目录
预训练
word2vec
elmo和bert
早期的语言模型n-gram
skip-grim 和CBOW
word2vec的局限性
elmo的局限性
Bert原理
Masked LM
transform
Next Sentence Prediction
Bert的输入
mask的规则
【CLS】和【SEP】
Bert的使用(文本相似度为例)
下载代码
输入数据地址
传递训练集,验证集和测试集
完成训练
预训练
2018年的bert火遍了大江南北,所以今天我们来聊一聊bert的来龙去脉,以及它的原理和使用,首先我认为bert是一个预训练的模型,在bert之前其实也有很多类似的模型,当然比较有名的elmo(就是命不好),所以我认为想要了解bert的原理之前,必须要明白什么是预训练模型。
word2vec
预训练顾名思义是为了更好的执行我们的任务而需要提前做的一些准备工作,比如我们去训练一个神经网络,而embdeding层往往是我们提前使用word2vec将词训练成为词向量,因此我们也可以将word2vec称为预训练模型。
那么新的问题来了?像word2vec已经可以把词向量做到低维稠密又包含语义为什么我们还要发明elmo或者bert呢?答案很简单word2vec不够我们用啦。或者说不能够满足需求,word2vec是不包含上下文的,或者说表达的语义不够(具体的推导和详解我会在word2vec中解释)由于word2vec的skip-gram是一个词预测周围的词,而且由于词典太大,不得不使用负采样的方式进行。我觉得这也是他对于上下文提取信息不足的原因。所以为了充分的提取每一个词的上下文信息,后来出现了elmo和bert,我们也叫他们语言模型。
elmo和bert
其实elmo和bert的目的是一样的,使我们训练的词向量能够包含上下文信息。当然他们不仅能训练出词向量嵌入到其他模型,用bert或者elmo训练出的模型有极大的泛化能力,我们可以在模型的基础上进行我们的任务,比如分类,文本相似度等,但由于bert自身的原理,他不能作为一个生成模型,所以在生成方面给nlp留了一些活路,elmo也有一些自身的弊端(其实就是两个单向的lstm肯定会存在梯度消失还有串行计算的问题)所以又后来有发展了XLNnet(以后再说),当然在判别或者预测上bert的能力还是非常强大的。
我们知道训练bert的目的是为了获取上下文信息,但是在很早很早之前我们就努力的往这方面发展了:
早期的语言模型n-gram
n-gram是比较早期的语言模型,也是最简单最常用的,举个例子:“今天周一大家都很开心去上学”,通过分词我们可以将这句话分为[“今天”,“周一”,“大家”,“都”,”很开心”,“去上学”],而这句话生成的概率可以用一个公式来表示如公式(1):

这也是根据我们大家常用的贝叶斯定理,如公式(2):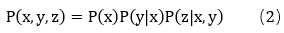
转换到nlp中则是公式(3):
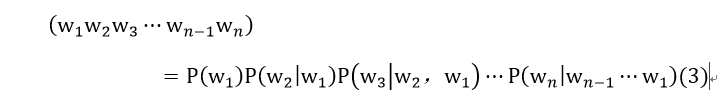
根据公式我们可以知道每一个词的生成是依赖于前面的词,但并不一定是前面所有的词都和当前词是有关系的,根据马尔科夫的假设,一个词是与相邻的几个词有关,因此我们不再以一个词依赖于前面所有的词。只依赖前面一个词 或者两个词,
这样我们的公式(3)可以转变为公式(4):
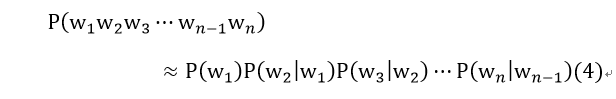
公式(4)可以改写成公式(5)
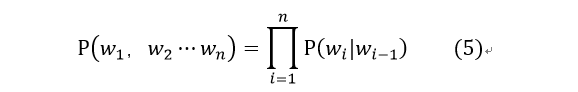
当然如果当前词依赖前两个词的话可以写成公式(6):
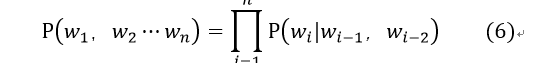
依赖3个词4个词也是可以的,n-gram的大概原理就是这样,假设每个词依赖前面一个词我们叫1-gram,依赖两个时我们叫2-gram以此类推。N的时候我们称为N-gram。
skip-grim 和CBOW
根据N-gram的原理,我们知道每个词依赖于他前面的一些词,利用这种性质我们很容易计算出每个词的特征,但是实际往往不是这样的,文章中的每个词不仅与前面的词有关联,它与后面的词也有关联,考虑到这个因素,我们又发明了skip-grim 和CBOW ,一个是利用一个词预测周围的词,另一个是利用周围的词预测当前词,再使用分布式的表示方式将单词用词向量的形式表示出来,这样即低维稠密又包含语义关系,也就是我们常用的word2vec。
word2vec的局限性
但是word2vec还是不够强大,我们要得到的词是在上下文中包含的语义信息而不是当前词,如果使用skip-grim(有空再写一篇原理)预测整个文本的词不现实,计算量超级大。所以我们使用负采样的方式来计算词向量。也就导致word2vec有自身的局限性。
elmo的局限性
到了今天,nlp的发展的越来越迅速,出现了seq2seq端到端,attention,transform等深度模型,当然还有cnn,Lstm,Gru神经网络。所以人们想利用深度学习来训练我们的文本。使每个词都包含上下文信息,因此出现了elmo和bert当然现在又出现了bert的轻量级albert。在这里elmo就不跟大家细讲了,它主要使用了正反方向的两个LSTM进行预测下一个词(不是Bi-LSTM,这样会造成自己看见自己的现象)当然他也就有着LSTM的两大问题:1、梯度消失的问题 2、不能并行计算导致时间成本太高。因此科学家们想到了使用transform来进行预训练也就是bert。
Bert原理
Masked LM
我们知道bert目的是对于每个单词提取上下文的信息,但是怎么提取呢?我们知道elmo利用Lstm预测下一单词的信息,通过使用梯度下降法不断地反向传播。优化参数,从而训练出一个包含上下文信息的模型。
这个时候有个聪明的人想到了一个方法,比如给定一个句子; “今天周一大家都很开心去上学”,从这句话中随机的去将一个词打上马赛克(mask),这样这句话就表示成”今天周一大家都mask去上学“”,然后把这句话放到模型中让模型预测mask表示的是什么,不断的进行反向传播,最终模型训练出mask的上下文表示。这样不断进行循环计算使这个模型包含训练数据中每个词的上下文信息。此方法被称为“Masked LM”(MLM)如图(1)。

