Python Day 16 (正则表达式,部分模块讲解)
正则表达式
匹配字符串内容的一种规则,正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
元字符 |
匹配内容 |
| . | 匹配除换行符以外的任意字符 |
| \w | 匹配字母或数字或下划线 |
| \s | 匹配任意的空白符 |
| \d | 匹配数字 |
| \n | 匹配一个换行符 |
| \t | 匹配一个制表符 |
| \b | 匹配一个单词的结尾 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结尾 |
| \W | 匹配非字母或数字或下划线 |
| \D | 匹配非数字 |
| \S | 匹配非空白符 |
| a|b | 匹配字符a或字符b |
| () | 匹配括号内的表达式,也表示一个组 |
| [...] | 匹配字符组中的字符(字符集) |
| [^...] | 匹配除了字符组中字符的所有字符 |
量词:
量词 |
用法说明 |
| * | 重复零次或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
组合:
| 正则 | 说明用法 |
| \d+ | 一个或多个数字 |
| \d? | 零个或一个数字 |
| \d* | 零个或多个数字 |
惰性匹配
*? 重复任意次,但尽可能少重复
+? 重复1次或更多次,但尽可能少重复
?? 重复0次或1次,但尽可能少重复
{n,m}? 重复n到m次,但尽可能少重复
{n,}? 重复n次以上,但尽可能少重复
.*?的用法


. 是任意字符 * 是取 0 至 无限长度 ? 是非贪婪模式。 何在一起就是 取尽量少的任意字符,一般不会这么单独写,他大多用在: .*?x 就是取前面任意长度的字符,直到一个x出现
贪婪匹配
在满足匹配时,匹配尽可能长的字符串,默认情况下,采用贪婪匹配
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
| <.*> | <script>...<script> |
<script>...<script> | 默认为贪婪匹配模式,会匹配尽量长的字符串 |
| <.*?> | r'\d' | <script> |
加上?为将贪婪匹配模式转为非贪婪匹配模式,会匹配尽量短的字符串 |
分组 ()与 或 |[^]
正则表达式设置分组名
设置 (?P<组名>) 使用 (?P=组名) ret = re.search("<(?P<tag>\w+)>(\w+)</(?P=tag)>","<h1>hello</h1>") print(ret) print(ret.group()) print(ret.group('tag')) # ***abc*** # @@@abc@@@ # ==abc== # -123- ret = re.search('(?P<flag>.+).*(?P=flag)','-123-') print(ret.group()) ret = re.search('(.+).*\\1','-123-') print(ret.group())
转义符 \
在正则表达式中,有很多有特殊意义的是元字符,比如\d和\s等,如果要在正则中匹配正常的"\d"而不是"数字"就需要对"\"进行转义,变成'\\'。
在python中,无论是正则表达式,还是待匹配的内容,都是以字符串的形式出现的,在字符串中\也有特殊的含义,本身还需要转义。所以如果匹配一次"\d",字符串中要写成'\\d',那么正则里就要写成"\\\\d",这样就太麻烦了。这个时候我们就用到了r'\d'这个概念,此时的正则是r'\\d'就可以了。
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
| \d | \d | False | 因为在正则表达式中\是有特殊意义的字符,所以要匹配\d本身,用表达式\d无法匹配 |
| \\d | \d | True | 转义\之后变成\\,即可匹配 |
| "\\\\d" | '\\d' | True | 如果在python中,字符串中的'\'也需要转义,所以每一个字符串'\'又需要转义一次 |
| r'\\d' | r'\d' | True | 在字符串之前加r,让整个字符串不转义 |
模块
什么是模块?
常见的场景:一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀。
但其实import加载的模块分为四个通用类别:
1 使用python编写的代码(.py文件)
2 已被编译为共享库或DLL的C或C++扩展
3 包好一组模块的包
4 使用C编写并链接到python解释器的内置模块
为何要使用模块?
