Looking Fast and Slow: Memory-Guided Mobile Video Object Detection
(一)论文地址:
https://arxiv.org/pdf/1903.10172.pdf
(二)核心思想:
本文讨论了,在计算机视觉系统中使用记忆模型是否可以提高视频流中目标检测的准确性,以及是否可以减少计算时间;
作者通过将传统的特征提取器(Slow Network),与只需要识别场景主旨的轻量级特征提取器(Fast Network)交叉使用,证明了在存在时间记忆模型的情况下,如何实现计算量最少的精确检测,并在手机等移动设备上实现了实时检测;
此外,作者还证明记忆模型包含足够的上下文信息,可以用来部署强化学习演算法来学习自适应推论策略;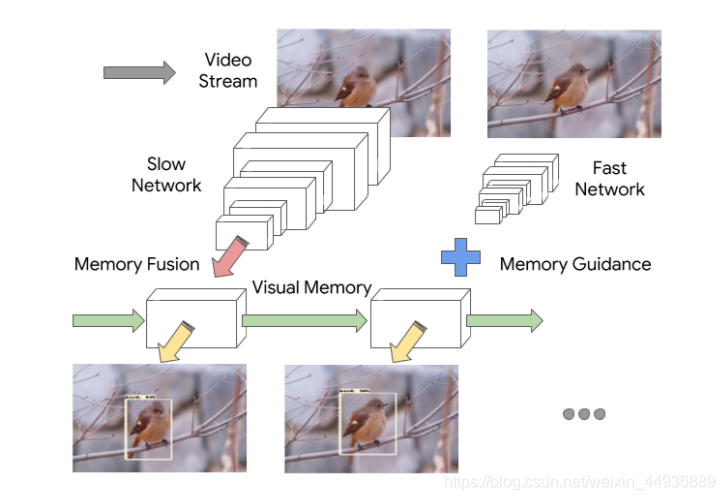
(三)主要贡献:
这篇文章的主要贡献有:
• 提出了一个内存引导的交叉框架,其中多个特征提取器在不同的帧上运行,以减少冗余计算,它们的输出使用一个公共内存模块进行融合;
• 引入了一个自适应交叉策略,其中执行特征提取器的顺序是使用 Q-learning(强化学习)得到的,这导致了一个非常好的速度/精度权衡;
• 在移动设备上演示了迄今为止已知的最快的、高精度的视频检测模型;
(四)Interleaved Models(交叉模型):
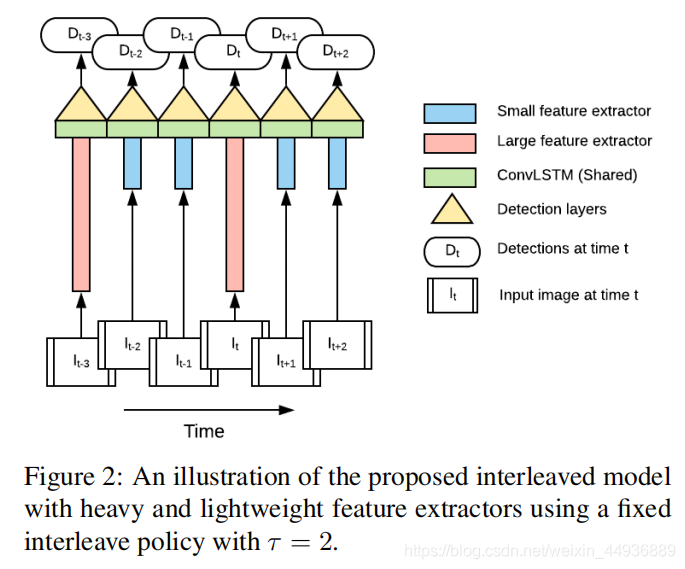

假设输入视频为 ,并且当检测到第 帧时,只有 是已知的;
假设 个特征提取器为 ,代表了从图像空间到各自的特征空间 的映射;
假设记忆模型为 ,代表了从 和内部状态表示到公共的、细化的特征空间的映射,同时输出更新的状态;
然后使用类似 SSD 风格的检测器,假设为 ,输出最后的检测结果;
这样第 帧图像 的最终结果 就可以表示为:
,其中 , 是时序模型在 时刻的状态量;
使用交叉模型的优点是:
- 不同的特征提取器可以对不同的图像特征进行专门化处理,从而产生时间上的综合效果;
- 轻量级特征提取器大大减小了计算成本;
在研究中作者使用了两个特征提取器 ,即 ,其中 致力于提高检测的精度,而 致力于提高检测的速度;
两个特征提取器的交替策略可以很简单地用一个参数 表示,即在 运行 次后运行 ;