这就是bert最核心的一个原理,也就是为什么bert可以训练每一个词的上下文信息。感觉像让机器做完形填空一样
transform
但是神经网络像Lstm,Gru由于自身是时序类的模型,在这种想法上确实很难实,正好2018年5月出现了transform让这个想法成为了现实,transform利用self—attention并行的计算两两词之间的“关系”,解决了Lstm不能并行计算的问题,更没有梯度消失这样的问题存在,而且并行计算可以让计算机完成bert的想法如图(2)。


Next Sentence Prediction
当然bert还能够识别句子级别的联系,在下游任务中很多都需要句子关系,比如问答系统,语言推理等,bert在这里的原理是数据分成两个部分,一部分是连续的,另一部分是不连续的,随机输入训练数据,让bert进行预测那两个句子是连续的,那些不是连续的,从而能够提取句子之间的联系,这种方法被称为:Next Sentence Prediction。
Bert的输入
由于transform可以并行计算的原因,它也就不具备Lstm的时序类的特性,因此Bert在embedding层时加入位置信息,也就是Position Embeddings,它表示每个单词的位置,为了表示句子之间的关系,又加入Segment Embeddings用来区别两种句子,以及每个单词本身的Embedding,如图(4)所示:

mask的规则
其他的和transform基本没有什么区别了,说白了bert是利用Transform让机器做完形填空,在做完形填空时了解每一个单词,当然mask也有一定的规则
比如一篇文本中出现10个“天气”,mask的规则是
有80%的概率用“[mask]”标记来替换——8个“天气”
有10%的概率用随机采样的一个单词来替换——1个“天气”
有10%的概率不做替换——1个“天气”
【CLS】和【SEP】
Bert中还有两个输入【CLS】和【SEP】,【CLS】表示首位特殊符号,输出为C,作者表示C包含这句话的含义,【SEP】表示分隔符,用来将句子隔开,既然C表示句子含义,我们就可以将在C出加一层全连接进行softmax分类,这样可以比较简单的完成分类任务,下面以文本相似度计算为例,怎么使用bert完成操作。

Bert的使用(文本相似度为例)
下载代码
Bert的代码也被谷歌开源啦!这里以文本相似度为例,教大家怎使用bert计算两个文本之间的相似度,当然如果是特定任务还是得fine-tuning(微调)。
首先下载好源代码,
https://github.com/google-research/bert
下载google训练好的中文语料模型
https://storage.googleapis.com/bert_models/2018_11_03/chinese_L-12_H-768_A-12.zip
使用pycharm打开,当然这里一定要预先配置好tensorflow的环境,打开是这个样子的

