为Mask R-CNN的网络结构图:
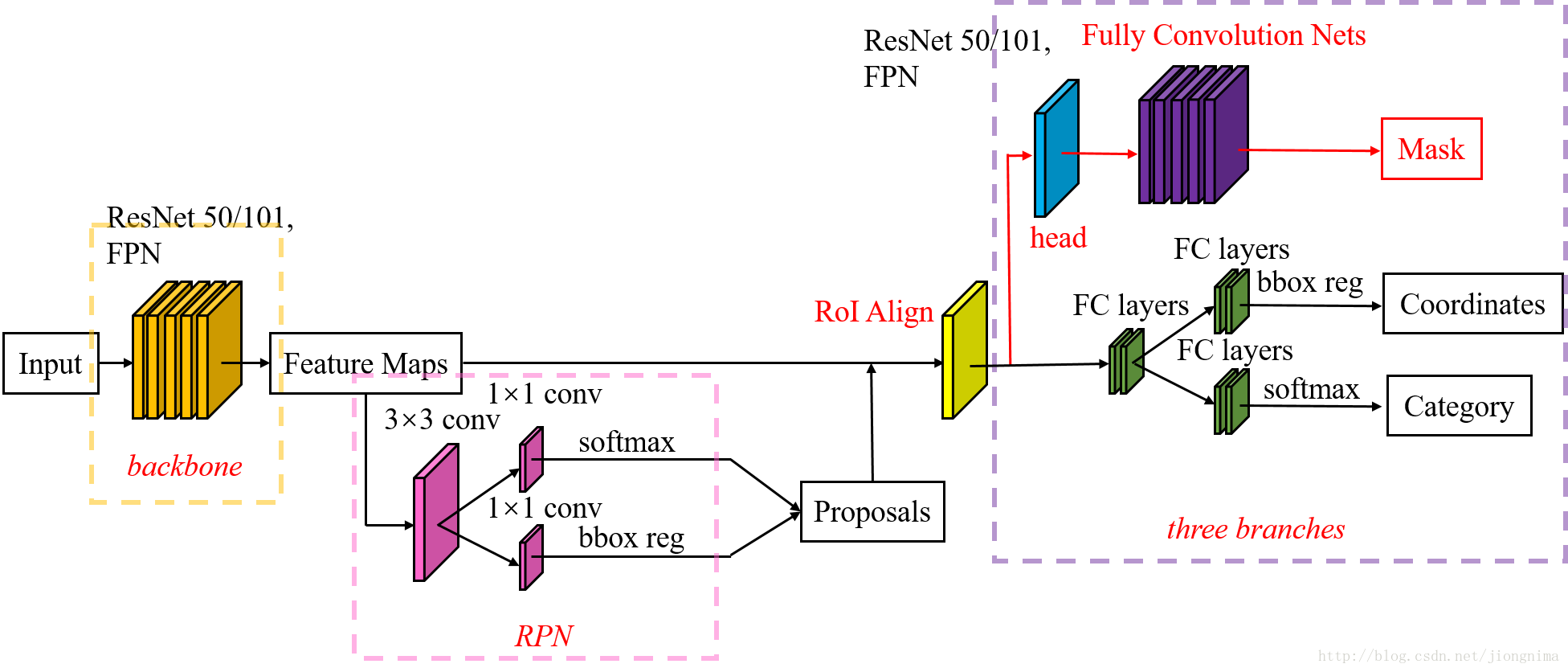
Mask R-CNN相对于Faster R-CNN改变如下:
1.使用ResNet101进行提取Feature Maps。
2.用RoI Align替代RoI Pooling,使用线性插值方式增加检测框精度。
3.增加独立的Mask层,用于物体分割。
在Mask R-CNN里,首先输入图片会经过FPN,提取出5层Feature Map。FPN使用的是ResNet 101网络结构,网络通过向下传递,然后再向上合并特征, 输出C2、C3、C4、C5层Feature Map,C6为最后一层做2*2 Max Pooling得到。FPN结构如下:


第二步,FPN提取到的特征会传入RPN网络,生成约20000个anchor,先做3*3 Conv进一步提取特征,再分别经过1*1 Conv做前景与背景分类,并修正目标框坐标。对超出范围的目标框进行裁剪,去掉宽高太小的目标框,然后按前景分数倒序输出前12000个proposal。最后用NMS算法排除掉重叠的proposal,输出前2000个proposal。
第三步,使用proposal框取的特征经过RoI Align线性插值方式输出统一大小的特征,最后输出分类、目标框与Mask。
参考资料:
https://blog.csdn.net/ghw15221836342/article/details/79549387