当然作者还提出了一个更有效的方法,在下面我们会详细地讲一下;
(五)Backbone(主干网络):
两个提取器的 Backbone 作者都采用了标准的 MobileNetV2 网络,详解可以看我这一篇博客:
【论文阅读笔记】:Inverted Residuals and Linear Bottlenecks: Mobile Networks for Classifification, Detection and Segmentation
其中:
的深度乘子为 1.4、输入分辨率为 320×320;
的深度乘子为 0.35、输入分辨率为 160×160;
并且作者将 的最后一个下采样的步长改为 1,从而使得输出的特征层跟 大小一致;
并且作者也将预选框的比率调整为 ,从而减小计算量;
(六)Memory Module(记忆模块):
记忆模块的作用是跨时间步聚合来自两个提取器的特性,特别是使用时间上下文信息来增强来自小网络的特性;
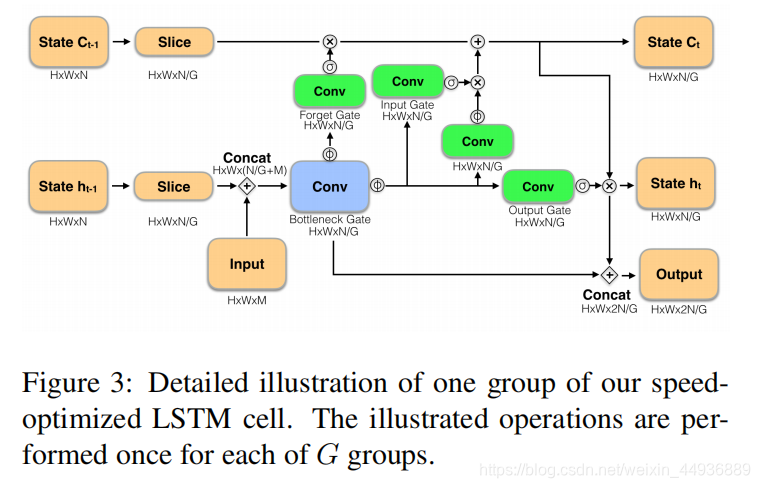
为了提高传统 ConvSTLM 的检测速度,作者主要做了以下改进:
- 采用了一种瓶颈结构,在瓶颈和输出之间增加了一个跳跃连接,使瓶颈成为输出的一部分;
- 将LSTM状态分成组,并使用分组的卷积分别处理每个状态;
假设第 时刻前的状体量为 , 时刻输入的特征图为 ;
首先将状态量按照通道划分为 个相等的分区 ,再将这 个分区分别与 相连接,输出瓶颈结构 LSTM 的门 ;
LSTM 的新的状态量 也通过同样的方法计算(注意这里没有聚合,依然是分组的形式);
最后使用一个跳跃连接结构连接生成输出组:
最后在通道维度上将他们链接,就得到了 ;
其中分组的卷积通过稀疏化层连接提供了加速,跳跃连接结构允许在输出中包含较少的临时相关特征,而不需要存储在内存中;
研究中作者采用了
,channels 数为
,带来的速度提升还是比较明显的:

作者还发现,LSTM 中的输入和遗忘门的 sigmoid 激活很少完全饱和,会导致长期依赖项逐渐丢失的缓慢状态衰减;
为了解决这个问题,作者提出了一个简单的方法:运行 时跳过状态更新,即重复利用 的状态量;
(七)Training Procedure(训练过程):
