给定N个权值作为N个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。
哈夫曼编码
哈夫曼编码就是在哈夫曼树的基础上构建的,这种编码方式最大的优点就是用最少的字符包含最多的信息内容。
根据发送信息的内容,通过统计文本中相同字符的个数作为每个字符的权值,建立哈夫曼树。对于树中的每一个子树,统一规定其左孩子标记为 0 ,右孩子标记为 1 。这样,用到哪个字符时,从哈夫曼树的根结点开始,依次写出经过结点的标记,最终得到的就是该结点的哈夫曼编码。
文本中字符出现的次数越多,在哈夫曼树中的体现就是越接近树根。编码的长度越短。
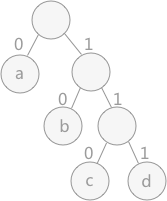
如图 所示,字符 a 用到的次数最多,其次是字符 b 。字符 a 在哈夫曼编码是 0 ,字符 b 编码为 10 ,字符 c 的编码为 110 ,字符 d 的编码为 111 。
使用程序求哈夫曼编码有两种方法:
从叶子结点一直找到根结点,逆向记录途中经过的标记。例如,图 中字符 c 的哈夫曼编码从结点 c 开始一直找到根结点,结果为:0 1 1 ,所以字符 c 的哈夫曼编码为:1 1 0(逆序输出)。
从根结点出发,一直到叶子结点,记录途中经过的标记。例如,求图 中字符 c 的哈夫曼编码,就从根结点开始,依次为:1 1 0。
#include<bits/stdc++.h>
using namespace std;
#define inf 9999999
typedef struct {
unsigned int weight;
unsigned int lchild,rchild,parent;
}Hfm,*Hfmtree;
typedef char ** Hfmcode;
int min1,min2;
void Select(Hfmtree &Ht,int n)
{
int x1=inf,x2=inf;
for(int i=1;i<=n;i++)
{
if(x1>Ht[i].weight&&Ht[i].parent==0)
{
x1=Ht[i].weight;
min1=i;
}
}
for(int i=1;i<=n;i++)
{
if(x2>Ht[i].weight&&Ht[i].parent==0&&min1!=i)
{
x2=Ht[i].weight;
min2=i;
}
}
}
void HfmCodeing(Hfmtree &Ht,Hfmcode &Hc,int *a,int n)
{
if(n<=1)
return;
int zjd=2*n-1;
Ht=new Hfm[zjd+1];
Hfmtree p;
int i;
for(p=Ht+1,i=0;i<n;i++,p++,a++)
{
p->weight=*a;p->rchild=0;p->lchild=0;p->parent=0;
}
for(;i<zjd;i++,p++)
{
p->weight=0;p->rchild=0;p->lchild=0;p->parent=0;
}
for(i=n+1;i<=zjd;i++)
{
Select(Ht,i-1);
Ht[i].weight=Ht[min1].weight+Ht[min2].weight;
Ht[i].lchild=min1;
Ht[i].rchild=min2;
Ht[min1].parent=i;
Ht[min2].parent=i;
}
Hc=new char*[n+1];
char *q;
q=new char[n];
q[n-1]='\n';
for(int j=1;j<=n;j++)
{
int begin=n-1,c;
for(int c=j,k=Ht[j].parent;k!=0;c=k,k=Ht[k].parent)
{
if(Ht[k].lchild==c)
q[--begin]='0';
else
q[--begin]='1';
}
Hc[j]=new char[n-begin];
strcpy(Hc[j],&q[begin]);
}
delete q;
}
int main()
{
Hfmtree Ht;
Hfmcode Hc;
int a[102],n;
cout<<"输入节点的个数:";
cin>>n;
cout<<"输入每个节点的权值:";
for(int i=0;i<n;i++)
cin>>a[i];
HfmCodeing(Ht,Hc,a,n);
for(int i=1;i<=n;i++)
{
cout<<Ht[i].weight<<" ";
cout<<Hc[i]<<endl;
}
return 0;
} 代码运行结果
