文章目录
一、什么是正则表达式
正则表达式,又称规则表达式,是一个用来检索(也称匹配)和替换(本质还是检索)符合特定规则的文本
工作中最常见的莫过于一下几个情况:
- 校验用户名
- 校验密码
- 校验手机号
- 校验邮箱格式
- 校验域名
- 解析URL
- 匹配某个字段
…不胜枚举,正所谓,没学不知道,学了不会用的就是正则表达式了,上述几个问题会在最后解答。很多之前学习过的,在工作中也是不敢放开使用,希望大家能够在读文本文,彻底的学会在工作中使用正则表达式。
二、常用工具
很方便的正则表达式图形化界面
虽然有点问题,但是不影响学习
三、开始学习啦
3.1 开始第一个正则表达式——我是谁
/nb/ 即两个斜杠加中间的表达式构成,这里的表达式是nb这两个字母构成的字符串
在regexper中如下

这是一个用来匹配“nb”的这个字符串的表达式,看起来很简单吧,他会匹配
- nb123
- 1nb23
- 123nb
…
3.1.1 非打印字符
这个表达式是由字符构成,咱们这个字符都比较简单,就是普通的打印字符,它的意思就是这个字符的意思就是能够打印出来的字符,同时也就以为这肯定有非打印字符,也不多,如下:

上面这些非打印字符怎么用呢,如下
/\n/
直接用,哈哈,就是这么简单。
3.1.2 特殊字符
这里还有一些特殊的原字符(上面的也是,只不过我们是按照功能进行区分了),我们称为特殊字符,特殊字符存在的意义就是来简化我们的表达式,增加可读性和可操作性。

特殊字符中国呢需要注意几点:
- ()这个功能和js中一样,很nb,子表达式可以供后者调用,样例看下方
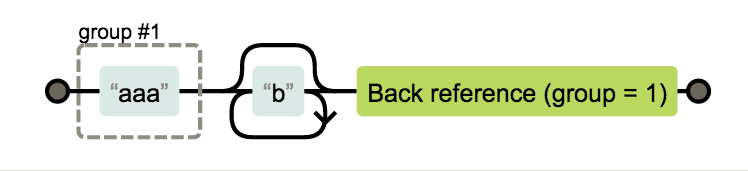
- \num 这个功能也很nb,需要配合()使用,例如 :
/(aaa)b*\1/ 这里的\1就是指aaa,下图可以看到,有个reference,即对group1的引用
3. 因为上面的操作带来一个问题,\nm会有歧义,比如 \34,这是表示什么意思,是指对于group = 34还是 group = 3的引用
a)这个意思如果是nm,在前面有nm个集合,那就会表示对第nm个group的引用
b)如果前面没有nm个,但是有大于n个,那就像下面一样

c)那如果连n个都没有呢,就会变成\nm对应的nm字符
需要注意一点,分享的regexper里面对于这个的展示有点问题,我自己试了好久就是不符合预期,如下demo

工具展示的是对于group1的引用,我实际测试是对于12,所以上面的逻辑是对的,还是要多动手丫

作为初学者,我之前是犯过一个错误的,手贱的给这个表达式加个 “”,比如 “/nb/”,这只是一个字符串,正则表达式是一个表达式,所以千万不能多此一举。
3.2 定位符——我在哪
我们知道要去匹配谁了,但是要匹配哪一个字符呢,比如:
/nb/
“nb123nb”
如上,目标字符串里面出现了两次nb,是挺nb的,我们上面的表达式只能去匹配到第一个nb,这样看起来很不nb丫,所以就需要接下来另一个概念,定位符(按道理来讲,匹配条件都是来限定位置的,只不过定位符是来限制一些通用的位置匹配):

看着比较简单吧,我们在挨个看一下:
1. ^
// /^nb/.test("nb123nb") true
// /^nb/.test(" nb123nb") false 我在居首加了一个空格,就是导致没办法匹配啦
2. $
// /nb$/.test("123nb") true
// /nb$/.test("123nb ") false
3. \b
// /\bnb/.test("12 nb") true
// /\bnb/.test("12 nb") false
4. \B
// /\bnb/.test("12 nb") false
// /\bnb/.test("12 nb") true
3.3 限定符——限定次数
很多时候,比如我要匹配手机号的时候,会发现这是1开头11位数字,如果我们直接匹配数字[0-9],需要写10次,那我们是不是可以把一些连续重复出现的正则规则用字符表示它出现的次数,来简化我们的工作呢:

这样会很大程度的来简化我们的工作:
[0-9]* //表示任意多个数字
[0-9]+ // >=1个数字
其中需要注意的是:*, + 都是贪婪模式,意思就是尽可能多的匹配,如果需要非贪婪模式,在这些之后加上?,比如:
/a*/ 、 /a+/
对于字符串 “aaaaaaa”,他们总是想尽可能的匹配更多的字符,最终只会匹配出一个结果,即整个字符串
如果我只想匹配第一个满足的结果,即一个a即可
/a*?/、/a+?/ 这样就只会匹配出“a” 啦
3.4 匹配规则
今天先到这,之后补充
