Mnist数据集介绍以及载入
- mnist手写数据集,共55000个训练样本,5000个验证样本以及10000个测试样本
-
载入代码可如上所述,即利用tf中的mnist模块,利用其中的read_data_sets方法,并注意读取数据时以独热编码的形式读入;上述代码中还有一些打印信息,用以显示相关数据维度尺寸,具体见注释。import tensorflow as tf import tensorflow.examples.tutorials.mnist.input_data as input_data import matplotlib.pyplot as plt import numpy as np # 数据载入 mnist = input_data.read_data_sets("MNIST/", one_hot=True) # 以独热编码的形式载入数据 # 训练集训练数据,验证集评估调参,测试集进行最后的测试 print("训练集数量: ", mnist.train.num_examples) print("验证集数量: ", mnist.validation.num_examples) print("测试集数量: ", mnist.test.num_examples) # 可以解开注释,看里面的数据形式 # print("图像形状:", mnist.train.images.shape) # 784即28X28 # print("标签形状:", mnist.train.labels.shape) # print("首图尺寸:", mnist.train.images[0].shape) # print("首图内容:", mnist.train.images[0].reshape(28, 28)) - 对于独热编码的解释:所谓独热编码就是以数组的形式编码,并且此数组中有且只有一个1,其余值均为0;可以利用这句代码print(mnist.labels[1])打印实现,在mnits数据集中,若以独热编码载入数据时,标签值将会是一个独热的一维数组;由于mnist识别时,判断准确程度是基于类似于欧式距离的思路,所以使用独热编码更易于计算差异。
数据集的划分
构建模型并进行训练的最终目的是,可以对于未知的数据进行尽可能准确地预测;为保证有效的预测,需将数据集分成数据集、测试集、验证集。
整体的训练为: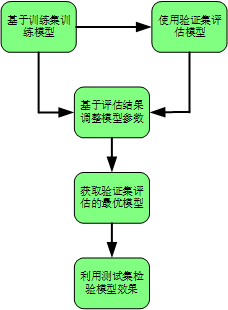
并且,为保证测试集上的效果可以很好的拟合对于位置数据的验证效果,就要求:测试集数目够大以及不到最后模型不要接触测试集,并且测试集与训练集要对于数据的整体上的分布描述一致。
在mnist数据集中,官方已经划分好了训练集、测试集以及验证集。
批量读取数据
- 可利用python中的切片语句,实现数据的批量提取;如print(mnist.train.labels[0:10]),来批量打印显示索引0到9的样本对应的标签值。
- mnist数据包,在tf中,提供了一个可以批量读入数据的方法,
即next_batch;其参数包为读入数据的量(batch_size),返回值包括图像集合与对应的标签集合;通过打印语句,得到的图像集合的维度为[10,784],标签集合的维度为[10,10]。# mnist中提供了下述方法,可以进行批量读取数据 batch_images_xs, batch_labels_ys = mnist.train.next_batch(batch_size=10) print(batch_images_xs.shape, batch_images_ys.shape)
构建模型
-
定义输入、权重以及前向计算。对于输入的维度,只限定尺寸不限定数目,用NONE进行占位,便于与批量读取数据配合;权重w一边随机初始化,但注意维度要对应,即可与x做矩阵乘法,b一般直接初始化为0;前向计算就是定义了一个矩阵乘法在加上偏移量的计算过程,对于计算后的结果要使用softmax将计算值映射到概率域,这种映射在cnn中也经常使用,多用于最后一个FC层。x = tf.placeholder(tf.float32, [None, 784], name="X") y = tf.placeholder(tf.float32, [None, 10], name="Y") w = tf.Variable(tf.random_normal([784, 10]), name="W") b = tf.Variable(tf.zeros([10]), name="b") forward = tf.matmul(x, w)+b # 前向计算 preb = tf.nn.softmax(forward) # 利用softmax进行结果向概率域的映射 - 对于softmax补充说明:此方法对应于计算得到的各类标签的得分值大小,对应的赋予一个概率值,使得总的概率值之和为1,得分高的类别对应的概率值大,具体公式为
,其中C表示类数。
-
定义超参数,如上所示。设置一次读100个样本做单次训练,一轮训练要做total_batch次的单次训练,总共要训练50轮。# 超参设置 train_epochs = 50 # 训练轮数 batch_size = 100 # 单批次训练样本数 total_batch = int(mnist.train.num_examples/batch_size) # 一轮训练要训练的批次数 learing_rate = 0.01 # 学习率 display_step = 1 # 显示粒度 -