如果你退出python解释器然后重新进入,那么你之前定义的函数或者变量都将丢失,因此我们通常将程序写到文件中以便永久保存下来,需要时就通过python test.py方式去执行,此时test.py被称为脚本script。
随着程序的发展,功能越来越多,为了方便管理,我们通常将程序分成一个个的文件,这样做程序的结构更清晰,方便管理。这时我们不仅仅可以把这些文件当做脚本去执行,还可以把他们当做模块来导入到其他的模块中,实现了功能的重复利用,
模块的种类(三种)
内置模块
扩展模块(pip等方法进行安装)
自定义模块
re模块-----的常用方法
import re
三种常用的查找方法:
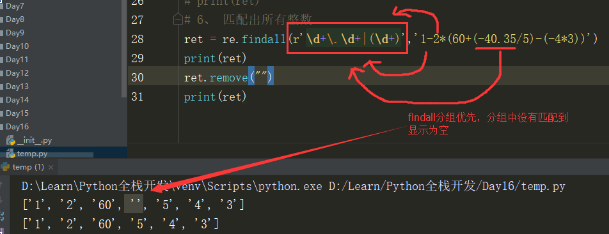
re.findall() 1、返回一个列表 2、分组匹配时,分组优先于正常匹配
ret = re.findall('\d+','321aa123bb1') print(ret) ================= ['321', '123', '1'] # 返回所有满足匹配条件的结果,放在列表里
import re ret = re.findall('www.(baidu|oldboy).com', 'www.oldboy.com') print(ret) # ['oldboy'] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可 ret = re.findall('www.(?:baidu|oldboy).com', 'www.oldboy.com') # ?: 取消分组优先 print(ret) # ['www.oldboy.com']
re.search() 不会直接返回结果,返回一个对象,使用group查看,且只会返回一个结果(类似index查找索引),使用group时最好进行判断是否有值,如果没有值会返回None
ret = re.search(r'[a-zA-Z0-9_-]+','[email protected]') print(ret) print(ret.group()) ============ <_sre.SRE_Match object; span=(0, 5), match='baidu'> baidu
re.match() 只从头开始匹配,返回第一个匹配到的。其他与search一样
ret = re.match('\d+','321aa123bb1') print(ret) print(ret.group()) ========================= <_sre.SRE_Match object; span=(0, 3), match='321'> 321 效果等于: ret2 = re.match('^\d+','321aa123bb1') print(ret2) print(ret2.group()) ================================== <_sre.SRE_Match object; span=(0, 3), match='321'> 321
re.split() 1、根据正则表达式进行切分。2、分组拆分保留匹配的项
ret = re.split("\d+","eva3egon4yuan") print(ret) ['eva', 'egon', 'yuan'] ============================= ret2 = re.split("(\d+)","eva3egon4yuan") print(ret2) ['eva', '3', 'egon', '4', 'yuan'] #使用分组切分时,split保留匹配的项,在某些需要保留匹配部分的使用过程是非常重要的。
re模块-----其他方法
ret = re.sub('\d', 'H', 'eva3egon4yuan4', 1)#将数字替换成'H',参数1表示只替换1个 print(ret) #evaHegon4yuan4 ret = re.subn('\d', 'H', 'eva3egon4yuan4')#将数字替换成'H',返回元组(替换的结果,替换了多少次) print(ret) obj = re.compile('\d{3}') #将正则表达式编译成为一个 正则表达式对象,规则要匹配的是3个数字 ret = obj.search('abc123eeee') #正则表达式对象调用search,参数为待匹配的字符串 print(ret.group()) #结果 : 123 import re ret = re.finditer('\d', 'ds3sy4784a') #finditer返回一个存放匹配结果的迭代器 print(ret) # <callable_iterator object at 0x10195f940> print(next(ret).group()) #查看第一个结果 print(next(ret).group()) #查看第二个结果 print([i.group() for i in ret]) #查看剩余的左右结果
collections模块
在内置数据类型(dict、list、set、tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter、deque、defaultdict、namedtuple和OrderedDict等。
1.namedtuple: 生成可以使用名字来访问元素内容的tuple
