is和==之间的区别
一、在讨论is和==之间的区别之前,先来看几个别的概念:
首先要知道Python中对象包含的三个基本要素,分别是:id(身份标识)、type(数据类型)和value(值)。
二、、变量,变量名,内存
变量:用来表识一块内存区域;我们操作变量,实际上是在操作内存地址空间;
变量名:是一个标识符(dientify),用来代之一块内存空间,使用这个变量名,我们可以很方便的操作这块内存区域。
内存:内存是我们电脑硬件,用来存放数据,形象的理解就是内存有一个一个的小格子组成,每个格子的大小是一个字节,每个格子可以存放一个字节大小的数据。我们如何才能知道,数据存放在哪些格子中,那就得靠地址,地址类似于楼房的门牌号,是内存的标识符。
三、id()
id()
id(object)函数是返回对象object在其生命周期内位于内存中的地址,id函数的参数类型是一个对象。

IS 比较的是两个对象的id值是否相等,也就是比较俩对象是否为同一个实例对象,是否指向同一个内存地址。
== 是一个判断的过程,所以==判断的是对象的内容是否相等。
默认会调用对象的__eq__()方法。
is比较id以及vlaue是否相同
示例一

我们可以看到的是,当a,b取值在257和-10得的时候,结果返回的是false,那么是为什么呢?
出于对性能的考虑,Python内部做了很多的优化工作,对于整数对象,Python把一些频繁使用的整数对象缓存起来,保存到一个叫small_ints的链表中,在Python的整个生命周期内,任何需要引用这些整数对象的地方,都不再重新创建新的对象,而是直接引用缓存中的对象。Python把这些可能频繁使用的整数对象规定在==范围[-5, 256]==之间的小对象放在small_ints中,但凡是需要用些小整数时,就从这里面取,不再去临时创建新的对象。因为257不再小整数范围内,因此尽管a和b的值是一样,但是他们在Python内部却是以两个独立的对象存在的,各自为政,互不干涉。
示例二

是的,上面出现了两个结果:
1、a is b 结果是false
2、c is b 结果是true
这个是为什么呢?
,代码块作为程序的一个最小基本单位来执行。一个模块文件、一个函数体、一个类、交互式命令中的单行代码都叫做一个代码块。
在上面这段代码中,由两个代码块构成,a = 257作为一个代码块,函数foo作为另外一个代码块。
Python内部为了将性能进一步的提高,凡是在一个代码块中创建的整数对象,如果存在一个值与其相同的对象于该代码块中了,那么就直接引用,否则创建一个新的对象出来。
Python出于对性能的考虑,但凡是不可变对象,在同一个代码块中的对象,只有是值相同的对象,就不会重复创建,而是直接引用已经存在的对象。因此,不仅是整数对象,还有字符串对象也遵循同样的原则。所以 c is b就理所当然的返回True了,而a 和b不在同一个代码块中,因此在Python内部创建了两个值都是257的对象。
结论
1、小整数对象[-5,256]是全局解释器范围内被重复使用,永远不会被GC回收。2、同一个代码块中的不可变对象,只要值是相等的就不会重复创建新的对象。
2:str:
只能判断全部由数字字母组成的字符串

字符串中单个20以内他们的内存地址一样,单个21以上,内存地址不一样


3:py文件
在一个py文件中,只要内容一样,内存就一样
==比较赋值是否相同

####### 下面这个例子就可以看出,is和==之间的去别,

==判断的是两个变量的值是否相等
但是==也会判断变量的类型是否相等。
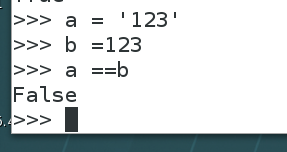
只有数值型和字符串型的情况下,a is b才为True,当a和b是列表,元组,字典,或集合型时,a is b为False
深浅拷贝
赋值
在python中,对象的赋值就是简单的对象引用
例:这里的b = a,就是b对a的一个引用,引用的是a的内存地址空间

浅拷贝
浅拷贝包含三种:
切片操作,工厂函数,copy模块中的copy函数
切片函数:list_b = list_a[:]
工厂函数:list_b = list(list_a)
copy模块中的copy函数:list_a = copy.copy(list_b)
浅拷贝之所以称为浅拷贝,是它仅仅只拷贝了一层


当我们查看变量a和变量b的内存,发现他们的内存地址空间已经发生了改变;
但是我们查看a和b中的具体元素,结果确是相同的
深拷贝
深拷贝只有一种形式,copy模块中的deepcopy函数。深拷贝就是数据完完全全独立拷贝出来一份。不会由原先数据变动而变动
a = copy.deepcopy(b)
如果变量是一个不可变的数据,那么就不区分深浅拷贝
列表生成式
什么是列表?
Python中用[]表示一个列表
快速生成一个列表可以用range()函数来生成。


如果相对对列表中的元素进行计算,并将计算结果以列表的形式打印出来该如何做呢?
方法一、

如果使用列表生成式应该怎么做呢?
方法二、其实就是将之前的外层循放在列表中进行,并且不用使用append追加;

列表生成式语法是固定的,[]里面for 前面是对列表里面数据的运算操作,后面跟平常for循序一样遍历去读取。运行后会自动生成新的列表
带if的判断
如果想对一个列表里面的数据筛选,比如:
a= [1,2,3,4,5,6,7,8,933,4,4,66,77,788,88,99]
找出大于5的数,按正常思维可以for循环挨个判断,符合条件的放到新的列表:
方法一、

方法二、
如果要求生生的列表中有多个参数?

generator列表生成器
生成的是一个对象,不会把数据直接创建出来,当for遍历的时候,生成器对象会调用next()函数,获取下一个要生成的数据
生成器对象可以调用next()函数,获取下一个要生成的数字,如果next()函数没有获取到下一个数据,会抛出异常 StopIteration,程序出错
生成器对象可以使用for遍历,使用next()不停地获取下一个数据,如果没有下一个数据循环结束

字典生成式
定义:
同列表生成式一样,字典生成式是用来快速生成字典的。通过直接使用一句代码来指定要生成字典的条件及内容,替换了使用多行条件或者是多行循环代码的传统方式。
格式:
{字典内容+循环条件+判断条件 [产生条件] }
习题一、
随机生成20位学生即其成绩,筛选并打印出90分以上的学生及其成绩。
思路:
1、先生成一个列表,存放20名学生的姓名已经对应成绩
2、在字典中判断value的值并比较大小,输出满足结果的值。
# _*_ coding: UTF-8 -*-
import random
a = {} ###定义一个空字典,将学生信息和分数输出到字典中
for i in range(1,21):
name = 'student' + str(i)
score = random.randint(60,100)
a[name] = score
#print (a)
hightscore = {}
for name,score in a.items():
if score > 90:
hightscore[name] = score
print (hightscore)
如果使用字典生成式,该如何写呢?