输入数据地址
在使用模型之前,必须要把数据地址写好,,因此首先要明白几个参数的作用,代码如图所示
| 参数名 | 解释 |
|---|---|
| config_name | Bert设置的地址 |
| ckpt_name | 谷歌训练好的模型 |
| output_dir | 结果输出地址 |
| vocab_file | 词典地址 |
| data_dir | 数据地址 |
import os
path = os.path.dirname(__file__)
model_dir = os.path.join(path, 'chinese_L-12_H-768_A-12/')
config_name = os.path.join(model_dir, 'bert_config.json')
ckpt_name = os.path.join(model_dir, 'bert_model.ckpt')
output_dir = os.path.join(model_dir, '../tmp/result/')
vocab_file = os.path.join(model_dir, 'vocab.txt')
data_dir = os.path.join(model_dir, '../data/')
将参数传递到run_classifier.py这个文件中,这样我们就可以把所需要的数据和训练好的模型传递到bert中,记住这里的地址对应文件的地址,不能写错了。
flags.DEFINE_string(
"data_dir", place.data_dir,
"The input data dir. Should contain the .tsv files (or other data files) "
"for the task.")
flags.DEFINE_string(
"bert_config_file", place.config_name,
"The config json file corresponding to the pre-trained BERT model. "
"This specifies the model architecture.")
flags.DEFINE_string("vocab_file", place.vocab_file,
"The vocabulary file that the BERT model was trained on.")
传递训练集,验证集和测试集
找到run_classifier.py文件中的DataProcessor类,这个类是用来传递数据的父类,所以在写Processor必须重写人家的方法,并且人家怕你不会传,编写了几个demo:XnliProcessor,MnliProcessor,MrpcProcessor,我们就根据作者编写的demo写自己的Processor,建立类SimProcessor继承DataProcessor
首先写训练数据的Processor,这里的guid是为了区分数据而设置的必须得填写。还有标签是string类型的,如果是单文本的任务可以没有text-b,我这里是相似度的计算因此有text-b,最后将数据封装成InputExample对象就可以了
class SimProcessor(DataProcessor):
def get_train_examples(self, data_dir):
"""Gets a collection of `InputExample`s for the train set."""
data_path =os.path.join(data_dir,'train.csv')
train_df = pd.read_csv(data_path,encoding='utf-8')
train_data = []
for index, value in enumerate(train_df.values):
guid = 'tarin-%d'%index
text_a =tokenization.convert_to_unicode(str(value[0]))
text_b = tokenization.convert_to_unicode(str(value[1]))
label = str(value[2])
train_data.append(InputExample(guid=guid, text_a=text_a, text_b=text_b, label=label))
return train_data
def get_dev_examples(self, data_dir):
data_path = os.path.join(data_dir, 'dev.csv')
dev_df = pd.read_csv(data_path, encoding='utf-8')
dev_data = []
for index, value in enumerate(dev_df.values):
guid = 'dev-%d' % index
text_a = tokenization.convert_to_unicode(str(value[0]))
text_b = tokenization.convert_to_unicode(str(value[1]))
label = str(value[2])
dev_data.append(InputExample(guid=guid, text_a=text_a, text_b=text_b, label=label))
return dev_data
def get_test_examples(self, data_dir):
data_path = os.path.join(data_dir, 'test.csv')
test_df = pd.read_csv(data_path, encoding='utf-8')
test_data = []
for index, value in enumerate(test_df.values):
guid = 'test-%d' % index
text_a = tokenization.convert_to_unicode(str(value[0]))
text_b = tokenization.convert_to_unicode(str(value[1]))
label = str(value[2])
test_data.append(InputExample(guid=guid, text_a=text_a, text_b=text_b, label=label))
return test_data
同理传递验证集和测试集也是同样的操作在这里不一一赘述了。最后写入标签这里是相似度也就是二分类的问题因此标签是0和1一定要记住是String类型的
def get_labels(self):
return['0','1']
在main函数里声明一下
def main(_):
tf.logging.set_verbosity(tf.logging.INFO)
processors = {
"mnli": MnliProcessor,
"mrpc": MrpcProcessor,
"xnli": XnliProcessor,
"sim": SimProcessor
}
并且在task_name里指定一下所使用的processor
flags.DEFINE_string("task_name", "sim", "The name of the task to train.")
do_train,do_eval,do_predict设置为True,默认为False,到这里我们就设置完bert了,下面就可以进行训练了。
flags.DEFINE_bool("do_train", True, "Whether to run training.")
flags.DEFINE_bool("do_eval", True, "Whether to run eval on the dev set.")
flags.DEFINE_bool(
"do_predict", True,
"Whether to run the model in inference mode on the test set.")
完成训练


这是我在csdn的第一篇博客,希望对大家有帮助,以后我也会经常写一些nlp相关的技术博客,希望可以和大家一起交流,有什么问题大家可以留言,我会及时回复哦。