from collections import namedtuple struct_time = namedtuple('tuple_time',('year','month','mday','hour','min','sec', 'yday','wday')) # 定义一个type类型, 设置类似format格式化的容器型数据类型(list,tuple都可以) t1 = struct_time(2018,5,21,17,28,20,107,1) t2 = struct_time(2018,5,22,17,28,20,108,2) print(t2.yday-t1.yday) #比起直接使用元组,显示更加直观。
2.deque: 双端队列,可以快速的从另外一侧追加和推出对象
使用list存储数据时,按索引访问元素很快,但是插入和删除元素就很慢了,因为list是线性存储,数据量大的时候,插入和删除效率很低。
deque是为了高效实现插入和删除操作的双向列表,适合用于队列和栈
deque除了实现list的append()和pop()外,还支持appendleft()和popleft(),这样就可以非常高效地往头部添加或删除元素。
import queue # 并发编程 # 数据容器 —— list dict tuple # 秩序 单向 先进先出 FIFO —— 队列 q = queue.Queue() # 创建队列 q.put(1) q.put(2) q.put('a') q.put([1,23]) print(q) # 黑盒 数据不可见 —— print(q.get()) print(q.get()) #可以使用列表模拟现象,但是列表内存机制中删除第0个索引,其他数据索引位置 #都需要改变,不适合使用。
=========================== from collections import deque dq = deque() dq.append(1) #默认加在右 dq.append(2) dq.append(3) dq.appendleft('a') #加在左 print(dq) print(dq.pop()) #从右删除 print(dq) print(dq.popleft()) #从左删除 print(dq) #数据可见===
3.Counter: 计数器,主要用来计数
Counter类的目的是用来跟踪值出现的次数。它是一个无序的容器类型,以字典的键值对形式存储,其中元素作为key,其计数作为value。计数值可以是任意的Interger(包括0和负数)。Counter类和其他语言的bags或multisets很相似。
c = Counter('abcdeabcdabcaba') print c 输出:Counter({'a': 5, 'b': 4, 'c': 3, 'd': 2, 'e': 1})
4.OrderedDict: 有序字典
使用dict时,Key是无序的。在对dict做迭代时,我们无法确定Key的顺序。如果要保持Key的顺序,可以用OrderedDict
OrderedDict的Key会按照插入的顺序排列,不是Key本身排序
dict从无序变为有序需要耗费更多的内存来存储位置关系,根据不同的情况时间换空间 ,空间换时间 (对时间要求,和对资源有限制的不同情况)
d = dict([('a', 1), ('b', 2), ('c', 3)]) print(d) from collections import OrderedDict odic = OrderedDict([('a', 1), ('b', 2), ('c', 3)]) # print(odic) odic['z'] = 26 print(odic) #dict从无序变为有序需要耗费更多的内存来存储位置关系,根据不同的情况时间换空间 ,空间换时间 (对时间要求,和对资源有限制的不同情况)
5.defaultdict: 带有默认值的字典
有如下值集合 [11,22,33,44,55,66,77,88,99,90...],将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中。
即: {
'k1'
: 大于
66
,
'k2'
: 小于
66
},处理这种问题时可以使用此方法,查询后会自动添加key。
from collections import defaultdict values = [11, 22, 33,44,55,66,77,88,99,90] my_dict = defaultdict(list) for value in values: if value>66: my_dict['k1'].append(value) else: my_dict['k2'].append(value) defaultdict字典解决方法
from collections import defaultdict
ddic = defaultdict(lambda : 5) #设置这个字典的默认的value是一个列表
print(ddic)
print('-->',ddic['a'])
print(ddic)
#查询后此方法会自动添加一个key,可以使用lambda设置value
=====================
defaultdict(<function <lambda> at 0x00000190A1531E18>, {})
--> 5
defaultdict(<function <lambda> at 0x00000190A1531E18>, {'a': 5})