文章目录
预备知识
Java比较器
java.util.Comparator和java.lang.Comparable都是接口,都是用来做对象比较用的。
- 内部比较器Comparable
java.lang.Comparable被称为内部比较器,接口说明里是这样描述的。
This interface imposes a total ordering on the objects of each class thatimplements it.
This ordering is referred to as the class’s natural ordering,
and the class’s compareTo method is referred to as its natural comparison method.
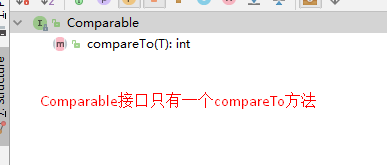
简单说来就是classA实现java.lang.Comparable接口中的public int compareTo(T o)方法,这样classA就有排序功能,那就可以直接用Collections.sort或者Arrays.sort的方法来对classA的集合进行排序。
需要注意一点的是classA的equals方法和compareTo强烈建议要保持一致,即e1.compareTo(e2) == 0和e1.equals(e2)的布尔值要是相同的。如果不是一致的,那对于没有显示指定比较器的sorted sets (and sorted maps)就会表现的失常。更详细的说明文档可参考Java8 API文档。
It is strongly recommended (though not required) that natural orderings be consistent with equals. This is so because sorted sets (and sorted maps) without explicit comparators behave “strangely” when they are used with elements (or keys) whose natural ordering is inconsistent with equals. In particular, such a sorted set (or sorted map) violates the general contract for set (or map), which is defined in terms of the equals method.
以java.lang.Integer为例,java.lang.Integer已经实现了java.lang.Comparable接口,所以可直接排序,如下图所示


- 外部比较器Comparator
java.util.Comparator被称为外部比较器,接口说明里是这样描述的。更详细的说明文档可参考Java8 API文档。
A comparison function, which imposes a total ordering on some collection of objects. Comparators can be passed to a sort method (such as Collections.sort or Arrays.sort) to allow precise control over the sort order. Comparators can also be used to control the order of certain data structures (such as sorted sets or sorted maps), or to provide an ordering for collections of objects that don’t have a natural ordering.

简单来说就是对于Object对象的集合要进行排序时可以传入Comparator来对排序进行精确的控制。如下图对Integer的集合通过传入Comparator的方式进行精确排序。

Hadoop中Writable,WritableComparable,WritableComparator的区别
| Writable | WritableComparable | WritableComparator | |
|---|---|---|---|
| 定义 | interface | interface extends Writable, Comparable | class implements RawComparator, Configurable |
| 功能 | 序列化 | 序列化+排序 | 排序 |
| MR中执行位置 | 数据在网络中传输 | 数据在网络中传输,map溢出时排序,reduce端调用reduce之前排序 | map溢出时排序,reduce端调用reduce之前排序 |
正如在MapReduce Tutorial 思考总结的Inputs and Outputs里写到对于key class和value class都必须要实现Writable接口以便能在网络间简单高效地传输数据,另外key class必须要实现WritableComparable接口以便做排序。
排序代码分析
下图中的RawComparator(sort)是第一阶段的排序,发生在map输出数据溢出文件时做的排序(是先分区再排序的即分区内有序),也发生在reduce通过http请求拷贝map输出数据做的排序。
RawComparator(group)是第二阶段的排序,发生在reduce task在调用一次reduce方法前将哪些数据共享一个key,然后作为参数<key, (list of values)>传入reduce方法里。

RawComparator(sort)代码分析
- Map端
在sortAndSpill方法里org.apache.hadoop.mapred.MapTask.MapOutputBuffer#sortAndSpill,是这段代码sorter.sort(MapOutputBuffer.this, mstart, mend, reporter);在进行排序,其中sorter默认是用的快排算法进行排序,sorter的赋值是在org.apache.hadoop.mapred.MapTask.MapOutputBuffer#init方法里,在这个init方法里还对comparator进行了赋值,如下图

