我想通过对两个DFS例子的剖析,来加深自己对DFS的学习和理解,有错误之处,不吝指教。
1. 组合
组合DFS的代码来自:https://blog.csdn.net/Mr_Zhangmc/article/details/81940805
组合的题目如下:(题目来自codeup:ID:100000608,问题B)略有改动(去除非递归要求)
排列与组合是常用的数学方法,其中组合就是从n个元素中抽出r个元素(不分顺序且r < = n),我们可以简单地将n个元素理解为自然数1,2,…,n,从中任取r个数。例如n = 5 ,r = 3 ,所有组合为:
1 2 3
1 2 4
1 2 5
1 3 4
1 3 5
1 4 5
2 3 4
2 3 5
2 4 5
3 4 5
#include<iostream>
using namespace std;
const int Max=100;
int n,r;
int num[Max]={0};
//当达到边界时,
void DFS(int index,int count){
//没啥含义,只是为了更好的解析
cout<<"**"<<index<<" "<<count<<" "<<endl;
//记录
num[count]=index;
//边界,当有r个元素的时候,已到边界值
if(count==r){
//从num[1]~num[r]是暂存的数据
for(int i=1;i<=r;i++){
cout<<num[i]<<" ";
}
cout<<endl;
return;
}
//以1 ~ n-r开头的所有组合相加就是所求的组合
//从首字符分别是从index+1~n
for(int i=index+1;i<=n;i++){
DFS(i,count+1);
}
}
int main(){
cin>>n>>r;
DFS(0,0);
return 0;
}
输入n=5,r=3后的运行结果如下:
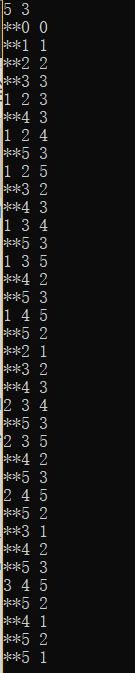
将其图示化,流程图如下:

由上图可知,当DFS(1,1)时(即深蓝色箭头指入虚框内),历经了虚框内的循环后,箭头指到了DFS(2,1)(即深蓝色箭头指出虚框),然后DFS(2,1)以绿色箭头指入虚框,经历虚框内的流程,指出到DFS(3,1),一直到DFS(5,1)结束循环。
这就对应着:
void DFS(int index,int count){
//代码省略
...
//以1 ~ n-r开头的所有组合相加就是所求的组合
//从首字符分别是从index+1~n
for(int i=index+1;i<=n;i++){
DFS(i,count+1);
}
}
当index=0,count=0时,最外面一层有5次DFS即DFS(1,1), DFS(2,1), DFS(3,1), DFS(4,1), DFS(5,1)。
然后进入DFS(1,1)的内递归,经历虚框内的流程后,返回到DFS(2,1),一直到DFS(5,1),最后结束。
void DFS(int index,int count){
//没啥含义,只是为了更好的解析
cout<<"**"<<index<<" "<<count<<" "<<endl;
//记录
num[count]=index;
//边界,当有r个元素的时候,已到边界值
if(count==r){
//从num[1]~num[r]是暂存的数据
for(int i=1;i<=r;i++){
cout<<num[i]<<" ";
}
cout<<endl;
return;
}
//代码省略
...
}
由于每一次递归都会将当前访问的数据保存下来,count是当前index在num数组中所处的位置,当达到递归边界时即抽出的元素count已经达到题目要求的r=3时,num数组中已经存在所要求的内容,输出即可。
2. 全排序
题目:(简略表达)输入n(小于21的正整数),给出1~n的全排列
#include<cstdio>
using namespace std;
const int Max=11;
int n;
//存储排序元素
int per[Max]={0};
//标记对应元素是否已经参与排序,true已经参与,false未参与
bool hashTable[Max]={false};
//递归实现DFS
void DFS(int index){
//如果已参加排列的个数到达n ,即达到边界
if(index==n+1){
//将其输出
for(int i=1;i<=n;i++){
if(i!= n){
printf("%d ",per[i]);
} else {
printf("%d\n",per[i]);
return;
}
}
}
//n个数的全排列=1~n开头的所有排列的和
for(int i=1;i<=n;i++){
//判断是否已经参与排序
if(!hashTable[i]){
//将当前参与排序的元素暂存至per
per[index]=i;
//置使用标记为true
hashTable[i]=true;
//安排下一个位置
DFS(index+1);
//将当前位置元素的标志位置为false,以便下一轮使用
hashTable[i]=false;
}
}
}
int main(){
while(scanf("%d",&n)!=EOF){
DFS(1);
}
return 0;
}
运行结果如下:
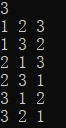
运行流程图如下:

由上图可以看出,从DFS(1)=1开始,此时待递归的是DFS(1)同层的DFS(1)=2, DFS(1)=3。然后DFS(1)=1继续递归深入,到达DFS(2)层,此时DFS(2)=2或3,选择DFS(2)=2,进入下一层,DFS(3)仅剩最后一个元素可选即DFS(3)=3,然后继续下一层,DFS(4)到达递归边界,输出并返回。
每返回一层,将对应该层的元素的标志位hashTable[i]置为false,以便下一次递归继续使用。当DFS(2)=2选择完毕,而且由于在上上一层递归时,hashTable[3]已经在使用过后设置为false,可以继续使用,因此DFS(2)=3,然后扫描hashTable[1~n],那个元素对应的标志位为false,那就使用哪个。直至递归边界,然后返回并将对应的标志位置false,返回到DFS(1)=1时,进入DFS(1)=2的递归,同时hashTable[1]=false。
DFS(1)=2的递归过程和DFS(1)=1的递归过程类似,不再赘述。
3.总结归纳
上两道题,说白了就是有这么一个数组num[1~n], 把n个数填入num数组。在全排序中,num[1]可填的元素有n个,而num[2]可填的元素有n-1个,num[3]有n-2个…num[n]可填的元素有1个。
上两道题的区别在于能否重复利用之前已经使用过的元素,全排序增加了一个标志位数组hashTable[Max]以表示元素的使用情况,每一次递归都扫描1~ n,可以利用之前的元素。而组合是每一次递归从当前index+1~ n,选不到之前的元素,只能从比当前元素大的元素序列中选择。
DFS的可能模板形式:
//具体的参数需要分析题目设计
//index 表示元素编号
//other 表示可能的其他形参
void DFS(int index,{int other}){
//如果达到递归边界
if(递归边界){
//输出内容
}
//进入下一次递归式
//分支路口即进入下一层的路口
DFS(index+1,{other});
}
