这学期学校开了数据挖掘这门课,然后花了几天时间Python入门,老师不打算讲爬虫这一块,自己对爬虫一直挺感兴趣,想了解一下,所以用了两天简单的学了一下爬虫,做了一个小demo
目标网站: http://www.paoshu8.com/0_7
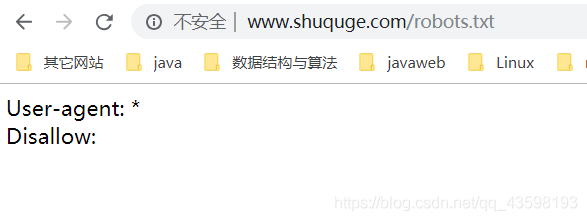
看了目标网站的robots协议就可以放心的爬了吧,别爬太快,给别人服务器造成太大负担
分析:
1.先用requests库的get方法请求该目标网站,从响应体可以获取到目标网站的网页源代码(如果请求失败,建议加上User-Agent)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
}
response = requests.get(url, headers=headers)
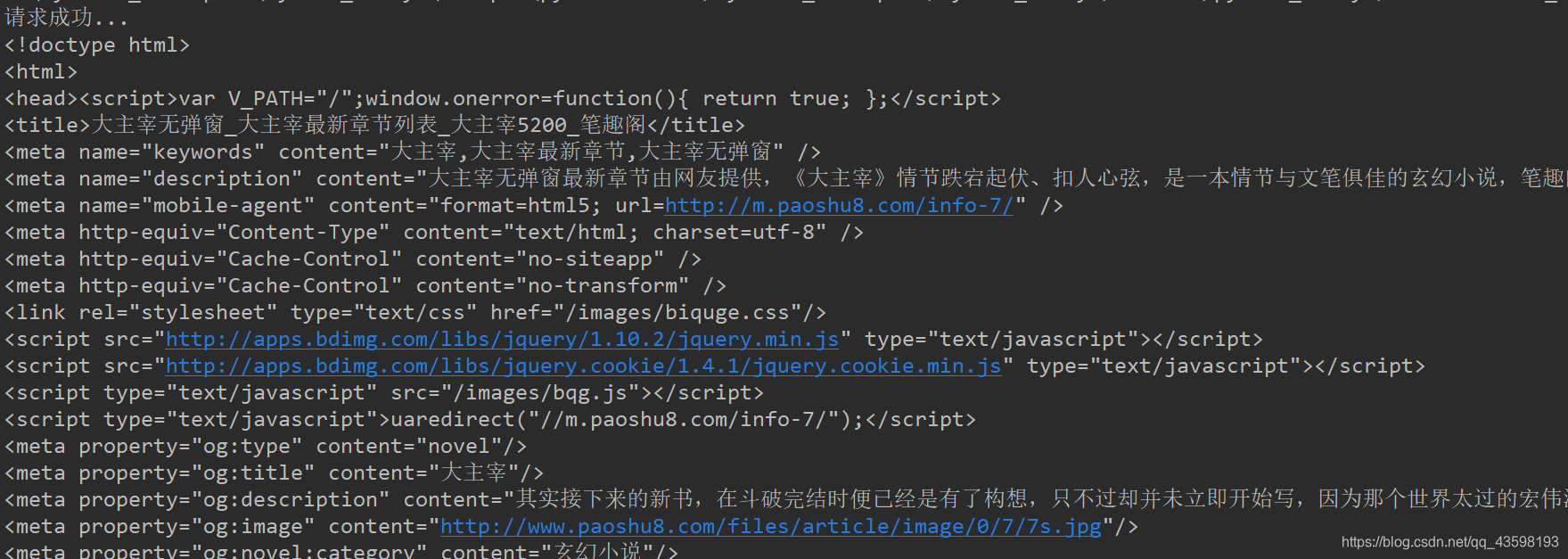
2.通过下面的图可以发现,目标网站将所有的章节和链接都套在dd标签里的a标签中,可以用正则将所有章节和章节链接都匹配出来放到列表中(当然,处理方法有很多种,如beautifulsoup、xpath、re…自己熟悉哪种便用哪种)