然后继续跟踪job.getOutputKeyComparator(),如下图所示,如果指定了mapreduce.job.output.key.comparator.class那么就用指定的Rawcomparator作为Comparator并且利用反射实例化(所以指定的Rawcomparator必须要提供无参构造函数),否则就用WritableComparator.get(Class<? extends WritableComparable> c, Configuration conf)方法返回的Rawcomparator作为比较器。
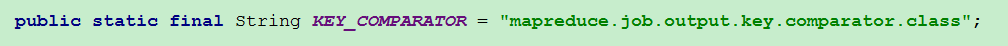

继续跟踪看WritableComparator.get(Class<? extends WritableComparable> c, Configuration conf)的实现如下。
comparators是一个ConcurrentHashMap,会在WritableComparator.define(Class c, WritableComparator comparator)用到,会先从这个Map取得这个WritableComparable对应的WritableComparator,如果没有指定的话就用默认的WritableComparator。

至此我们能看到comparator的来源有三个:一个是通过Job.setSortComparatorClass(Class)来指定RawComparator,一个是通过WritableComparator.define(Class c, WritableComparator comparator)来为WritableComparable注册对应的WritableComparator,一个是默认的WritableComparator方法。
此处的comparator是RawComparator,由于WritableComparator实现了接口RawComparator,所以WritableComparator也能作为RawComparator。
org.apache.hadoop.mapred.MapTask.MapOutputBuffer#init方法里赋值comparator。
继续跟踪排序代码sorter.sort(MapOutputBuffer.this, mstart, mend, reporter);,发现比较的时候是调用的IndexedSortable.int compare(int i, int j)方法,IndexedSortable是一个接口,MapOutputBuffer类实现了这个接口,而且从排序代码也能看出是IndexedSortable就是这个MapOutputBuffer.this。

然后查看MapOutputBuffer.compare(final int mi, final int mj)方法,发现最终调用的是MapOutputBuffer的成员变量comparator的compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2方法,该方法就是RawComparator接口定义的方法,这就是为什么上述有很大一段来解释comparator的原因。

引用RawComparator的说明文档,该接口是用来直接在字节上进行排序操作的。
A Comparator that operates directly on byte representations of objects
对于来源一自己指定实现RawComparator接口的类就要实现其具体的字节比较方法。
对于来源二/三通过继承WritableComparator类就要关注其实现的字节比较方法。WritableComparator类的字节比较方法就是从字节读出key1和key2后然后调用key class实现的compareTo方法了。所以对于自定义的类作为key class,必须要实现WritableComparable接口,这样在map的sortAndSpill阶段就可以根据WritableComparable接口中的compareTo方法排序了。

然后我们查看下Hadoop框架封装int类型的IntWritable类是如何实现的。IntWritable在实现WritableComparable接口的基础上再自定义了comparator并注册到WritableComparator里。

- reduce端
ReduceTask的run方法里org.apache.hadoop.mapred.ReduceTask#run有如下图所示这么一段代码。
其中ShuffleConsumerPlugin是一个接口,用于服务Reduce端的。
rTer的类型是RawKeyValueIterator,是一个迭代器,用于迭代在sort/merge中间数据期间的raw keys和values(即从map端拷贝过来的map输出数据)
RawKeyValueIteratoris an iterator used to iterate over the raw keys and values during sort/merge of intermediate data

进入到ShuffleConsumerPlugin接口的实现类Shuffle类的run方法里org.apache.hadoop.mapreduce.task.reduce.Shuffle#run,其中Fetcher线程就是用来shuffle拷贝数据的,这里不细究Fetcher。

继续看run方法后面的代码如下,通过merger.close()返回的RawKeyValueIterator对象。

继续跟踪进入到merger.close()方法里的finalMerge代码块

继续跟踪发现在finalMerge方法里有如下红框所示代码,这个段代码在上面map段排序分析已经详细说明过,不再赘述。然后我们看这个comparator变量在哪里用到。

