Hive简介
学习Hive之前得先学习hdfs和mr,当学完mr之后会发现,操作数据还是很麻烦,首先得具备一定的开发能力,还得对mr的原理有一定的了解才能写出对应的代码得到想要的结果,效率确实有点低下,不利于hadoop的发展,后来大神们就搞出了一套像写sql一样操作hdfs数据的分布式计算框架Hive。
Hive不是数据库,更像是数据仓库,因为本质是HDFS+MR,所以它具备了HDFS的所有缺点,比如:不适合应用于实时系统、不能对行集数据进行增删改操作、用于处理离线批处理数据等。
Hive是一套实现了类SQL的接口
Hive的HQL和MySQL的SQL非常类似,很多命令都是通用的,比如创建数据库、创建表、查询、修改表结构等
Hive安装
从apache官方网站http://mirrors.shu.edu.cn/apache/hive/下载想要的版本,我下的1.2.2
在虚拟机中可以使用如下命令下载压缩包
wget http://mirrors.shu.edu.cn/apache/hive/hive-1.2.2/apache-hive-1.2.2-bin.tar.gz
解压出来
tar -xf apache-hive-1.2.2-bin.tar.gz
改一下文件目录名称(个人喜好)
mv apche-hive-1.2.2-bin apache-hive-1.2.2
安装JDK
这个就不详细写了,大概描述一下过程
1.下载jdk
2.解压
3.在/etc/profile中配置环境变量
4.使环境变量生效
source /etc/profile
安装mysql
参考MySQL安装与主从配置 的前半部分
在mysql中创建hive数据库
mysql -uroot -p12340101
mysql>create database hive character set latin1;//记住一定要将字符集设置为latin1,否则Hive不能正常工作
hive目前支持derby和mysql来存储元数据,默认也是derby,但是它非常不好用,建议大家不要偷懒,还是装一个MYSQL然后配置一下URL、USERNAME、PASSWORD就OK
配置Hive
进入到Hive的安装目录
cd conf
cp hive-default.xml.template hive-site.xml
vi hive-site.xml
将如下内容粘贴到Hive中
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop00:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>12340101</value>
<description>password to use against metastore database</description>
</property>
</configuration>将mysql-connector-java-5.1.32.jar(mysql的驱动包)复制到Hive安装目录下的lib中
启动Hive
进入到Hive安装目录的bin目录下
./hive
![]()
创建一个数据库

到eclipse可视化界面中查看hdfs结构上的变化
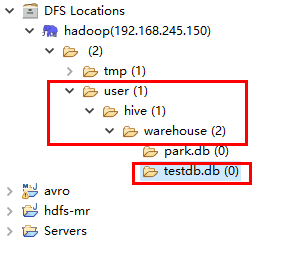
可以看到创建一个数据库,就是在user/hive/warehouse下面新建了一个testdb.db的目录
再看看创建一个表
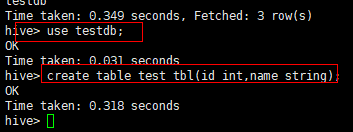
像mysql一样,得先选一个数据库,然后才能进行操作。
再看看hdfs里面的变化

可以看到一张表也是新增了一个目录,然后大家应该可以想到数据,最终在hdfs就是一个最小的单位文件了。
在Hive中加载文件数据

numFiles=1说明可以再添加更多的文件

截图证明了上面的猜测。
总结:Hive提供的HQL,本质上是执行的HDFS命令或者MR程序。数据利用文件存储,其他逻辑概念都是用目录实现,比如数据库、表、分区、分桶等
注:上面命令都还只是为了说明Hive实现原理,如果使用select * from test_tbl查不出来数据,只有所有值为NULL的行,因为还没有告诉Hive数据文件的分隔符是什么,Hive不知道如何做分析并做出映射。