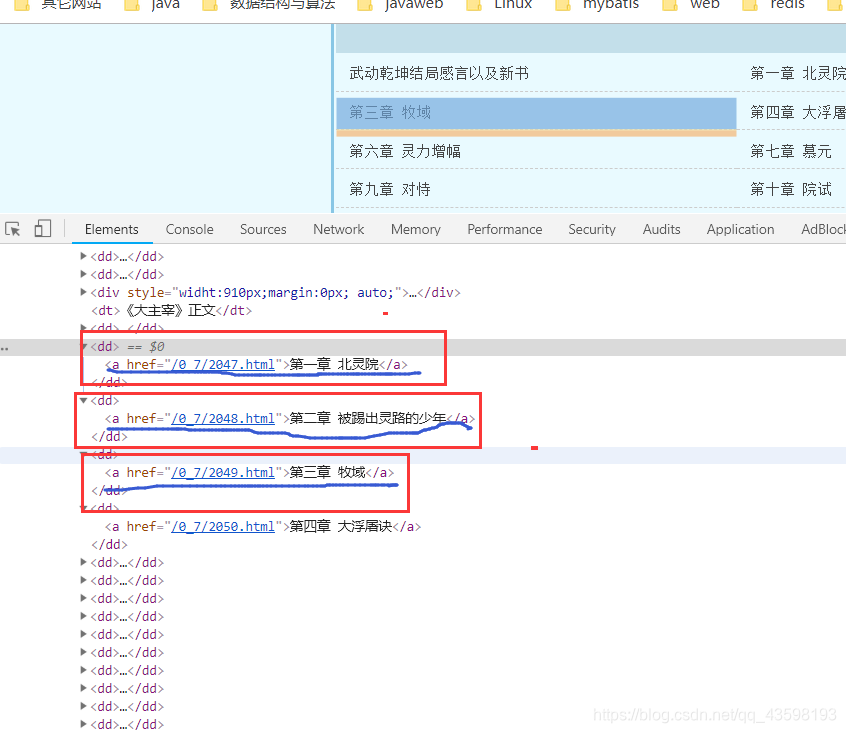
# 这是匹配所有章节的链接和章节名的正则表达式
<dd>.*?href="(.{14,19}?)">(第.*?)</a></dd>
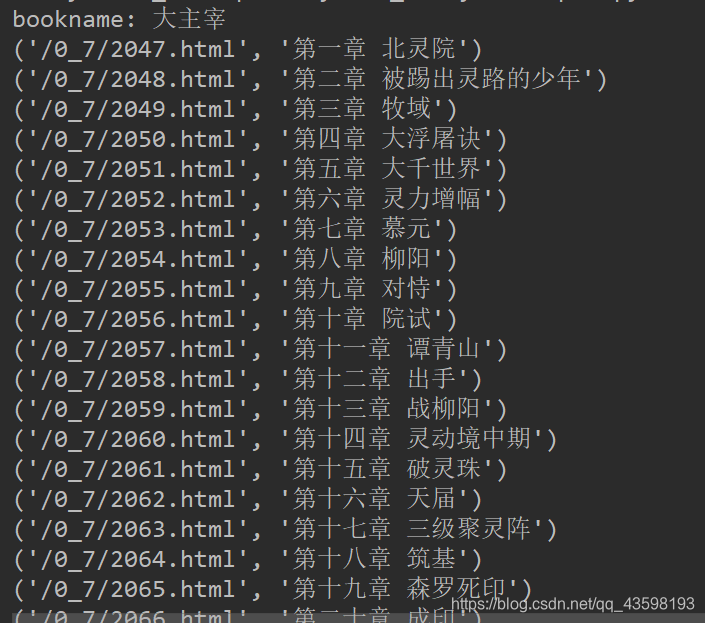
对表达式进行测试(可以看到匹配条数一致,大致的看了一下,基本没问题,可以进行下一步了)
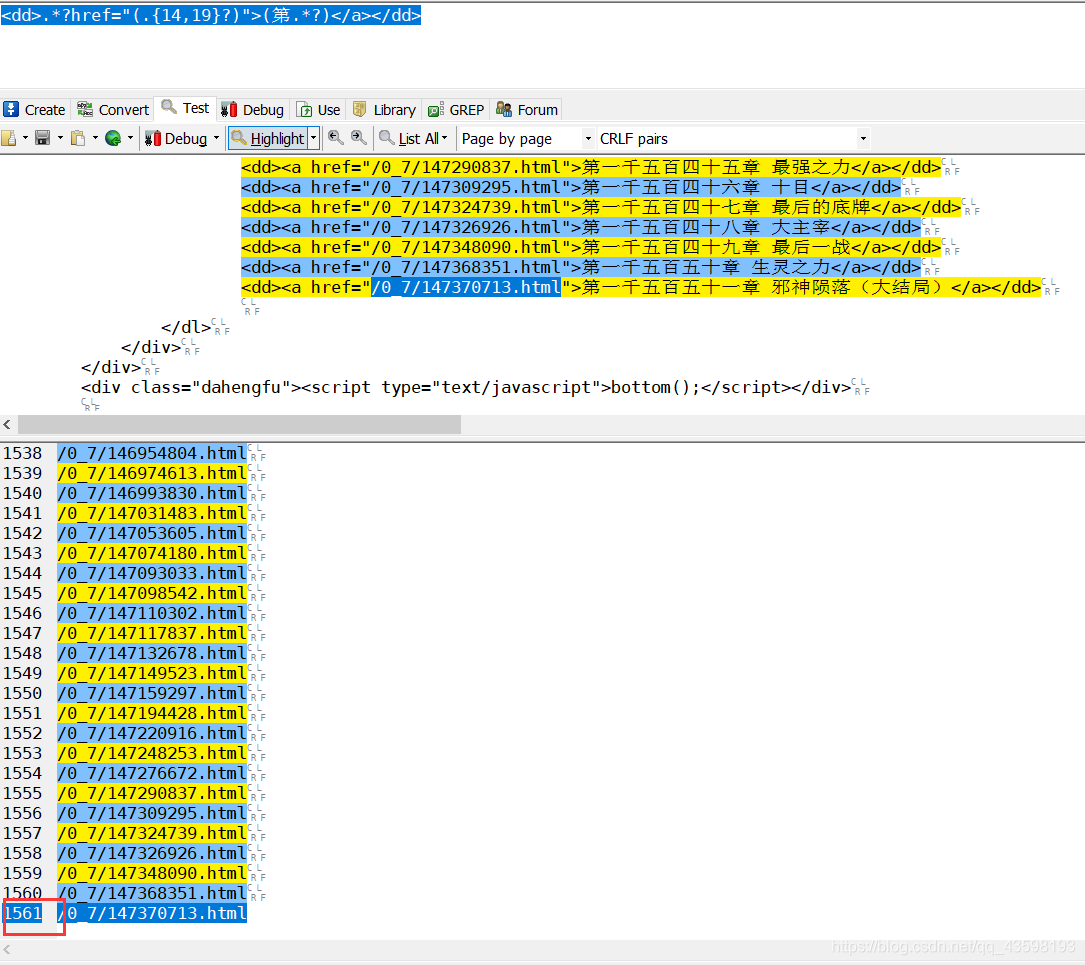

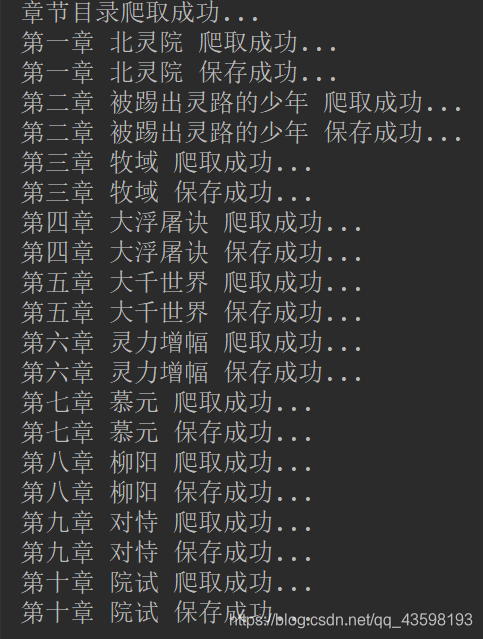
控制台打印:
3.处理完所有章节和链接,接下来就是爬取一章里的内容,再次用requests库里的get方法请求一章,然后处理返回来的网页源代码,又可以用正则匹配提取出内容,这1000多章小说都可以这样处理,所以可以写个循环,利用第二步获取的所有章节的链接作为请求url(因为不是完整的url,所以前面需要加上http://www.paoshu8.com,这样拼接后才是完整的url),循环获取,也可以用multiprocessing模块实现多线程提高速度
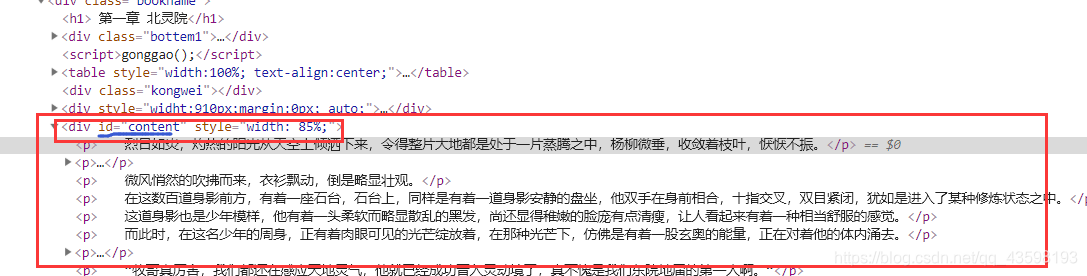
# 这是匹配文章内容的正则表达式
.*?id="content">(.*?)</div>
对表达式进行测试: 发现内容中有p标签,需要去除p标签
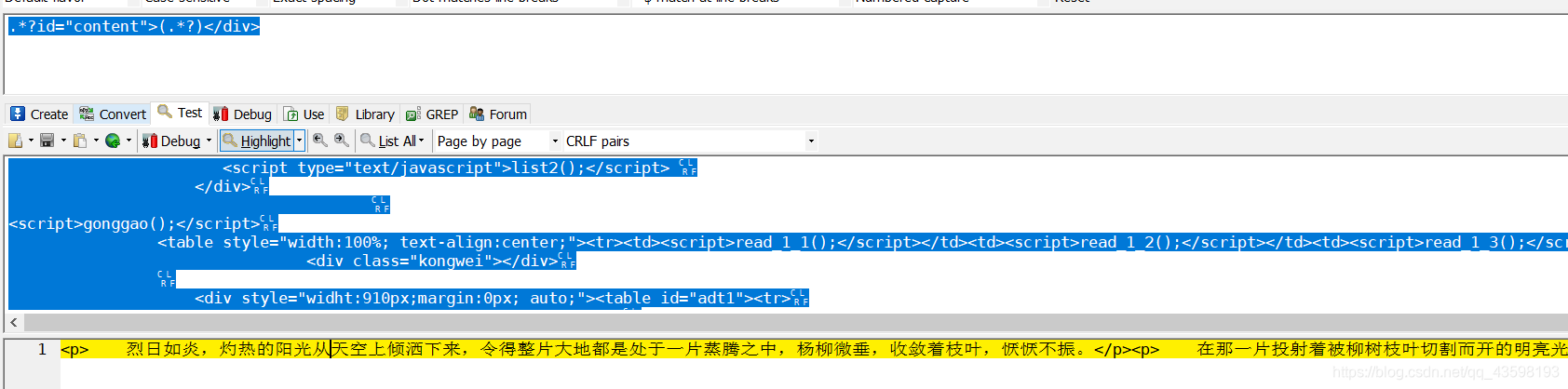
去除p标签
# 这是去除p标签的正则表达式
<p>(.*?)</p>
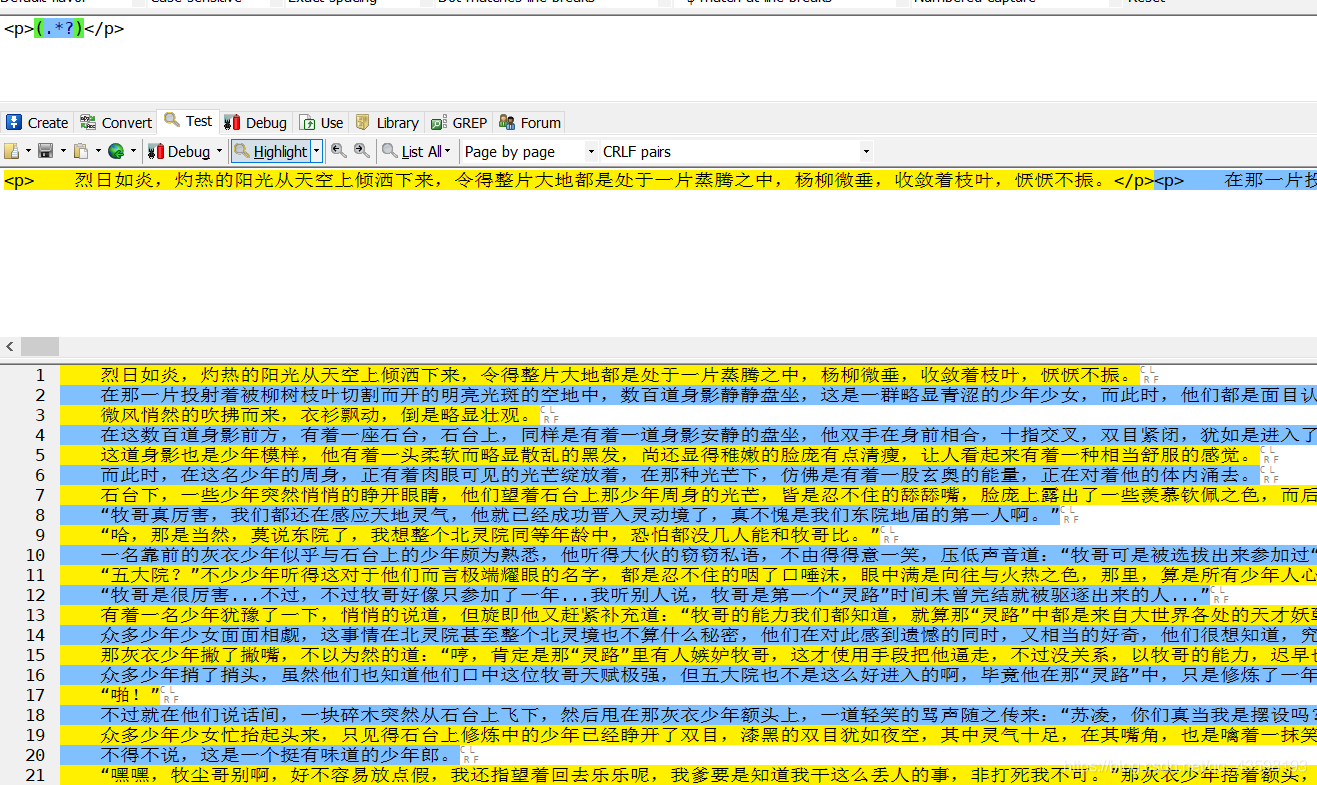
但是呢,处理完p标签后输出获取的章节内容和列表,又发现列表内容中出现了\u3000(这是Unicode的全角空白符),但是显示内容确实是正常的,如果想进行处理,可以参考python去除\ufeff、\xa0、\u3000(这里我没进行处理,保存的文件也是正常显示的)

4.接下来就是将小说内容一章一章写入文件中,这一步在处理每一章内容的时候就可以一起实现
代码:
import os
import requests
import re
# 请求所有章节
def request_all_chapter(url):
"""请求所有指定url上的所有章节"""
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200: # 如果状态码为200,请求成功
# response.encoding = response.apparent_encoding # 如果乱码加上
print('章节目录爬取成功...')
return response.text
except requests.RequestException:
print("章节目录爬取失败...")
# 解析请求的html并提取出所有章节
def get_all_chapter(html):
"""提取出书名和所有章节目录"""
re_bookname = r'.*?book_name"\s+content="(.*?)"/>' # 提取书名
re_chapters = '<dd>.*?href="(.{14,19}?)">(第.*?)</a></dd>' # 提取所有章节名和链接
global book_name # 定义全局变量
book_name = re.search(re_bookname, html).group(1)
# 提取的章节名和链接返回的是一个列表,列表里的元素是元组,每个元组都有两个元素,分别为链接和章节名
book_chapters = re.findall(re_chapters, html)
return book_chapters
# 请求一章的内容
def request_one_chaptercontent(url, chapter_url, chapter):
"""
:param url: 要请求章节的前部分url
:param chapter_url: 要请求章节的后部分url
:param chapter: 要请求章节的章节名
:return: 该章的网页源代码
"""
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
}
response = requests.get(url+chapter_url, headers=headers)
if response.status_code == 200:
print(chapter, "爬取成功...")
return response.text
except requests.RequestException:
print(chapter, "爬取成功...")
# 解析请求的一章html并提取出章节内容处理后写入文件中
def get_one_chaptercontent(chapter_html, chapter, path):
"""
解析返回来的网页源代码,从中提取小说内容并作出处理然后写入文件中
:param chapter_html: 该章的网页源代码
:param chapter: 要请求章节的章节名
:param path: 保存的路径
"""
reg1 = '.*?id="content">(.*?)</div>' # 提取内容的正则表达式
reg2 = '<p>(.*?)</p>' # 取出掉p标签的正则表达式
content = re.search(reg1, chapter_html).group(1) # 提取出的内容(列表)
content = re.findall(reg2, content) # 去掉了p标签的内容(列表)
# 将列表转为字符串 每个元素后加换行
content = '\n'.join(content)
# 写入文件中
write_to_file(content, chapter, path)
# 将小说写入到文件中
def write_to_file(content, chapter, path):
"""
:param content: 存放小说内容的列表
:param chapter: 章节名
:param path: 保存的路径
"""
try:
with open(path, 'a', encoding='utf-8') as f:
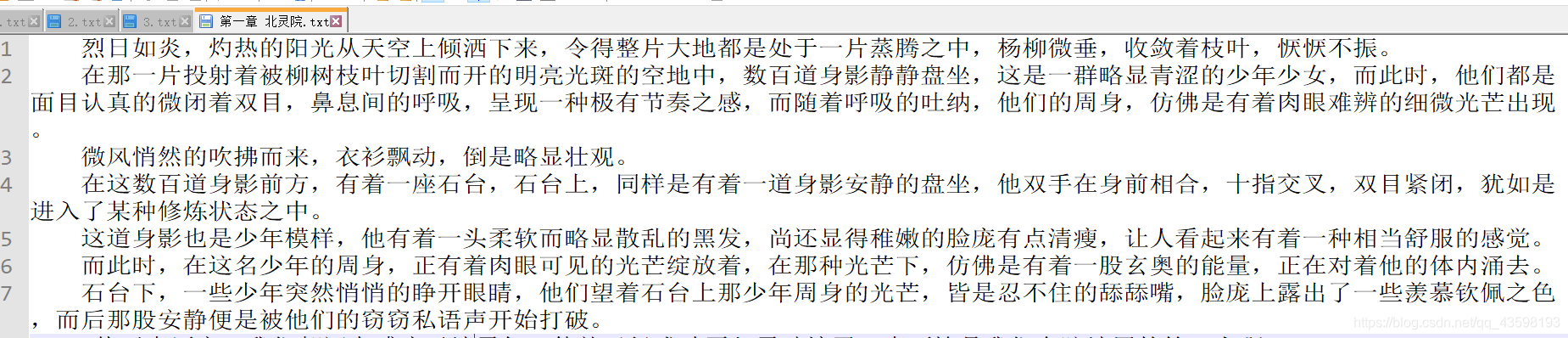
f.write(content)
print(chapter, '保存成功...')
except FileNotFoundError:
print(chapter, "写入失败")
if __name__ == '__main__':
# 爬取小说目录
url = 'http://www.paoshu8.com/0_7'
html = request_all_chapter(url)
chapters = get_all_chapter(html)
# 根据书名创建保存所有章节的文件夹
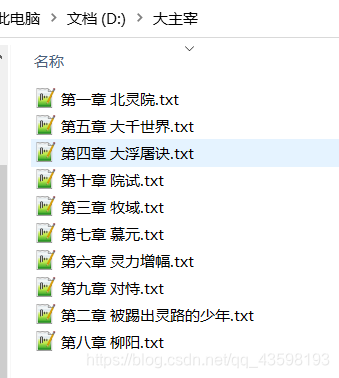
save_path = 'D:/'+book_name
if not os.path.exists(save_path): # 路径不存在则创建
os.mkdir(save_path)
# 爬取前10章小说
for i in range(0, 10):
chapter_html = request_one_chaptercontent('http://www.paoshu8.com', chapters[i][0], chapters[i][1])
path = save_path+'/'+chapters[i][1]+'.txt' # 保存小说章节的路径
get_one_chaptercontent(chapter_html, chapters[i][1], path)
结果:
以上就是简单的爬虫小demo的全过程了,是不是很有趣?虽然用正则有缺陷,但毕竟是娱乐嘛,快去试试吧