追踪这个变量发现最终赋值给MergeQueue类org.apache.hadoop.mapred.Merger.MergeQueue#MergeQueue。
MergeQueue类继承PriorityQueue类

然后这个comparator对象会在org.apache.hadoop.mapred.Merger.MergeQueue#lessThan方法里用到

然后这个lessThan方法会在org.apache.hadoop.util.PriorityQueue里用到。这里引用下PriorityQueue类的说明文档。PriorityQueue维护其元素的部分排序,以便总是可以尽可能快地找到最小的元素。
A PriorityQueue maintains a partial ordering of its elements such that the least element can always be found in constant time. Put()'s and pop()'s require log(size) time.
知道comparator对象在哪里会用到之后,我们接着看org.apache.hadoop.mapred.ReduceTask#run方法里的runNewReducer代码

进入该方法会看到reducer.run(reducerContext)代码块。

接下来就是Reducer的核心逻辑
setup(context) 和reduce(context.getCurrentKey(), context.getValues(), context);及cleanup(context);就非常熟悉了。

进入到context.nextKey()方法会最终跟踪到如下代码

跟踪nextKeyValue()方法

进入到inpput.next()方法,会有排序的过程

总结:reduce端的排序是在调用reduce方法前执行的。
RawComparator(group)代码分析
继续看org.apache.hadoop.mapreduce.task.ReduceContextImpl#nextKeyValue这段代码,通过一个comparator来判断哪些key可以分配到同一个组。那么这个comparator是在哪里赋值的呢?

在org.apache.hadoop.mapred.ReduceTask#run方法里会看到如下红框所示代码job.getOutputValueGroupingComparator(),然后这个comparator会传到runNewReducer方法里最终赋值给reduceContext,这个追踪的过程就不再赘述。

至此,secondarySort的两个排序就从代码上讲清楚了。其实和RawComparator这个接口有很大的关系。
可以通过job设置这两个RawComparator。
job.setSortComparatorClass(Class<? extends RawComparator> cls)设置RawComparator(sort)。
job.setGroupingComparatorClass(Class<? extends RawComparator> cls)设置RawComparator(group)。
官方例子
SecondarySort是官方提供的一个例子。脚本运行如下。
bin/hadoop jar build/hadoop-examples.jar secondarysort in-dir out-dir
数据格式有要求,每行有两个数字first second,用空格隔开。如下所示是我的输入数据

执行secondarysort后的结果如下。

Key是由first和second组成,RawComparator(group)是根据first来分组的,即first相同的数据共享一个key。
注意官方例子中并没有job.setSortComparatorClass()来设置RawComparator(sort),而是和IntWritable一样通过WritableComparator来注册的。通过job设置或者WritableComparator来注册都是一样的。
更多例子
倒序输出
考虑这么个例子,我想输出时都是倒序输出,即从大到小输出,除了修改IntPair类的compareTo方法外,也可以通过修改IntPair类对应的comparator的compare方法实现。

官方例子中Comparator的无参构造方法中调用super方法时没有传true,是因为官方例子的compare调用的是静态方法compareBytes。
现在是要根据first和second倒序输出,所以createInstances参数必须要传入为true。
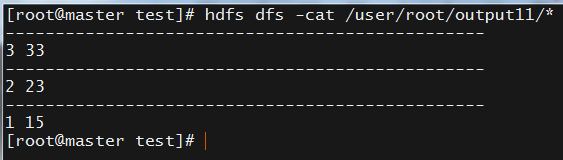
自己编写代码后打成jar包运行hadoop jar secondarysort.jar /user/root/input1 /user/root/output11,结果是倒序输出

要找到first相同的second最大的那条数据
只需要在上述例子的基础上修改如下代码,只需要输出一条即可。
非常愚蠢的方法是在reduce方法里获取到所有first相同的数据后再比较second最大的那个,没有这个必要,因为数据过多可能导致jvm内存不够。要学会合理利用MapReduce的SecondarySort机制。

结果如下
自己更改后的官方例子也会上传。