训练过程包括两个阶段;
首先在 ImageNet 上预训练交替模型,来为 LSTM 获取一个比较好的初始化权重;
由于 ImageNet 是单张图片的分类任务,这里作者将每一张图片复制三次,并将 LSTM 展开为三个步骤,每一步随机选取一个特征提取器;
然后再用 SSD 的目标检测任务的训练方法,将 LSTM 展开为六个步骤,通过裁剪图片的特定区域来模拟视频中的平移和缩放;
(八)Adaptive Interleaving Policy(自适应交替策略):
(我没看懂,,,这里就简介一下吧,,,)
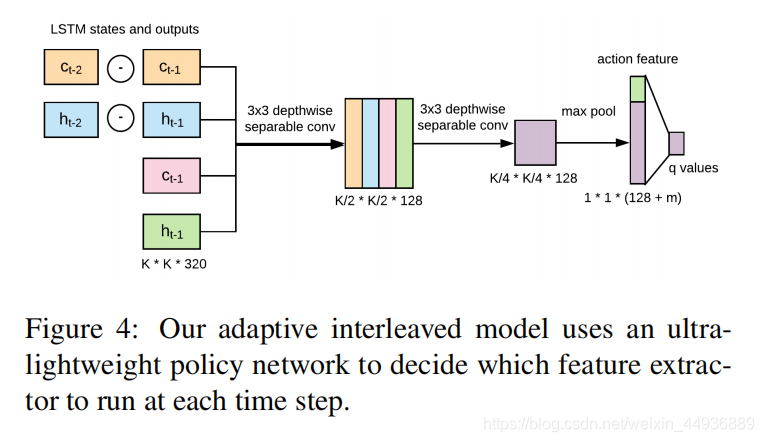
这里作者提供了一个使用强化学习来优化交替策略的方法;
作者构建一个策略网络 检查 LSTM 的运行状态和输出下一功能;
然后,利用 DDQN 对策略网络进行训练,算法如图:

(我是看不懂了,,,最近补一下强化学习)
(九)Inference Optimizations(推理优化):
这里作者探索了两个针对实际应用的额外优化,这两个优化使帧率提高了三倍,同时保持了准确性和部署的方便性;
9.1 Asynchronous Inference(异步推理):
基于关键帧的检测方法的一个问题是,它们只考虑平摊运行时,然而由于这些方法在关键帧上执行大部分计算,因此帧之间的延迟是极不一致的;
因此作者提出了一个异步推理的策略:
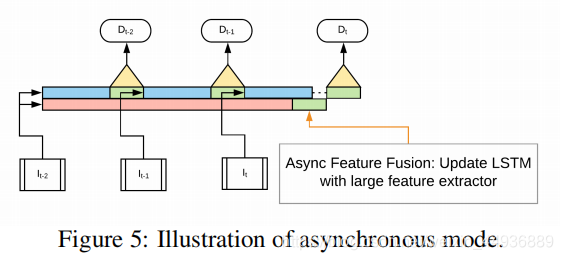
当以同步方式运行交错模型时,每一步都会运行一个特征提取器,因此最大潜在延迟取决于
;
然而,通过在单独的线程中运行特性提取器(称之为异步模式),这个过程很容易并行化;
在异步模式下,每一步都运行 ,专用于生成检测,而 则继续每 帧运行一次并更新状态量;
轻量级的特征提取器在每一步则使用最新可用的内存,不再需要等待更大的特征提取器运行;
9.2 Quantization(量化):
作者提出,对于 LSTM,在所有数学运算(加法、乘法、sigmoid 和 ReLU6)之后,可以插入伪量化操作;
即将激活后的范围,对于 sigmoid 固定为 [0,1],对于 ReLU6 固定为 [0,6],以确保连接操作的所有输入的范围是相同的,以消除重新排序的需要;
(十)实验结果: