一个特定的库函数往往包含很多内容,看函数原型和大佬的代码对新手(比如我)都不太友好,入门的时候我们不需要对一个库的所有内容都了如指掌,理解一些基础的、可能会用到的函数会更容易上手(当然这篇博客也是我的备忘录)。
**
requests 常用于请求url并获取响应
**
先看一段简单的代码
response = requests.get(url = 'https://www.baidu.com')
调用requests库,使用get的方法,获取一个url的响应。
**什么是响应?**可以类比打开文件的方法:
with open('小说.txt',mode = 'r',encoding = 'utf-8') as fp:
text = fp.read()
用只读的方式打开文本“小说.txt”,并用变量名fp接收,但fp不是文本里的内容,而是一个句柄,如果要调用文件里的内容,就需要对句柄使用read(),所以这里的句柄可以理解为一个身份标识符,告诉我们fp指向的是这个文本,而不是那个文本。
响应也是,一个网页包含的不仅仅是我们看到的内容(通常经过渲染),为了获取网页中各种类别的信息,我们就需要得到一个响应,并对这个响应进行后续操作(如同对fp进行read一样):
打印响应response
<Response [200]>
返回2开头的响应代表访问成功,3开头代表跳转,4开头代表页面不存在,5开头表示服务器存在问题
获取html
html = response.text
结果
<!DOCTYPE html>
<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=https://ss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/cache/bdorz/baidu.min.css><title>ç™¾åº¦ä¸€ä¸‹ï¼Œä½ å°±çŸ¥é“</title></head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus=autofocus></span><span class="bg s_btn_wr"><input type=submit id=su value=百度一下 class="bg s_btn" autofocus></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>æ–°é—»</a> <a href=https://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href=http://map.baidu.com name=tj_trmap class=mnav>地图</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>视频</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>è´´å§</a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>登录</a> </noscript> <script>document.write('<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u='+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">登录</a>');
</script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">更多产å“</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>å
³äºŽç™¾åº¦</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>使用百度å‰å¿
读</a> <a href=http://jianyi.baidu.com/ class=cp-feedback>æ„è§å馈</a> 京ICPè¯030173å· <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>
(可以用pprint库里的pprint函数让html打印的更美观)
注意到这里出现了乱码,可以
获取该url对应的编码:
response.encoding = response.apparent_encoding
没错,就是让响应的编码等于响应适合的编码…有些万能,只要加上这句,就不会出现乱码。
打印后得到utf-8,说明该网站用的编码类型为utf-8
utf-8
.text获取的是文本信息,有的网站对应的是图片或视频,要用.content获取bytes型数据。
没什么用的响应头
response.headers
请求头
response.request.headers
#返回字典类型
{
'User-Agent': 'python-requests/2.23.0',
'Accept-Encoding': 'gzip, deflate',
'Accept': '*/*', 'Connection': 'keep-alive'
}
代表请求方以什么名义访问网站,通常我们会模拟电脑浏览器去请求网站获取数据,如果不加“伪装”,如上’User-Agent’: ‘python-requests/2.23.0’,有些网站会识别你是用python的requests函数在访问,会将你拦截。我们可以通过检查网络获取浏览器的请求头:

把这些请求头以字典类型赋值给headers,并放进requests.get()函数中。
如果要实现翻页、寻找关键词,还需在requests.get()函数中加入params(parameters)参数,这些参数也需要在网页的检查中找到规律,这里涉及到网页的分析。
综上,
相对完整的get函数应用
应该是这样的:
url = 'https://www.lagou.com'
cookie_str = 'user_trace_token=20200307173509-f0662195-c030-41f9-b5f7-6147804e3342; LGUID=20200307173509-eb75ce03-9be9-4b9d-a381-f9631afd1267; _ga=GA1.2.1098617662.1583573707; _gid=GA1.2.62312670.1583573707; index_location_city=%E5%85%A8%E5%9B%BD; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%22170b459469f40d-0aa2d28c714e58-47744716-2073600-170b45946a03c0%22%2C%22%24device_id%22%3A%22170b459469f40d-0aa2d28c714e58-47744716-2073600-170b45946a03c0%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%7D; LGSID=20200308152904-a3a74cd2-3ddd-48a9-ad71-d8567d0fbea8; PRE_UTM=m_cf_cpc_baidu_pc; PRE_HOST=www.baidu.com; PRE_SITE=https%3A%2F%2Fwww.baidu.com%2Fbaidu.php%3Fsc.Ks00000EAMrnlPLIyEELfVriNMD46xEM03rN7UHxHEXwzr3k506s%5Fh6ZycnozLOL66ZKU1zTvB0p-dWN%5FODHi1qyUi6%5F29UFCdcWYCxMD8DWoe2Qre4C-2Li2riBInG1IXtPXy5c6WqinsBeqzvlBps-cJPZpnZthztx0ReTCjZlDDrClwnYC1l19uxJHWFNpygF3LnV85D6cs1dfiyaD5ZubB28.DD%5FNR2Ar5Od663rj6tJQrGvKD77h24SU5WudF6ksswGuh9J4qt7jHzk8sHfGmYt%5FrE-9kstVerQKz33X8M-eXKBqM764mTT5Qx-4IY5u3er1-LlthiAE-sSxH9vX8ZuEsSXej%5FqT5o4JN9h9merMkotN.U1Yk0ZDqs2v4%5FsKspynqn0KsTv-MUWY3nAf3PyDzPH6zPjcLPH7-PWNbPHm3ujF-mhfvn1P-mfKY5TaV8Uf0pyYqnWcd0ATqTZPYT6KdpHdBmy-bIfKspyfqnW00mv-b5HTz0AdY5HDsnH-xnW0vn-tknjc1g1nvnjD0pvbqn0KzIjYYn160uy-b5HnsrHTYg1DYPWKxnWDsrHKxn103Pj7xn103nWwxn10LnHT0mhbqnHRdg1Ddr7tznjwxnWDL0AdW5HDsnj7xnHfkn1TYnWmvPHFxnNts0Z7spyfqn0Kkmv-b5H00ThIYmyTqn0K9mWYsg100ugFM5Hc0TZ0qn0K8IM0qna3snj0snj0sn0KVIZ0qn0KbuAqs5H00ThCqn0KbugmqTAn0uMfqn0KspjYs0Aq15H00mMTqn6K8IjYs0ZPl5fK9TdqGuAnqTZnVmLf0pywW5R9affKYIgnqn1TkPWnsrj6vrH0LPjR4nHm4nfKzug7Y5HDdrjnvPHcdn1cLrjf0Tv-b5H6zuhuBmWnYnj0snj6kPAD0mLPV5HPAPW9DwDcdPW6LwbwKfbc0mynqnfKsUWYs0Z7VIjYs0Z7VT1Ys0Aw-I7qWTADqn0KlIjYs0AdWgvuzUvYqn7tsg1Kxn0Kbmy4dmhNxTAk9Uh-bT1Ysg1Kxn7ts0ZK9I7qhUA7M5H00uAPGujYs0ANYpyfqQHD0mgPsmvnqn0KdTA-8mvnqn0KkUymqn0KhmLNY5H00pgPWUjYs0ZGsUZN15H00mywhUA7M5HD0UAuW5H00uAPWujY0mhwGujYLfRR3fHw7rHb4PbDdwRRYrHRdnWDsnbDknWKAwbD4fsKEm1Yk0AFY5H00ULfqnfKETMKY5HcWnan1c1cWPWD3nWR4rH6WnW0snanznj0sQW0snj0snankc1cWn0KkgLmqna3LP-tsQW0sg108njKxna33r7tsQWDdg108n100ug9Y5H00mLFW5HmdnjTs%26word%3D%25E6%258B%2589%25E9%2592%25A9%26ck%3D6892.6.72.349.148.196.420.314%26shh%3Dwww.baidu.com%26sht%3Dbaidu%26us%3D1.0.1.0.1.301.0%26bc%3D110101; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2Flanding-page%2Fpc%2Fsearch.html%3Futm%5Fsource%3Dm%5Fcf%5Fcpc%5Fbaidu%5Fpc%26m%5Fkw%3Dbaidu%5Fcpc%5Fbj%5F5c4784%5F9f22c1%5F%25E6%258B%2589%25E5%258B%25BE%26bd%5Fvid%3D12834347947470636669; JSESSIONID=ABAAAECAAFDAAEH2360E5BA7189F787D9AB999F2C97A7E1; WEBTJ-ID=20200308152935-170b90c97f125c-0ad97a1cc2fe8b-47744716-2073600-170b90c97f25c3; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1583573707,1583652537,1583652555,1583652575; TG-TRACK-CODE=index_search; X_HTTP_TOKEN=89964421b05c60454633563851929384a9452e47b4; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1583653365; LGRID=20200308154244-08ac649a-e015-471a-b75f-c953546ece51; SEARCH_ID=d392f3b8cf3c4764a8eff7d3fb71f8da'
headers = {
#请求的主机地址
'Host': 'www.lagou.com',
#原始网页
'Origin': 'https://www.lagou.com',
#上次请求的是哪个网页
'Referer': 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=',
# 用户代理
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400',
# 身份
'cookie' : cookie_str,
}
params = {
'needAddtionalResult': 'false',
}
response = requests.get(url = url,headers = headers,params = params)
当然,有些网站会有简单的反扒机制,即你所看到的数据并不在主网站上,而是通过XHR接口传输的,因此去爬主网站得不到想要的数据,而是要通过xhr接口去找,凡是xhr接口网站,返回的都是json数据,一般采用post方式获取响应,所谓post,浏览器在请求的同时需要返回一个字典类型表单才能获取响应:
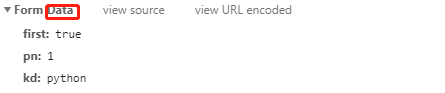
因此
post方法
比get要多设置一个data参数:
json = {
'first': 'true',
'pn': '1',
'kd': 'python',
}
response = requests.post(url = url,headers = headers,params = params,data = json)
除了GET和POST函数,requests内置的方法还有OPTIONS、HEAD、PATCH、PUT、DELETE
那怎么区分一个网站要通过什么方式获取响应呢?
在网站的检查里有:

以上就是requests库函数的最基本应用,欢迎指正。
