一、可持久数据结构
主要指的是我们可以查询历史版本的情况并支持插入,利用使用之前历史版本的数据结构来减少对空间的消耗(能够对历史进行修改的是函数式)。引用于https://www.cnblogs.com/BLADEVIL/p/3681291.html
其实就是我们的数据结构的内容会不断发生变化,而我们还要查询以前的历史版本,比如某个区间的情况。
PS:01字典树
二、例题
洛谷P4735
题目描述
给定一个非负整数序列 {a}{a},初始长度为nn。
有 mm 个操作,有以下两种操作类型:
A x:添加操作,表示在序列末尾添加一个数 xx,序列的长度 n+1n+1。
Q l r x:询问操作,你需要找到一个位置 pp,满足l≤p≤r,使得: a[p]⊕a[p+1]⊕…⊕a[N]⊕x 最大,输出最大是多少。
输入格式
第一行包含两个整数 N,M,含义如问题描述所示。
第二行包含 N个非负整数,表示初始的序列 A 。
接下来 M行,每行描述一个操作,格式如题面所述。
输出格式
假设询问操作有T 个,则输出应该有 T 行,每行一个整数表示询问的答案。
输入样例
5 5
2 6 4 3 6
A 1
Q 3 5 4
A 4
Q 5 7 0
Q 3 6 6
输出
4
5
6
说明/提示
N,M≤300000。0<=a[i]<=107。

截图于洛谷榜一题解https://m-sea-blog.com/archives/1450/
三、思路:
我们要维护的是的异或和s[]并在任意区间内找到s[p]使之与(s[n]^x)取得最大异或值,——异或+区间
求异或最值我们需要建立01字典树,但是这题是有区间限制的,那么我们必须能保存任意区间[l.r]的情况。
n个数我们建立n个字典树,第i颗字典树保存1~i的数,和每个节点经过的次数sum[],那么我们要求区间[l,r]的那些数出现过时,我们可以拿第r棵01字典树减去第l-1棵01字典树得到(其实**就是sum值相减,相减后某个节点的sum值大于0就说明在区间内出现过**)
我们真的要建立n棵01字典树吗?那么空空间可想而知会非常大!建01字典树是要的,但是我们想想要如何减少空间消耗?
四、实现
我们需要依次n个数的01字典树,并且能查询1-i(i<=n)的情况,相减得到任意区间的情况。我们只需建一个01字典树(n个01字典子树合成的)即可,它包含n个数,每插入一个数(第i个数),都新建一个节点,为了保存历史版本当然要和前i-1个子树连上关系(要复制以前的版本),由于这些子树是一颗树,我们只需要知道根节点即可得到整棵树的情况,所以如果第i个数位上如果某位上不错在某个值,这个值的就存第i-1字典树的值,即把以前版本都保留下来了,还节省了空间这就是可持久化。
这个过程要有一个数组root[]保存n个历史字典树的根,查询[l,r]区间的数的情况时只需看sum[tree[r][id]]和sum[tree[l-1][id]]哪个大即可,如果前者大,说明在[l,r]区间某些数某位存在值为id的情况,然后继续贪心选位就行了
还要一个sum[]数组,记录每个节点经过的次数。
五、c++模板
(其实就比普通01字典树多了几行代码,里面有详细注释)
#include<iostream>
#include<cstdio>
#include<algorithm>
using namespace std;
#define max_size 600005
int tree[32*max_size][2];
int val[32*max_size];
int sum[32*max_size];//每个节点经过的次数
int root[max_size];//每个历史版本的树根
int sumxor[max_size];//前缀异或和
int a[max_size];//输入序列
int num=0;
void insert(int xi,int x)//第xi棵
{
root[xi]=++num;
int per=root[xi-1];//上一棵树的根
int now=root[xi];//当前树的根
for(int i=31;i>=0;i--){
int id=(x>>i)&1;
tree[now][id]=++num;//因为是另一棵新树,所以直接新建,不用判断是否存在
tree[now][id^1]=tree[per][id^1];//当前位用不上这个值,就直接继承以前的子树
now=tree[now][id];
per=tree[per][id];
sum[now]=sum[per]+1;
}
val[now]=x;
return;
}
int query(int l,int r,int x)//在[l+1,r]找一个与x异或最大的数
{
l=root[l];r=root[r];
for(int i=31;i>=0;i--){
int id=(x>>i)&1;
if(sum[tree[r][id^1]]>sum[tree[l][id^1]])//在[l,r]内此位为id^1的数存在
{
l=tree[l][id^1];r=tree[r][id^1];
}
else//不存在,当前位只能选存在的id
{
l=tree[l][id];r=tree[r][id];
}
}
return val[r];
}
int main(void)
{
int n,m,x,l,r;
char c;
scanf("%d %d",&n,&m);
for(int i=1;i<=n;i++){
scanf("%d",&a[i]);
sumxor[i]=sumxor[i-1]^a[i];
insert(i,sumxor[i]);
}
while(m--)
{
getchar();
scanf("%c",&c);
if(c=='A')//添加
{
n++;
scanf("%d",&x);
sumxor[n]=sumxor[n-1]^x;
insert(n,sumxor[n]);
}
else
{
scanf("%d %d %d",&l,&r,&x);
l--;r--;//别忘了
//找sumxor[p] p∈[l-1,r-1]使得sumxor[p]^sumxor[n]^x最大
printf("%d\n",sumxor[n]^x^query(l-1,r,sumxor[n]^x));
}
}
return 0;
}
六、注意:
l--;r--;
这一行是因为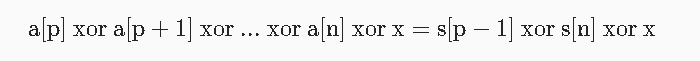
另外小心RE