设定损失函数,对于多分类问题,常使用交叉熵损失函数;交叉熵本来是在信息领域比较概率的近似程度,在使用独热编码后,对于softmax映射的计算结果与标签值之间的差异,就是概率差异;交叉熵的计算公式为# 定义损失函数 # 交叉熵损失函数 loss_fuction = tf.reduce_mean(-tf.reduce_sum(y*tf.log(preb), reduction_indices=1)),其中p是标签值,q是经softmax映射后的计算值,二者越接近,交叉熵值越小。
-
定义优化;仍使用梯度下降算法,多分类问题使用L2算法做loss_function的时候,梯度下降算法可能会陷入局部极小,而使用交叉损失将避免这一问题。# 优化器 optimizer = tf.train.GradientDescentOptimizer(learing_rate).minimize(loss_fuction) -
定义准确率操作,即计算一次训练中的正确率;correct_prediction表示,首先预测值集合与标签值集合分布逐行取最大值所在的索引,因为一行对应一个样本,之后诸项比较得到的索引值,相同True否则False;accuracy是将True与False集合转化为float32类型,在将所有元素求均值,均值结果即为准确率。# 定义准确率 correct_prediction = tf.equal(tf.argmax(preb, 1), tf.argmax(y, 1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
训练与评估模型
-
训练模型,代码如所述。# 声明会话以及初始化变量 sess = tf.Session() init = tf.global_variables_initializer() sess.run(init) # 开始训练 print("Train Start !!!!!") for epoch in range(train_epochs): # 逐轮次 for batch_size in range(total_batch): # 共进行total_batch次的单一批次训练 xs, ys = mnist.train.next_batch(batch_size) # zip数据送入feed,此时类型已经符合 sess.run(optimizer, feed_dict={x: xs, y: ys}) # 运行迭代优化器 # 运行一个l轮后,利用验证即求解损失与准确度 loss, acc = sess.run([loss_fuction, accuracy], feed_dict={x: mnist.validation.images,y:mnist.validation.labels}) # 打印本轮训练结果 if(epoch+1) % display_step == 0: print("Train Epoch: ",'%02d'%(epoch+1), "Loss: ", "{:.9f}".format(loss), "Accuracy: ", "{:.4f}".format(acc)) print("Train Finish !!!!!") -
辅助函数,用以显示抽取到的图片、标签值以及预测值。# 测试结果可视化函数 def plot_images_labels_prediction(images, # 图像列表 labels, # 标签列表 prediction, # 预测值列表 index, # 所显示的第一张图的索引值 num=10 # 显示的图像数目 ): fig = plt.gcf() # 获取当前图表 fig.set_size_inches(10, 12) # 设置总图尺寸为10英寸X12英寸 if num > 25: # 限制总的显示数目不超过25张 num = 25 for i in range(0, num): # 逐个处理子图 ax = plt.subplot(5, 5, i+1) ax.imshow(np.reshape(images[index], (28, 28)), cmap='binary') title = "label="+str(np.argmax(labels[index])) if len(prediction) > 0: title += ",Prediction=" + str(prediction[index]) ax.set_title(title, fontsize=10) ax.set_xticks([]) ax.set_yticks([]) index += 1 plt.show() -
利用模型检测,并可视化。# 一次检测所有test样本 prediction_result = sess.run(tf.argmax(preb, 1), feed_dict={x: mnist.test.images}) # 打印前十个检测结果 print(prediction_result[:10]) # 可视化前10个检测结果 plot_images_labels_prediction(mnist.test.images, mnist.test.labels, prediction_result, 10, 10)  检测结果如上所述。
检测结果如上所述。
